쿨백-라이블러 발산이 불러일으킨 나비효과.
정보이론까지 공부하고 오다니,,, 차근차근 설명해보겠다.
이 페이지는 chat gpt의 공이 크다.

나비효과 시발점 박제
정보량과 확률
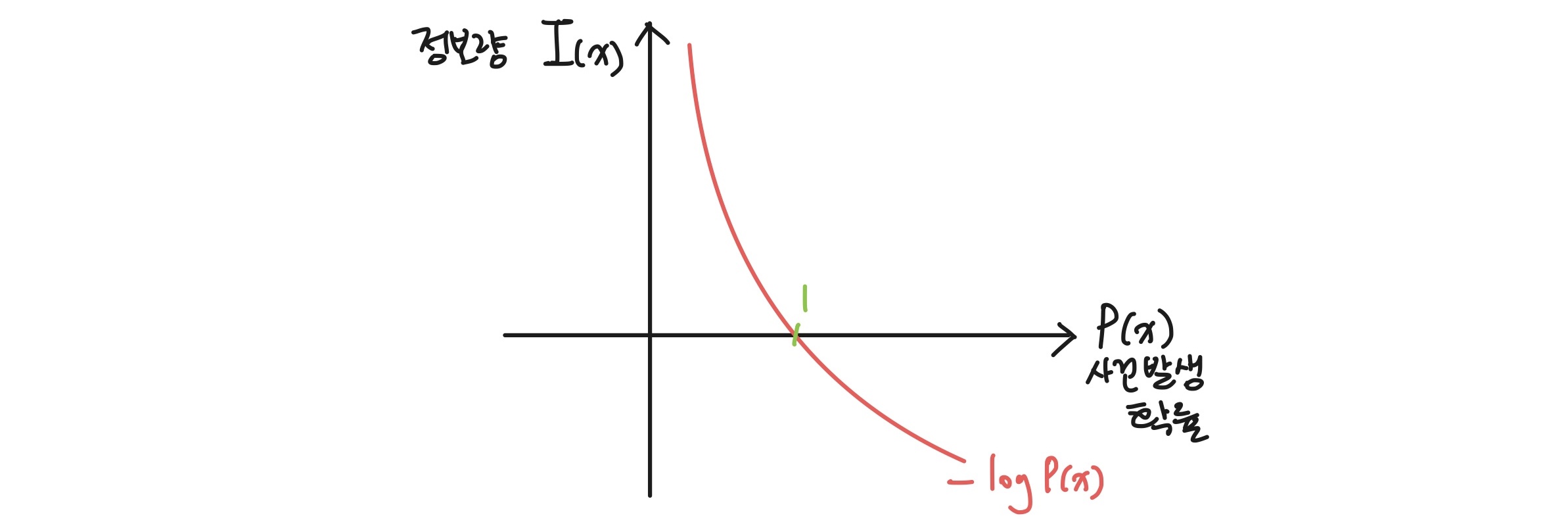
 특정 사건이 일어날 확률 가 작을수록 더 많은 정보 를 제공한다.
특정 사건이 일어날 확률 가 작을수록 더 많은 정보 를 제공한다.
직관적으로, 자주 일어나는 일은 우리에게 큰 정보가 되지 않지만, 드물게 일어나는 일은 많은 정보를 준다는 개념이다.
즉, 정보량은 사건이 얼마나 예측불가능한지, 불확실성을 나타낸다.
- 낮은 확률 사건: 예측하기 어려움 -> -> 불확실성 높음 -> 정보량 많음
- 높은 확률 사건: 예측하기 쉬움 -> 불확실성 낮음 -> 정보량 적음
정보량 = '깜놀도'
출처: https://memesoo99.tistory.com/38 [미미로그:티스토리]
엔트로피
1) 엔트로피와 불확실성에 대한 개괄
 즉,
즉, 불확실성이 클수록 (= 다양한 사건이 발생할 가능성이 높을수록) 엔트로피가 높고,
불확실성이 작을수록 (= 사건 발생을 예측하기 쉬울수록) 엔트로피가 낮다.
2) 엔트로피(Entropy)의 정의
정보량이 단일사건에 대한 정보량이었다면, 엔트로피는 어떤 사건에 대한 확률 분포의 정보량이라고 할 수 있다. 즉, 엔트로피는 정보량에 대한 기대값, 평균이다.
출처: https://memesoo99.tistory.com/38 [미미로그:티스토리]
엔트로피는 단일확률분포의 불확실성을 측정한다. 이는 앞선 정보량과 불확실성에 대한 정의에 따라, 엔트로피는 주어진 확률변수의 기대정보량을 나타낸다고 할 수 있다. 즉, 엔트로피는 확률변수 가 가질 수 있는 모든 값에 대해 평균적으로 얻을 수 있는 정보량을 의미한다.

엔트로피가 높을수록 불확실성이 높다는 의미이며, 평균정보량이 많다는 의미이다.
크로스 엔트로피(Cross Entropy)
1) 크로스 엔트로피에 대한 개괄
크로스 엔트로피는 두 확률분포 간의 차이를 측정하는 데에 사용된다. 특히, 실제 분포와 예측 분포 간의 차이를 나타낸다.
 즉, 크로스 엔트로피 값이 크다는 것은 예측 분포가 실제 분포와 크게 다르다는 것이며, 잘못 예측하였다는 뜻이다. 따라서 우리는
즉, 크로스 엔트로피 값이 크다는 것은 예측 분포가 실제 분포와 크게 다르다는 것이며, 잘못 예측하였다는 뜻이다. 따라서 우리는 크로스 엔트로피를 최소화해야 한다.
(참고) 왜 크로스 엔트로피 식에 (-)가 들어가나요?
엔트로피 식에서 마이너스 기호가 필요한 이유는 로그 함수가 0과 1 사이에서 음수 값을 가지기 때문입니다. 확률 분포의 모든 확률 𝑝(𝑥)는 0과 1 사이의 값을 가지므로, log𝑝(𝑥)는 음수가 됩니다. 따라서, 엔트로피가 양수 값을 가지도록 하기 위해 마이너스 기호가 필요합니다.
2) 기계학습에서의 크로스 엔트로피 손실 함수 (Cross Entropy Loss)
크로스 엔트로피(Cross Entropy)와 크로스 엔트로피 손실 함수(Cross Entropy Loss)는 같은 개념을 지칭하며, 주로 문맥에 따라 다르게 표현된다. 다시 말해, 기계학습에서의 크로스 엔트로피 개념을 크로스 엔트로피 손실 함수라는 구체적인 명칭으로 불리는 것이다. 이러한 크로스 엔트로피 손실 함수는 머신러닝에서 모델의 성능을 평가하고 최적화하는 데 사용된다. 이는 실제 레이블 와 모델이 예측한 확률 분포 간의 차이를 측정하는 척도이다. 이 손실 함수는 주로 분류 문제에서 사용된다.
크로스 엔트로피 손실 함수는 실제 레이블의 원-핫 인코딩 와 모델의 예측확률 를 사용하여 다음과 같이 계산된다:
Cross-Entropy Loss =
크로스 엔트로피 손실함수 예시
1) 모델 예측과 실제 데이터가 확률 분포로 나타낼 수 있다. 

2) 모델의 예측 분포와 실제 데이터의 분포를 비교하여 모델의 성능을 평가할 수 있다. 이 비교는 손실함수를 통해 이루어진다. 구체적으로, 크로스 엔트로피 손실 함수를 활용하는 예시를 보여주고자 한다. 
(참고) 평균제곱오차(Mean Squared Error, MSE)는 주로 회귀문제에서 사용된다.
쿨백-라이블러 발산 (KL Divergence)
KL divergence도 두 확률 분포 간의 차이를 측정하는 비대칭적인 척도이다. 이는 주로 두 분포 간의 정보 손실을 측정하는 데에 사용된다.
기계학습에서는 변분 오토인코더(Variational Autoencoder, VAE)와 같은 모델에서 사용된다.
- 비대칭적인 척도란?


(참고) 크로스 엔트로피와 쿨백-라이블러 발산의 차이?
KL다이버전스 = (크로스 엔트로피) - (실제 엔트로피)
