Optimization과 관련된 용어
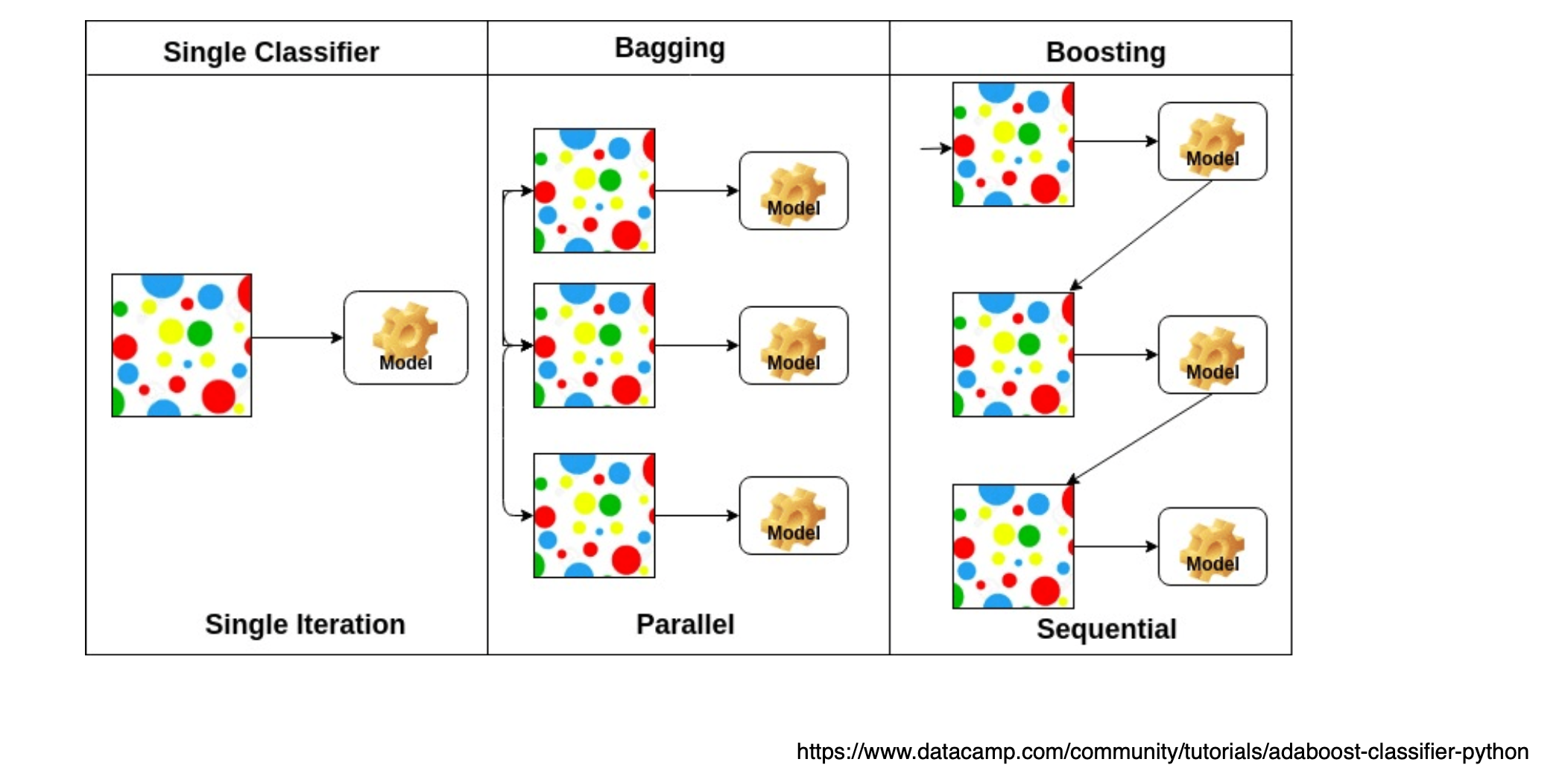
1) Generalization
Generalization이 좋다
= 테스트 데이터에서의 성능이 학습 데이터와 비슷하게 나온다.
= 학습데이터의 성능이 안좋으면 generalization이 잘 되어도 성능이 안좋다.
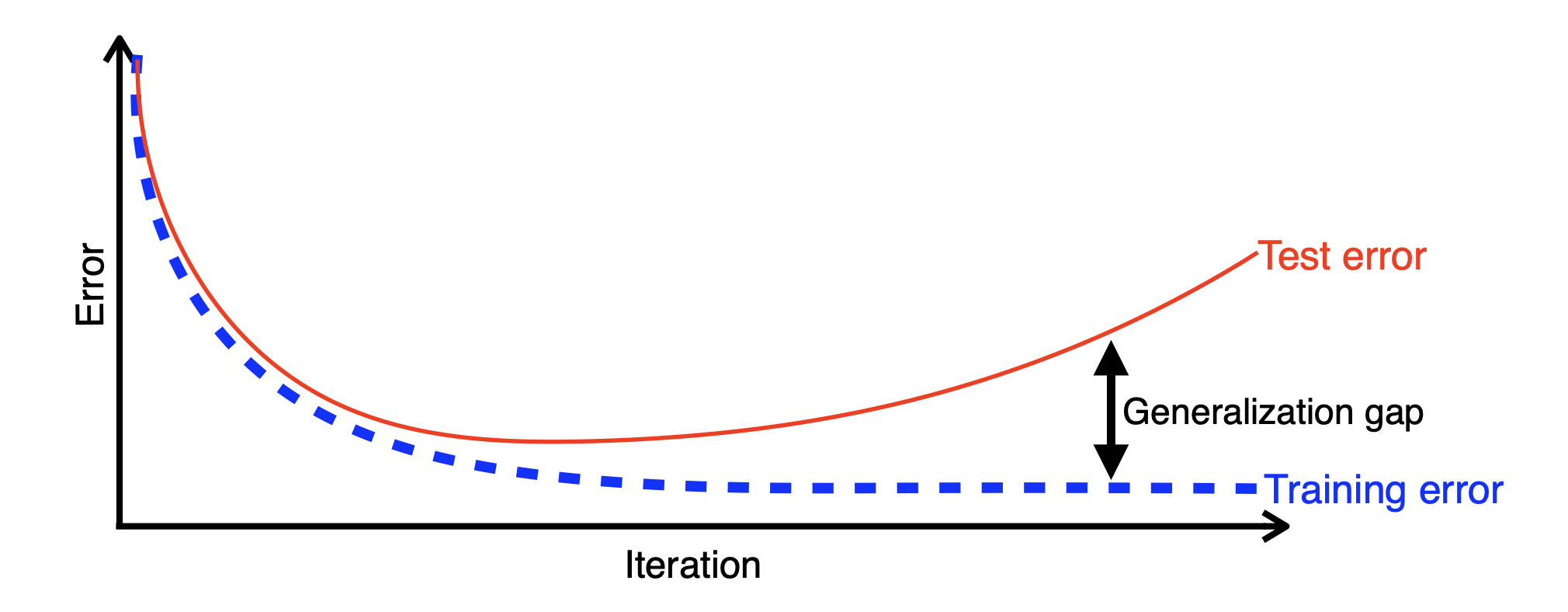
2) Underfitting vs Overfitting
- Underfitting: Train data도 잘 안됨.
- Overfitting: Train data에서는 잘 되지만 test data에서는 잘 안됨.
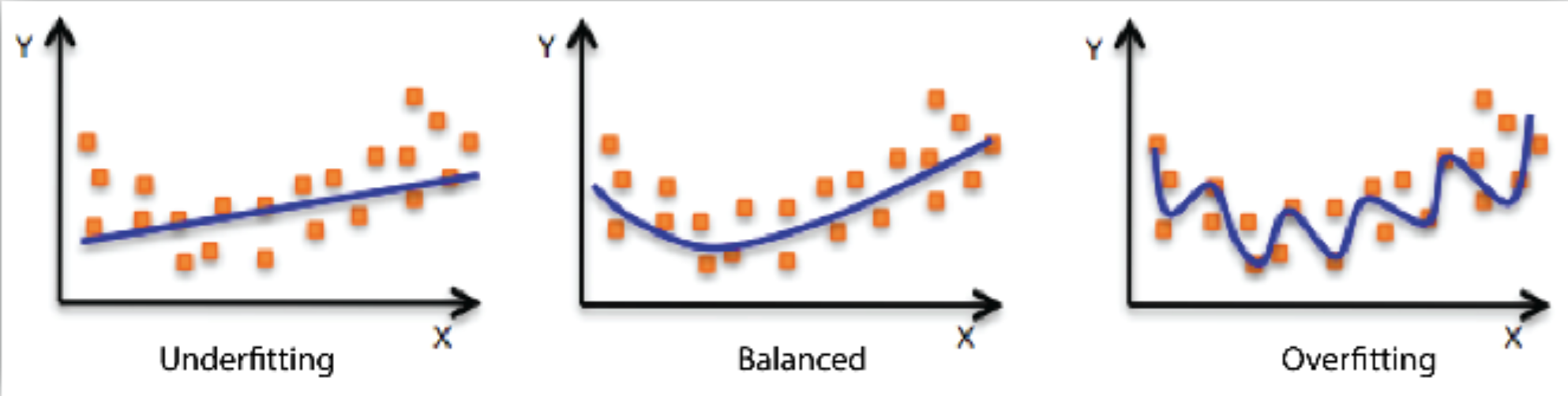
(이미지 출처) https://docs.aws.amazon.com/machine-learning/latest/dg/model-fit-underfitting-vs-overfitting.html
3) Cross-validation
k-fold로 나누어서 활용.
특히 Neural Network학습 시 최적의 hyperparameter (e.g., learning rate, loss function 등)를 정할 때 사용한다.
참고로, 주로 hyperparameter를 고정시키고 데이터를 학습시킬 때에는 모든 data를 다 사용한다. 그래야 더 많은 데이터로 모델 학습이 가능하기 때문이다. 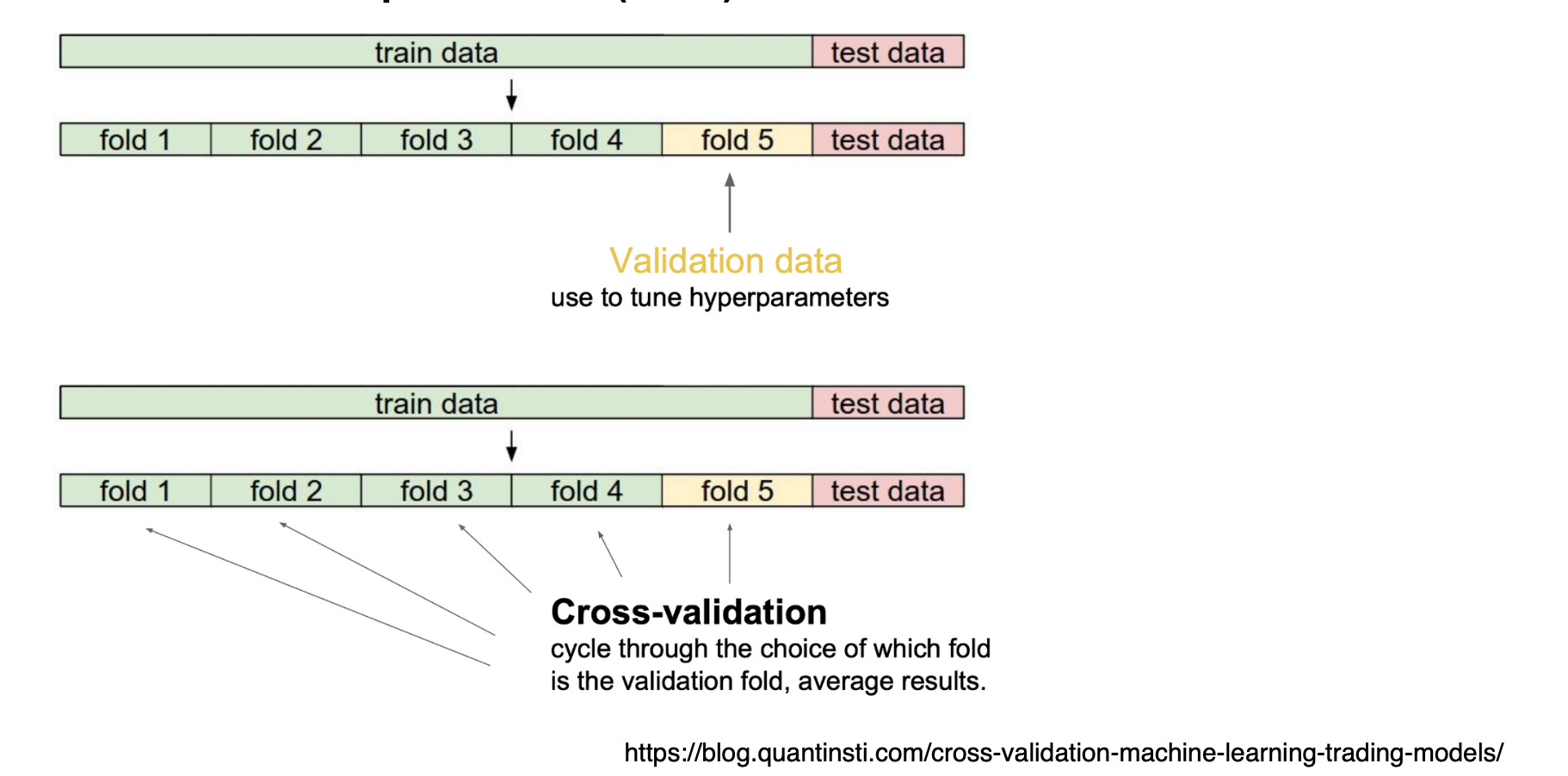
4) Bias and Variance
아래는 모델 성능 평가를 위한 개념이다. 결론적으로 보자면, low bias + low variance가 최고다.
- Bias: 평균적으로 보았을 때 true target에 가까운지
- low bias: 모델이 실제 데이터 패턴을 잘 학습하여 예측 값이 실제 값과 가깝다.
- high bias: 예측 값이 실제 값과 많이 다르다.
- Variance: 입력에 대한 출력이 얼마나 일관적인가? 모델의 예측이 훈련 데이터 세트의 변동에 얼마나 민감한지?
- low variance: 모델의 예측이 훈련 데이터 세트의 변동에 크게 영향을 받지 않아, 새로운 데이터 세트에서도 일관되게 예측할 수 있다.
- high variance: 모델의 예측이 훈련 데이터 세트의 변동에 매우 민감하여, 새로운 데이터 세트에서는 일관되게 예측하지 못하는 경우 = overfitting
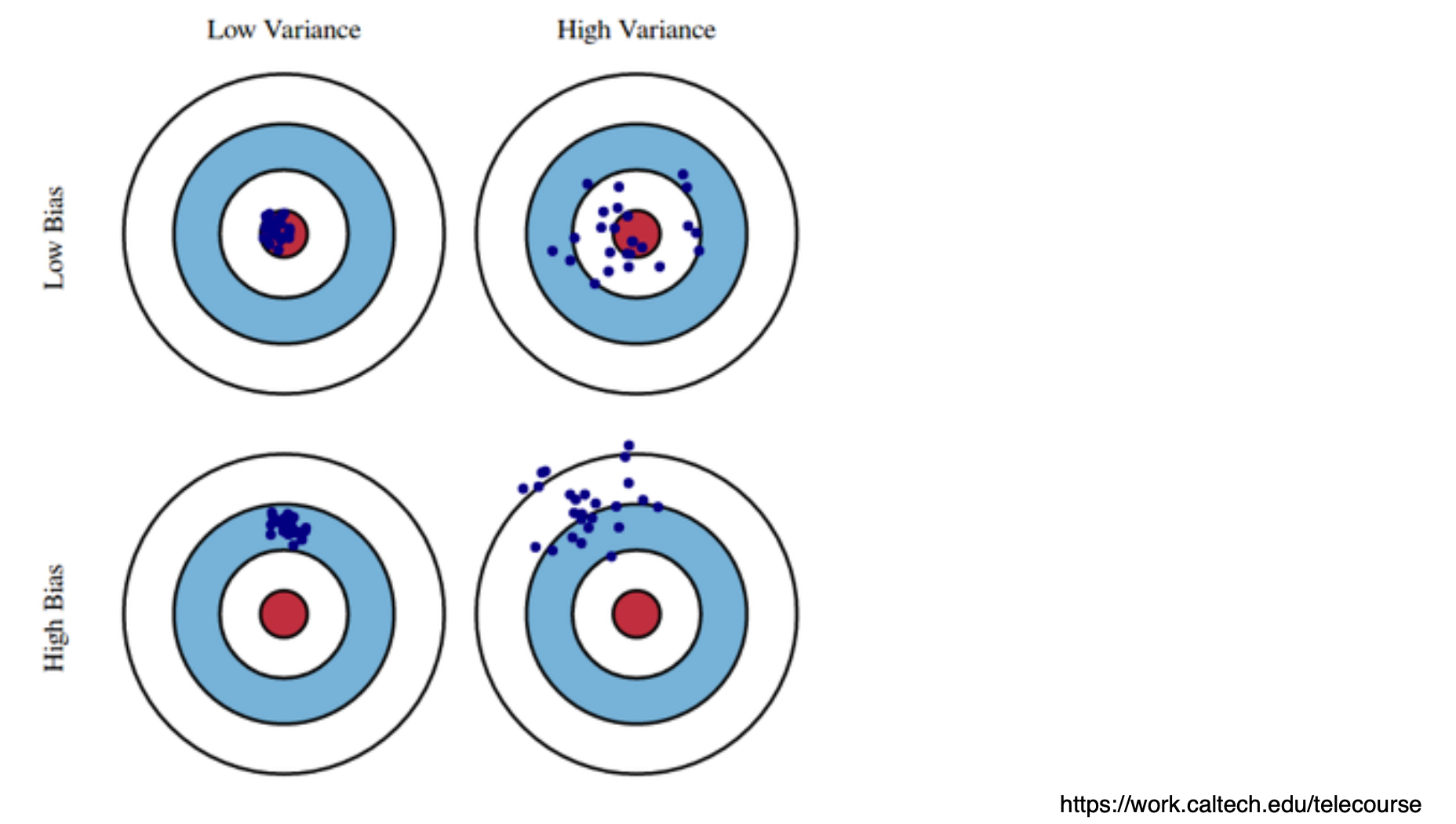
(추가 설명)
내 학습 데이터가 노이즈가 껴 있는 데이터라고 가정하였을 때, 모델의 cost를 최소화하는 것은 크게 세 파트로 나누어 볼 수 있다. 
즉, 하나가 줄어들면 (e.g., bias) 다른 것 (e.g., variance)가 높아질 가능성이 높다는 의미이다.
5) Bootstrapping
부트스트래핑은 원본 데이터 세트에서 여러 번의 재표본 추출을 통해 새로운 데이터 세트를 생성하는 방법이다. 각 재표본 추출은 원본 데이터 세트에서 중복을 허용하여 동일한 크기의 샘플을 무작위로 추출한다.
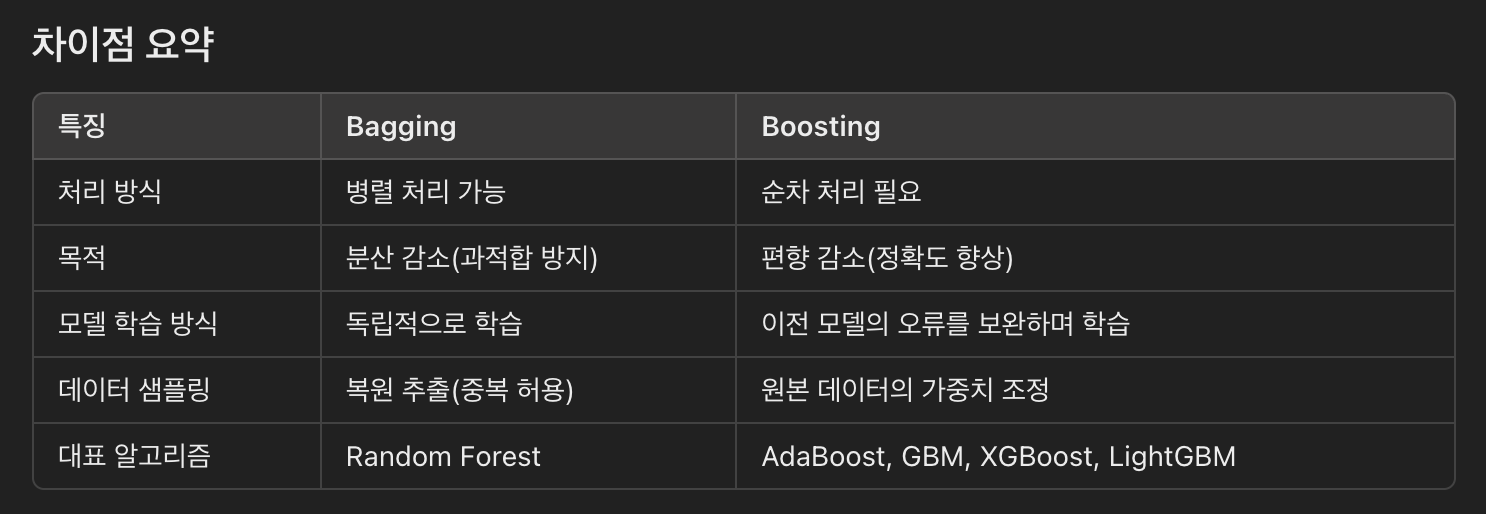
1. Bagging
-
개념
Bagging은 Bootstrap Aggregating의 줄임말로, 데이터 샘플을 무작위로 선택하고 복원 추출(중복 허용)하여여러 개의 훈련 데이터 세트를 생성한다. 각 훈련 세트로개별 모델을 학습시키고, 최종 예측은 개별 모델의 예측을평균(회귀의 경우)하거나다수결(분류의 경우)로 결합하여 결정한다. -
과정
- 원본 데이터 세트에서 복원 추출을 통해 여러 부트스트랩 샘플 생성.
- 각 부트스트랩 샘플로 개별 모델 학습.
- 개별 모델의 예측을 결합하여 최종 예측 도출.
2. Boosting
-
개념
Boosting은Weak Learners를 순차적으로 학습시키며, 각 단계에서이전 단계의 모델이 잘못 예측한 데이터를 더 중점적으로 학습합니다. 이를 통해 학습기들은 점점 더 어려운 패턴을 학습하게 되며,최종적으로 Strong Learner를 만듭니다. -
과정
- 초기 모델 학습.
- 각 데이터 포인트의 가중치를 조정하여,
잘못 예측된 데이터 포인트에 더 높은 가중치를 부여. - 다음 모델 학습 시, 조정된 가중치를 반영하여 데이터 학습.
- 이 과정을 반복하여, 최종적으로 여러 모델의 가중 합을 통해 최종 예측 도출.