아래 내용은 네이버 AI precourse 강의를 개인 공부를 위해 정리한 내용입니다.
최대가능도 추정법
확률분포마다 사용하는 모수가 다른데, 데이터를 잘 설명할 가능성이 가장 높은 모수를 추정하는 방법이 최대우도법 또는 최대가능도추정법(Maximum Likelihood Estimation, MLE)이다.
출처: https://amber-chaeeunk.tistory.com/77 [채채씨의 학습 기록:티스토리]
1) 개념 정의

- 우도(Likelihood): 주어진 데이터 가 특정 파라미터 값(모수 )을 가질 때의 확률
- 가능도함수(Likelihood Function): 모수가 일 때, 주어진 표본 가 얻어질 확률을 의미한다.; 가능도함수가 크다는 말은 해당 일 때 해당 표본 가 얻어질 확률이 높다는 의미이다. 즉, 라면, 보다 가 모수일 확률이 높다는 의미이다.
이 때 주의해야할 것은, 가능도함수는 모수 공간에서 정의되며, 주어진 데이터 에 대한 모수 의 가능성을 평가하는 역할을 한다는 것이다. 따라서 가능도함수를 에 대해 적분해도 그 값이 1이 되지 않는다. - 최대우도법(Maximum Likelihood Estimation, MLE): 주어진 데이터에 대해 가장 높은 우도를 가지는 파라미터 값을 찾는 방법
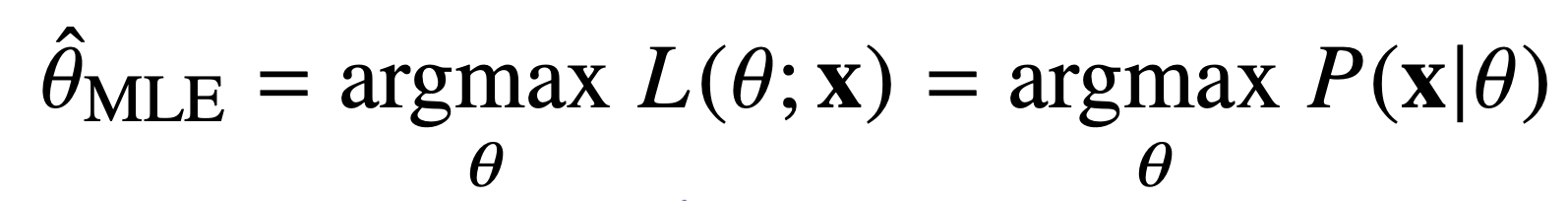

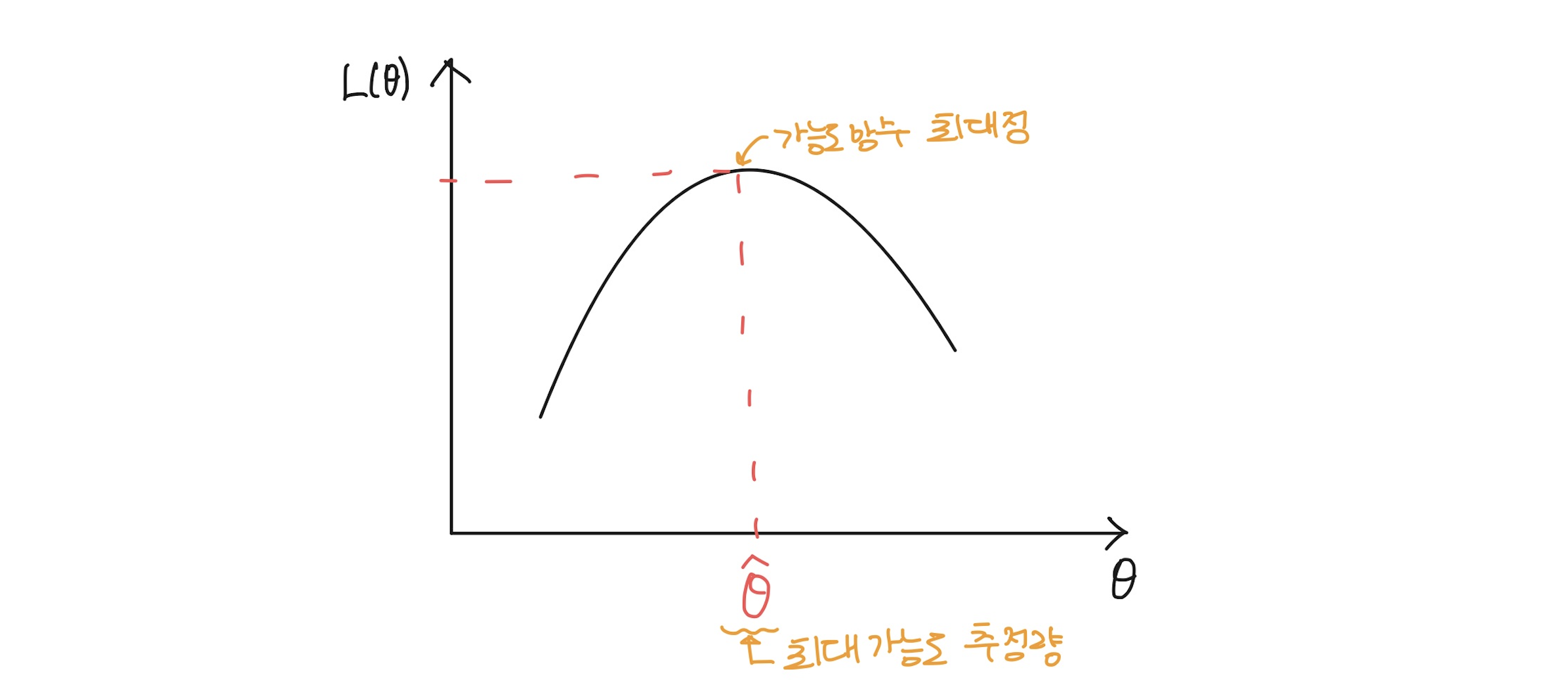 [이미지 참고: https://losskatsu.github.io/statistics/mle/#4-%EA%B0%80%EB%8A%A5%EB%8F%84%ED%95%A8%EC%88%98%EA%B0%92%EC%9D%B4-%ED%81%AC%EB%8B%A4]
[이미지 참고: https://losskatsu.github.io/statistics/mle/#4-%EA%B0%80%EB%8A%A5%EB%8F%84%ED%95%A8%EC%88%98%EA%B0%92%EC%9D%B4-%ED%81%AC%EB%8B%A4]
2) 독립사건에서의 최대우도법
주어진 데이터가 서로 독립일 때(독립적으로 추출되었을 경우), 전체 데이터 에 대한 우도는 각 데이터 포인트의 확률의 곱으로 표현된다.
이 때, 우리는 연산을 최적화하기 위해 곱셈 연산을 덧셈으로 바꿔주는 로그가능도를 활용할 것이다.
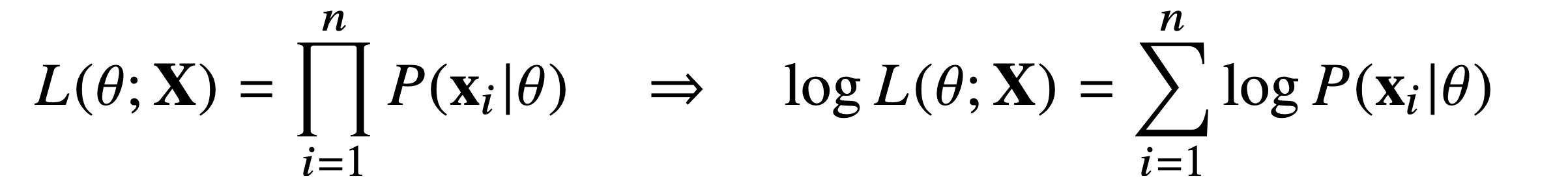
음의 로그가능도를 사용하는 이유: 머신러닝의 목표는 손실함수를 최소화하는 모델을 찾는 것이다. 그런데 상당히 유사하게, 로그가능도함수는 가능도를 최대화하고자 한다. 따라서 로그가능도함수를 통해 목적식(손실함수)의 최소값을 찾기 위해서는 음의 로그가능도 함수를 활용하여 최적화하는 것이다. 구체적인 설명은 다음 포스팅에서 확인해보자
(예시1) 정규분포의 최대우도 추정

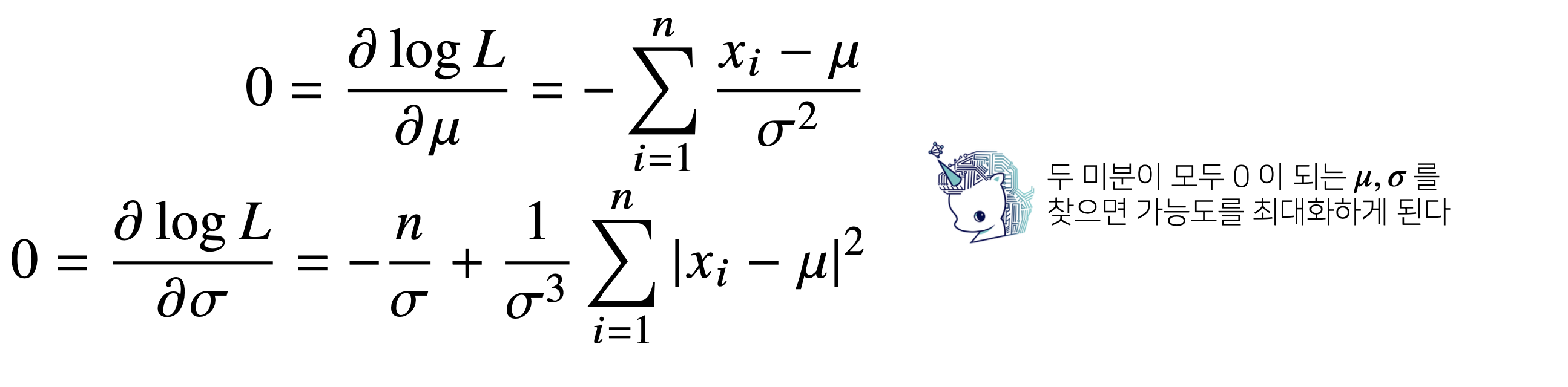
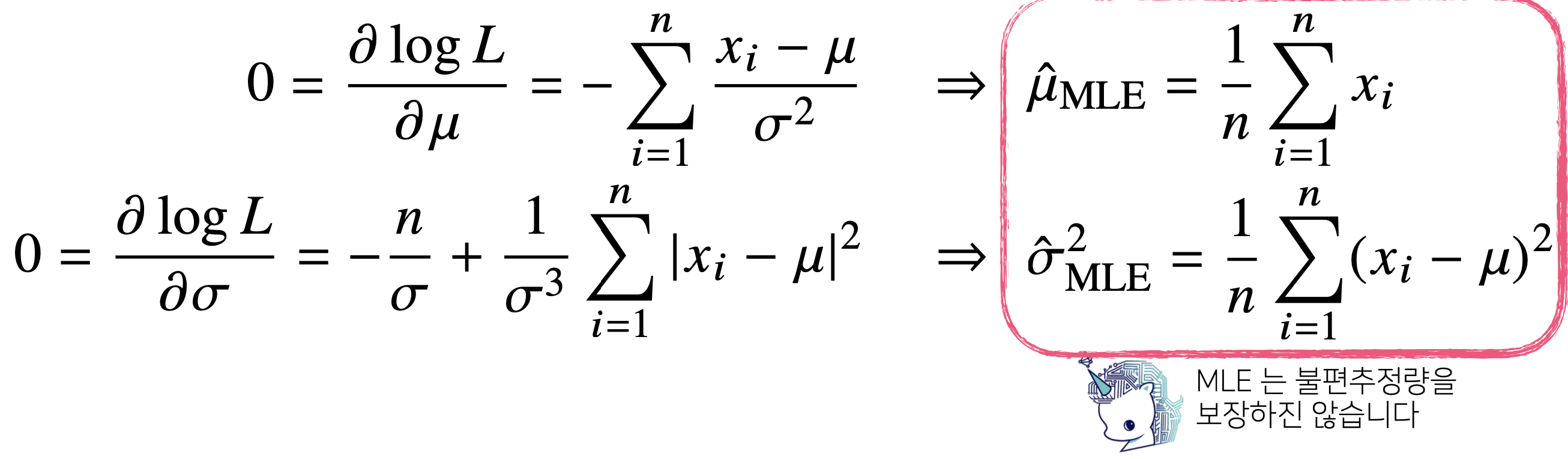
표본분산을 구하는 식에서는 (n-1)로 나눴는데, 여기서는 (n)으로 나눈 값이 나왔다. 즉, 모표준편차와는 조금 차이가 있기는 하다 (불편추정량은 보장되지 않는다). 그래도 consistency는 보장되기 때문에 괜찮다!
위의 식에 대한 chatgpt의 설명은 다음과 같다. 같은 내용이니 위의 글만 보고도 알겠다면 굳이 보지 않아도 된다! 
(질문) 최대우도법으로 추정한 모수와 표본을 통해 단순히 계산한 모수가 같은데, 왜 힘들게 최대우도법을 이용하나요?
최대우도법은 매우 일반적인 방법으로, 정규분포뿐만 아니라, 다양한 확률분포와 모델에 적용할 수 있기 때문이다.
즉, 표본평균이나 표본분산을 단순히 계산하는 방식은 특정 분포에 한정될 수 있지만, 최대우도법은 분포에 상관없이 적용할 수 있다.
(예시2) 카테고리 분포의 최대우도 추정
이 내용을 이해하기 위해서는 수많은 사전지식이 필요하다.
아래 내용을 보며 사전지식을 간략하게 쌓아보도록 하자.
(참고) 카테고리 분포란?
베르누이 분포가 2개 중 1개를 선택하는 확률분포를 의미하는 것이었다면, 카테고리 분포는 d차원으로 확장한 개념이다. 즉, 여러 개의 범주(Category) 중 하나에 속할 확률을 모델링하는 분포이다. 이는 주로 하나만 1이고 나머지는 0을 갖는 one-hot vector 형태로 표현된다.
- 카테고리 분포의 제약식
카테고리 분포의 확률벡터 는 각 범주에 속할 확률을 나타내며, 카테고리 분포의 모수는 다음의 제약식을 만족해야 한다:
- 라그랑주 승수법
라그랑주 승수법은 제약이 있는 최적화 문제를 푸는 방법 중 하나로, 모든 제약식에 라그랑주 승수(Lagrange Multiplier) λ를 곱하고 등식 제약이 있는 문제를 제약이 없는 문제로 바꾸어 문제를 해결하는 방법입니다.
출처: https://decisionboundary.tistory.com/2
- 목적함수 를 최적화(최대화 또는 최소화)하고자 한다.
- 제약조건 이 존재한다.
이 경우, 라그랑주 승수법은 다음과 같은 라그랑주 함수(Lagrangian)를 정의한다.
위 수식이 나오는 직관적인 이유는, 기하학적으로 살펴보면 이해하기 쉽다. 아래 그림에서 두 함수가 접하는 지점이 최대/최소 점이기 때문이다. 즉, 두 함수의 gradient vector가 서로의 상수배 관계를 가질 때 최대/최소점이기 때문이다.
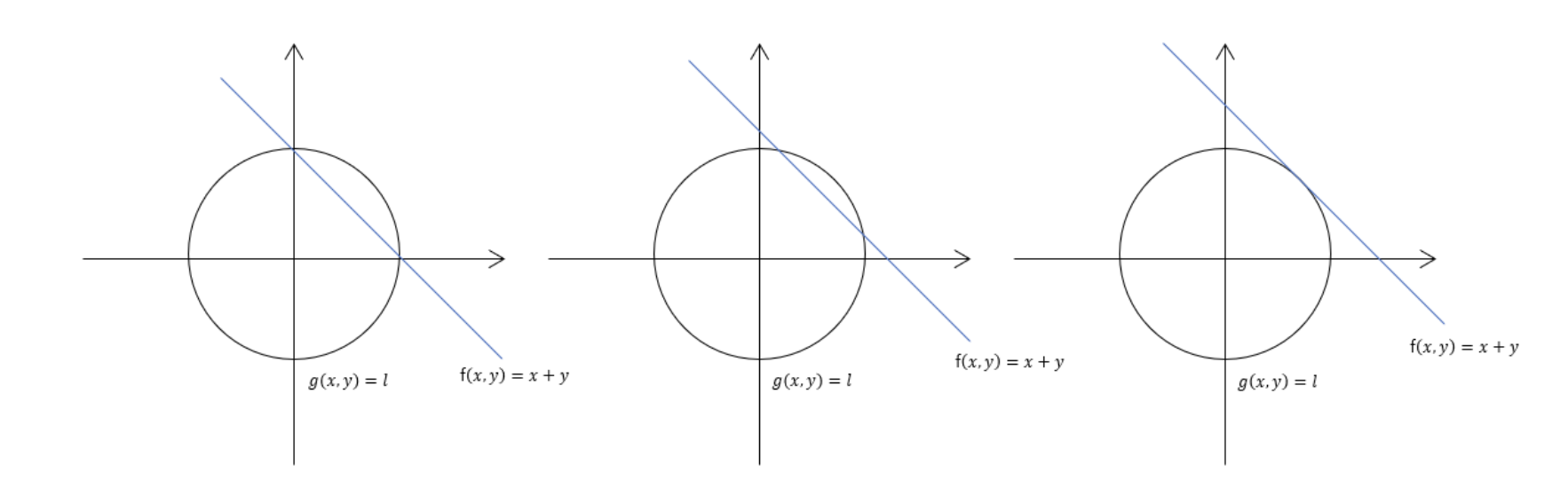
- (참고) 왜 상수배인가?
그레디언트 벡터 ∇f는 의 등고선에서 수직인 방향을 가리킨다. 마찬가지로 ∇𝑔는 의 등고선에 수직인 방향을 가리킨다. 즉, 두 등고선이 접하는 지점에서는 ∇f와 ∇𝑔가 같은 방향을 가리켜야 하며, 평행하게 정렬되어 있어야 한다. 그러나 크기는 달라도 상관 없다. 같은 방향을 가리키기만 하면 되기 때문에, 하나의 벡터가 다른 벡터의 상수배로 표현될 수 있는 것이다.
즉, 카테고리 분포의 최대우도법을 이용한 모수 추정을 위해서는 최대우도법 수식을 만족하며, 카테고리 분포의 제약식을 만족하는 함수를 계산하면 된다.
과정은 생략하고, 결론을 이야기하자면 다음과 같다.
각 범주의 확률 의 MLE 추정값은 다음과 같다.
여기서 는 범주 의 관찰확률의 추정치이며, 는 범주 가 나타난 횟수, 은 전체 관찰 횟수이다.
이는 굉장히 직관적인 결과로, (각 범주에 대한 관찰된 횟수) / (전체 관찰 횟수) 를 통해 각 범주의 확률을 추정한다는 결과가 나온다.
3) 딥러닝에서 최대가능도 추정법
 : L번째 layer
: L번째 layer
: class 개수
: 각 data
: 정답 레이블의 의 번째 값
