- 합성곱 신경망과 심층신경망의 차이점
합성곱 신경망은 부분적으로 연결되어 있다
따라서 고해상도의 이미지나 음성 등의 고차원적인 데이터를 인풋으로 하여도 무한개의 뉴런으로 늘어나지 않은채 학습시킬 수 있다.
합성곱 신경망
고수준 뉴런이 이웃한 저수준 뉴런의 출력에 기반한다는 아이디어에서 착안된 신경망 모델이며 각 뉴런은 이전 층에 있는 몇개의 뉴런에만 연결된다. 이러한 구조가 전체 시야 영역에 포함된 모든 종류의 복잡한 패턴을 감지할 수 있게 된다.
1) 합성곱 신경망의 구조
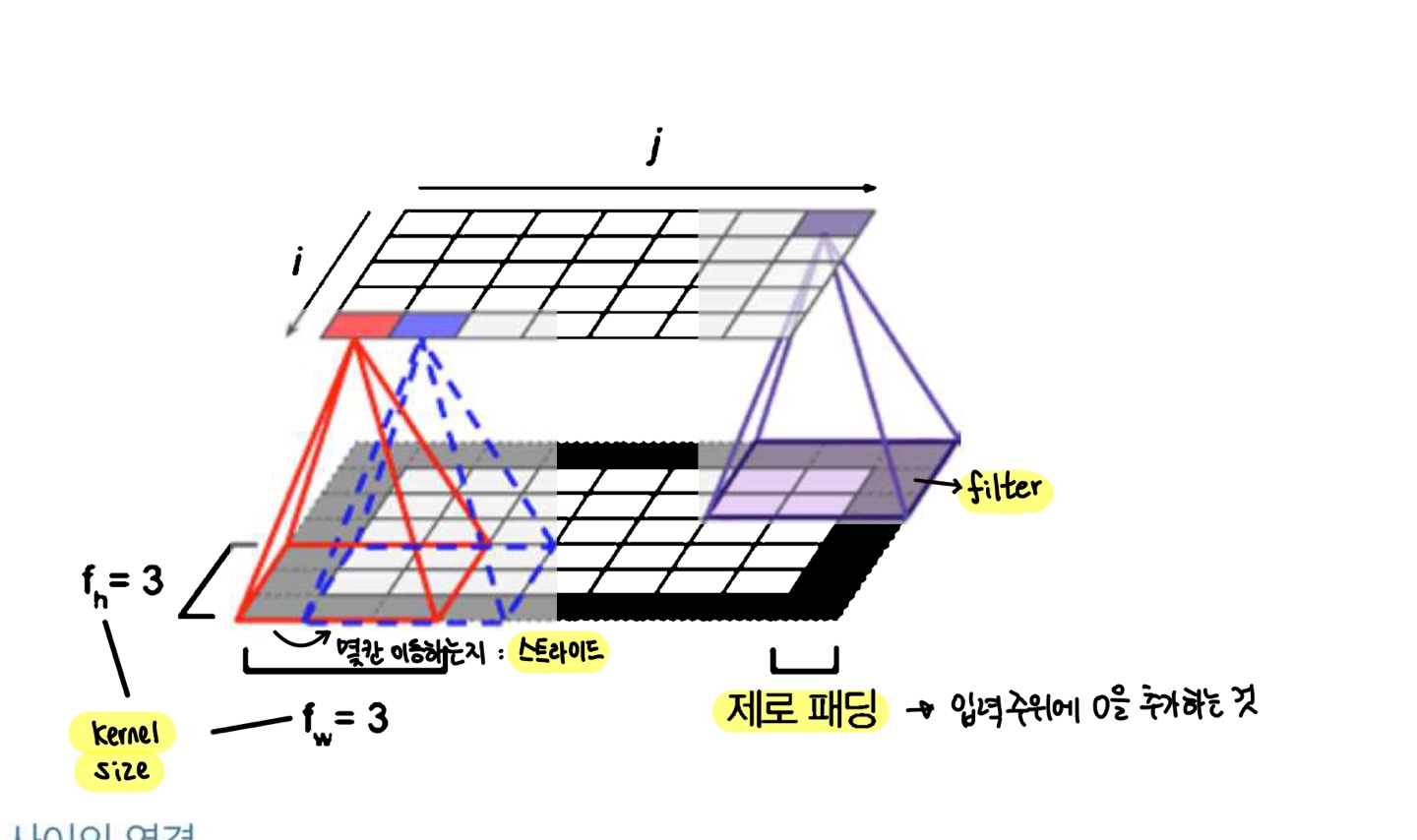
첫번째 합성곱층의 뉴런은 입력 이미지의 모든 픽셀에 연결되는 것이 아닌 합성곱 층 뉴런의 수용장 안에 있는 픽셀에만 연결된다. 그리고 두번째 합성곱층에 있는 각 뉴런은 첫번째층의 작은 사각 영역 안에 위치한 뉴런에 연결된다. ...
이런 구조는 네트워크가 첫번째 은닉층에서 작은 저수준 특성에 집중하고 그 다음 은닉층에서는 더 큰 고수준 특성으로 조합해나가는 계층적 구조 를 띄게 한다.
- filter
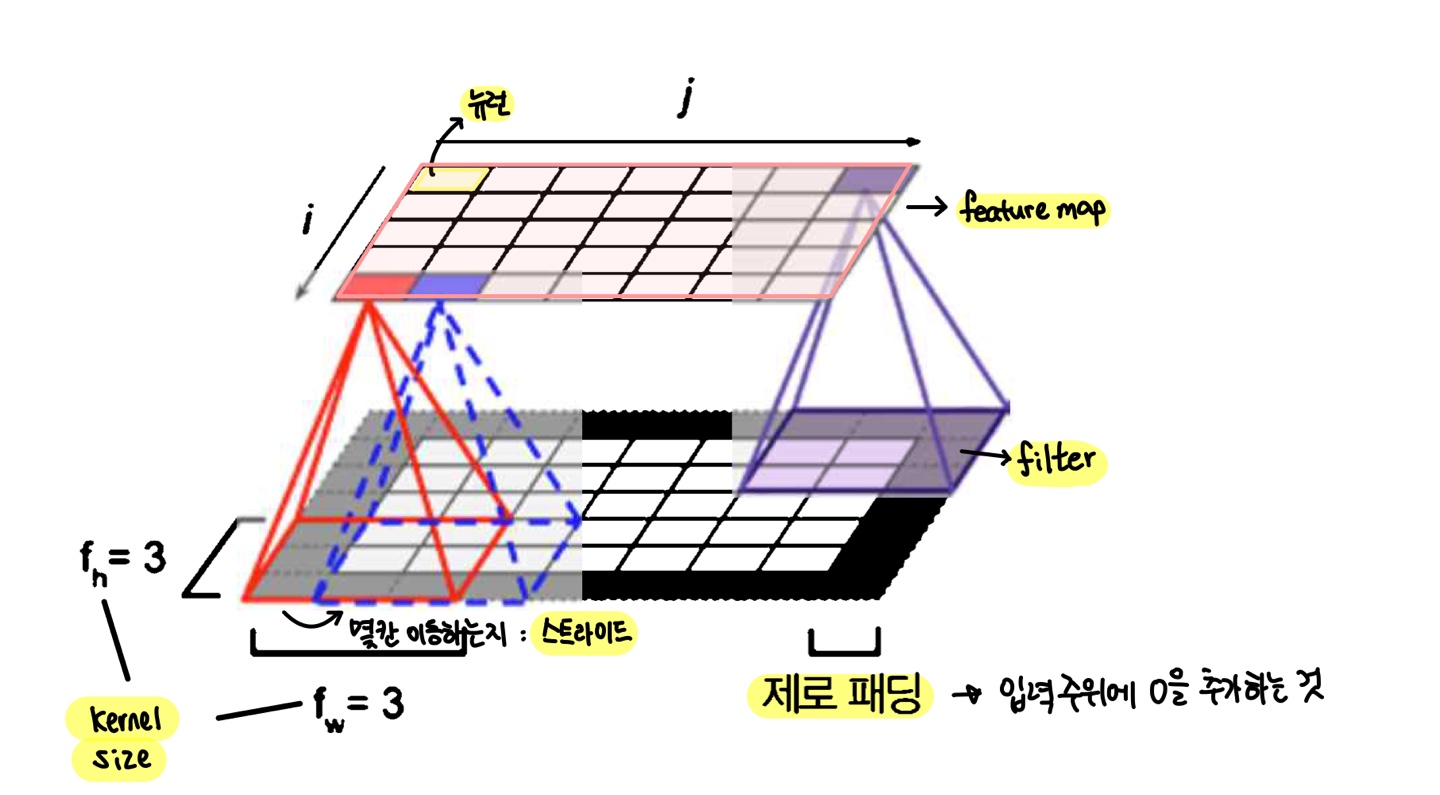
- 뉴런의 가중치이며 하나의 필터는 하나의 특성맵 (feature map) 을 만든다
- 이 맵은 필터를 가장 크게 활성화시키는 이미지의 영역을 강조한다.
- 훈련하는 동안 합성곱 층이 자동으로 해당 문제에 가장 유용한 필터를 찾고 상위층은 이들을 연결하여 더 복잡한 패턴을 학습한다.
- 각 특성 맵 안에서의 모든 뉴런이 같은 파라미터 공유
- CNN : 한 지점에서 패턴을 인식하도록 학습되었다면 어느 위치에 있는 패턴도 인식할 수 있다.
DNN : 한 지점에 있는 패턴을 인식하도록 학습되었다면 오직 패턴이 그 위치에 있을 때만 감지할 수 있음.

2) 합성곱 신경망 구현
- 각 데이터의 차원
- 입력 이미지 : (높이, 너비, 채널)
- 미니배치 : (미니배치 크기, 높이, 너비, 채널)
- 가중치 : (높이, 너비, 채널in, 채널out)
*여기서 채널이란 몇개의 필터 / 몇개의 층으로 인식하면 됨
#저수준 딥러닝 API
#각 채널의 픽셀 강도는 0에서 255 사이의 값을 가진 바이트 하나로 표현되어 0-1 로 스케일링 해줌
image = load_sample_image("flower.jpg")/255
output = tf.nn.conv2d(image, filters, strides, padding = "SAME")
#첫번째 이미지의 두번째 특성맵을 그림
plt.imshow(output[0, :, :, 1], cmap = 'gray')
plt.show()-
padding
- SAME : zero padding
- VALID : no padding
#신경망이 가장 잘 맞는 필터 학습
conv = keras.layers.Conv2D(filters = 32, kernel_size = 3, strides = 1,
padding = 'same', activation = 'relu')- pooling 층
- 목적 : 과대적합의 위험을 줄여주기 위해 파라미터 수를 줄이는 축소본을 만드는 것
- 풀링 뉴런은 가중치가 따로 없이 최대/ 평균과 같은 합산 함수를 사용해 입력값을 더하는 것
- maxpooling : 풀링 커널에서 가장 큰 값이 뉴런으로 전달되고 나머지 값은 버려짐
- 작은 변화에도 일정 수준의 불변성을 만들어줌
회전/ 확대/ 축소 등에 대해 불변성을 제공하여 예측 시, 이런 작은 부분에서 영향을 받지 않음 - 단점 : 파괴적이어서 정보 소실 일어날 수 있음
어떤 경우, 불변성이 아닌 입력값이 변함에 따라 출력값이 변해야하는 등변성이 필요할 때도 있음. 이런 경우, 역효과가 날 수 있음
- 작은 변화에도 일정 수준의 불변성을 만들어줌
- 공간차원이 아닌 깊이 차원으로 수행될 수도 있음

#poolsize = kernel size
max_pool = keras.layers.MaxPool2D(pool_size = 2)
#깊이 차원으로 풀링
#커널 크기와 스트라이드의 첫번째 세값은 1, 마지막 값은 깊이 차원으로 지정
#단, 입력 깊이를 나누었을 때 떨어지는 값이어야 한다
output = tf.nn.max_pool(images, ksize= (1,1,1,3), strides = (1,1,1,3), padding ='valid')
#or
depth_pool = keras.layers.Lambda(lambda X: tf.nn.max_pool(X, ksize = (1,1,1,3),
strides = (1,1,1,3), padding = 'valid') - 합성곱 신경망 전체 구조
- 첫번째 층의 필터 크기는 커도 괜찮음
- 출력층에 다다를수록 필터 개수 늘어남.
보통 풀링 층 다음에 필터 개수를 2배로 늘린다 - 완전 연결 네트워크로 가기전, 1D배열을 기대하므로 Flatten 을 사용해 일렬로 펼쳐야 한다.
model = keras.model.Sequential([
keras.layers.Conv2D(64,7, activation = 'relu', padding = 'same', input_shape=[28,28,1]),
keras.layers.MaxPooling2D(2),
keras.layers.Conv2D(128,3, activation ='relu', padding = 'same'),
keras.layers.Conv2D(128,3, activation ='relu', padding = 'same'),
keras.layers.MaxPooling2D(2),
keras.layers.Conv2D(256,3, activation ='relu', padding = 'same'),
keras.layers.Conv2D(256,3, activation ='relu', padding = 'same'),
keras.layers.MaxPooling2D(2),
keras.layers.Flatten(),
keras.layers.Dense(128, activation = 'relu),
keras.layers.Dropout(0.5)
keras.layers.Dense(10, activation = 'softmax')])이미지 출처 : 핸즈온 머신러닝 (2판)

AD+AI Ph.D course