
CNN
image processing의 하나의 기법으로 Convolutional neural network이다.
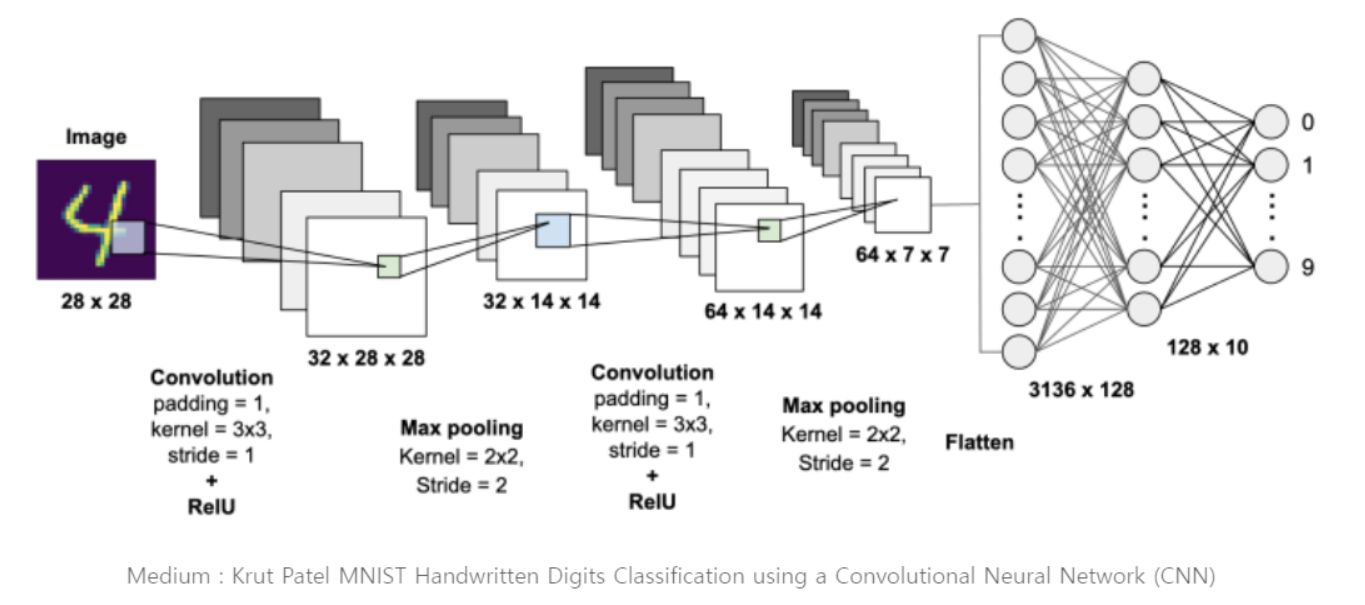
딥러닝에서는 데이터의 shape이 중요하기 때문에 각각의 Layer를 지날 때 shape이 어떻게 변하는 지를 잘 확인하여야 한다.
CNN에서 Output의 Shape는 아래와 같다.

이 공식과 위에 있는 Layer들을 확인해 보며, shape를 보면 공부에 도움이 된다.
VGG & ResNet
VGG
VGG는 CNN을 여러겹 겹쳐서 모델을 구성한 것이다.
하지만 layer의 수를 늘려서 성능을 높혔지만 layer를 증가시킬 수록 모델의 학습시간이 증가하는 문제가 있다. 또한, layer의 수가 충분히 많아지면 그 이상 layer를 증가시켜도 성능이 크게 변하지 않는 구간이 발생한다.
ResNet
ResNet은 단순히 layer를 늘리는 것이 아닌 새로운 기법을 추가하였다. 입력 데이터를 출력 데이터를 내보내기 전에 추가하여 연산에 변화를 주는 것이다.
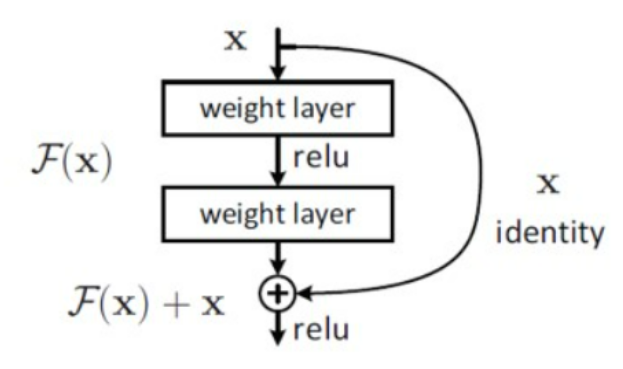
이와 같이 학습을 시키면 H(x) = F(x) + x가 된다. 모델은 H(x)를 얻기위하여 학습을 하는 것이 아닌 F(x) = H(x) - x로 학습을하여 그것의 방향은 F(x)가 0이되는 방향으로 학습을 진행한다.
Overfitting을 관리하는 방법
- Get more data
- Simplify your model
- Use data augmentation
- Use transfer learning
- Use dropout layers
- Use learning rate decay
- Use early stopping
Fine Tuning
- Pre training(사전 학습)
데이터셋을 기반으로 충분히 학습을 완료한 모델을 말한다.
- Transfer Learning(전이 학습)
pretrained model을 새로운 데이터셋(features, label)로 다시 학습시키는 것을 말한다.
- Fine tuning(미세 조정)
Transfer Learning과는 달리 pretrained model의 일부 layer를 수정하여 새로운 데이터셋(features, label)로 다시 학습시키는 것을 말한다.
pretrained data를 가져올때 모델 전부를 해석할 수 있다면 좋지만, 그렇지 못한다면, input과 output의 shape만 확인해도 된다. 그리고 그 shape들을 내가 사용할 input과 output에 맞게 변경해주는 tuning 작업을 하면 된다.
Pretrained Model은 아래 링크를 통해서 얻을 수 있다.
생성 모델 GAN
GAN은 Generative Adversarial Networks이다. GAN은 단순히 특정한 이미지를 이해하고 분류하는 것을 넘어서 실제 데이터와 흡사한 가짜 데이터를 생성하는 알고리즘입니다. GAN은 생성자(Generator) 모델과 구분자(Discriminator) 모델로 두 개의 모델이 학습하는 방식으로 동작합니다.
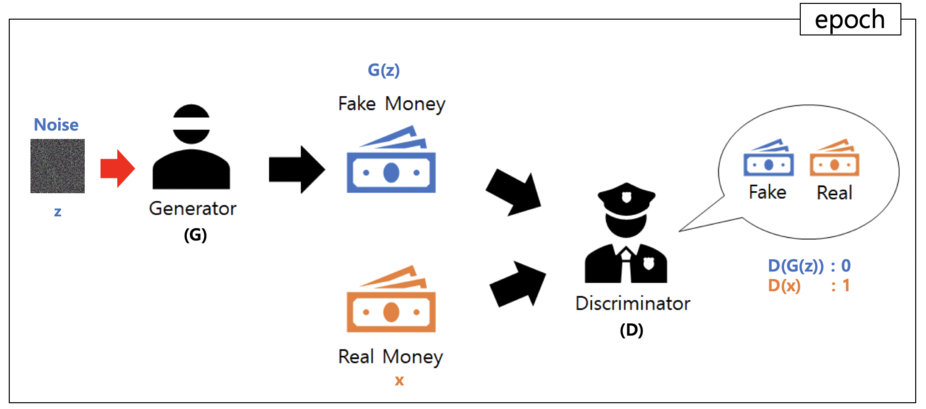
학습은 Generator가 최대한 Real한 image를 발생할 수 있도록 하는 방향으로 진행된다. GAN은 내부 식도 복잡하고 이해하기에 어려움이 있기 때문에 간단하게만 설명하고 넘어가겠다. GAN은 데이터가 부족할 때 학습을 통하여 새로운 데이터를 만들어낼 수 있기에 좋은 방법이다. 하지만 최근에는 많이 쓰이진 않는다.
NLP
NLP는 Natural Language Processing으로 언어처리 모델이다. 언어를 기계가 학습해야하므로 언어를 전처리해주는 과정이 필요하다. 전처리 과정에는 정체, 추출, 불용어 등이 있다.
전처리된 언어를 토큰화하여 작업을 진행하야한다. 토큰화는 단어를 의미를 갖는 최소단위로 쪼개는 작업이라고 보면 된다. 토큰화를 진행한 후 embedding을 진행해주어 문자를 숫자로 바꿔 학습할 수 있게 바꿔준다.
전체 적인 과정을 요약하면 다음과 같다
- load data
- data preprocessing
data cleaning
data tokenization
make vocabulary
data embedding
data padding - data loader
- model design
text data를 처리해야하기 때문에 data preprocessing과정이 복잡해졌다. text 처리 방식에 익숙해진다면 다른 전처리과정과 똑같이 느껴질 것으로 생각된다.
data cleaning 과정에서는 앞 뒤 공백을 제거해주고, 불필요한 값들을 제거해준다.
vocabulary는 중복을 제거한 어휘와 index가 정의된 집합이다. 어휘집을 통해 문자를 숫자로 변환할 수 있다.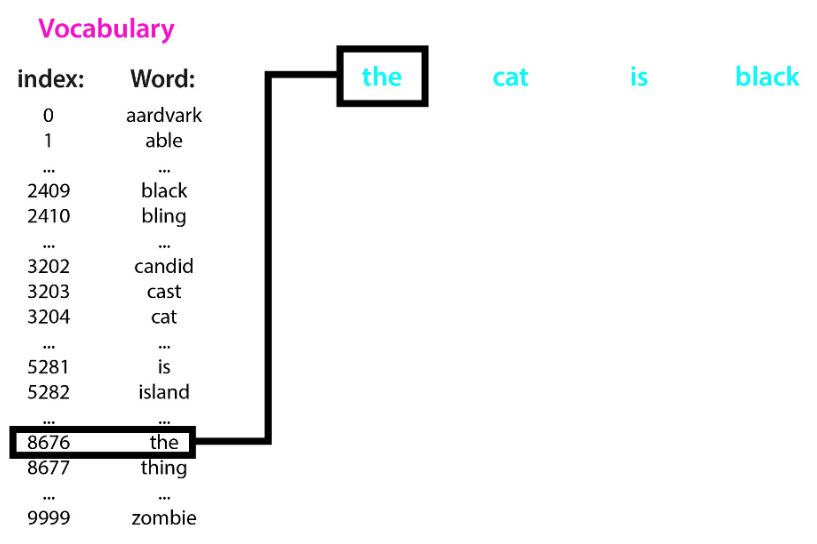
dataset의 shape은 2차원이고 (데이터의 량, 가장 큰 token의 갯수) 이다. token의 갯수는 데이터마다 다르기에 가장 큰 token에 맞게 빈 token은 0이나 특정 값으로 padding을 진행한다.
data embedding은 text를 벡터로 변환하는 과정이다. 가장 흔히 사용되는 것은 word2vec이다.
모델 설계는 conv1D를 사용한 모델을 예시로 들겠다.
import torch
class Conv1dModel(torch.nn.Module):
def __init__(self,vocab_size,embedding_dim=128):
super().__init__()
# 각 토큰(index)을 의미있는 숫자리스트(벡터)로 표현.......
# vocab_size -> 전체 토큰의 수
# embedding_dim -> 각 토큰을 표현할 수 있는 벡터의 크기
self.emb_layer = torch.nn.Embedding(vocab_size, embedding_dim)
self.seq = torch.nn.Sequential(
# CNN 1D
torch.nn.Conv1d(in_channels=embedding_dim, out_channels=embedding_dim*2, kernel_size=3),
torch.nn.ReLU(),
torch.nn.MaxPool1d(2),
torch.nn.Conv1d(in_channels=embedding_dim*2,out_channels=embedding_dim*4,kernel_size=3),
torch.nn.ReLU(),
torch.nn.MaxPool1d(2),
torch.nn.AdaptiveAvgPool1d(1),
# FC
torch.nn.Flatten(),
torch.nn.Linear(embedding_dim*4, 1)
)
def forward(self,x): # x (배치 크기, 문장 최대 길이)
emb_out = self.emb_layer(x) # emb_out(배치 크기, 문장 최대 길이, 임베딩 아웃풋 크기)
emb_out_premute = emb_out.permute(0,2,1) # emb_out_premute(배치 크기, 임베딩 아웃풋 크기, 문장 최대 길이)
seq_out = self.seq(emb_out_premute) # seq_out(배치 크기, 1)
return seq_out모델에 들어가는 input의 크기는 (배치 크기, 문장 최대 길이)이고 여기서 embedding이 진행되어 1개의 차원이 추가되고 permute를 사용하여 차원의 순서를 바꿔준다. 그리고 Sequential을 거쳐 최종적으로 (배치크기, target)의 shape가 된다. 이 모델은 리뷰가 긍정적인지 부정적인지를 확인하는 모델이기 때문에 target의 값은 0과 1의 값을 갖는다.
