최악의 시나리오만을 확인 할 뿐만이 아니라 다른 시나리오도 고려해야 하는 이유를 설명하도록 하곘다.
삽입 정렬
삽입 정렬은 자료 배열의 모든 요소를 앞에서부터 차례대로 이미 정렬된 배열 부분과 비교하여, 자신의 위치를 찾아 삽입함으로써 정렬을 완성하는 알고리즘이다.
삽입 정렬 동작 과정
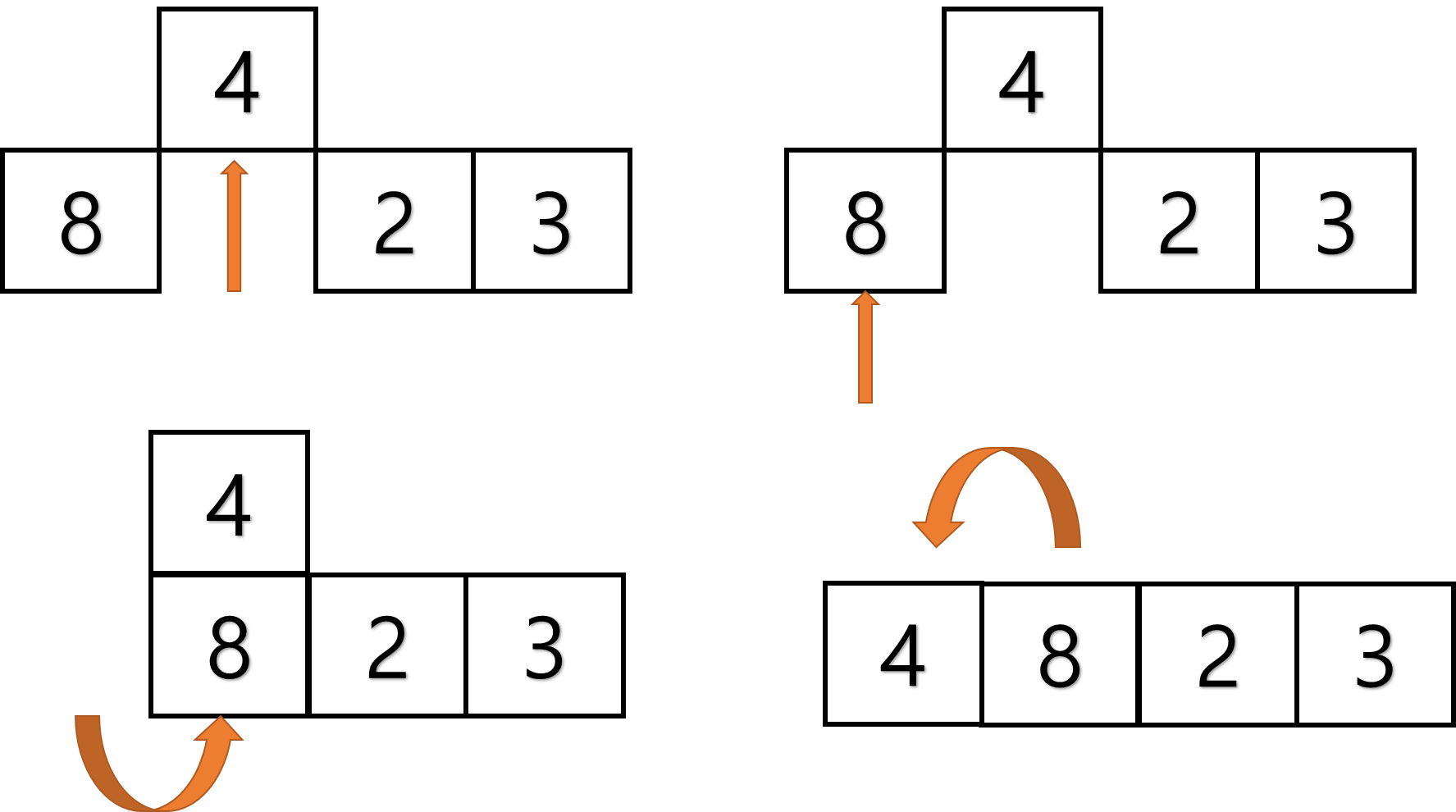
- 첫 번째 패스스루에서 임시로 인덱스의 값을 삭제하고 이 값음 임시 변수에 저장한다.
- 다음으로 공백 왼쪽에 있는 각 값을 ㄱ자ㅕ와 임시 변수에 있는 값과 비교하며 시프트한다.
- 위 과정을 반복한다.
삽입 정렬 코드
void insertionSort(int[] arr) { for(int index = 1 ; index < arr.length ; index++){ int temp = arr[index]; //배열의 값을 저장 int aux = index - 1; //1부터 시작하기 때문에 0번째 비교를 위해 while( (aux >= 0) && ( arr[aux] > temp ) ) { // 임시 값보다 크다면 arr[aux + 1] = arr[aux]; aux--; //기존에 정렬된 값을 시프트하기 위해 } arr[aux + 1] = temp; } }임시 값을 저장하고 임시 값 보다 값이 크다면 배열을 차례 차례 쉬프트 한 후 마지막 임시 값을 저장한다.
삽입 정렬의 효율성
삽입 정렬에 포함된 단계는 삭제, 비교, 시프트, 삽입 네 종류다. 사입 정렬의 효율성을 분석하려면 각 단계별 총합을 계산해야 한다.
최악의 경우 비교는 1 + 2 + 3 + ... + N-1번의 비교과 일어난다.
원소가 다섯 개인 배열이면 10번, 열개이면 45번, 20개면 190번 일어나게 된다.
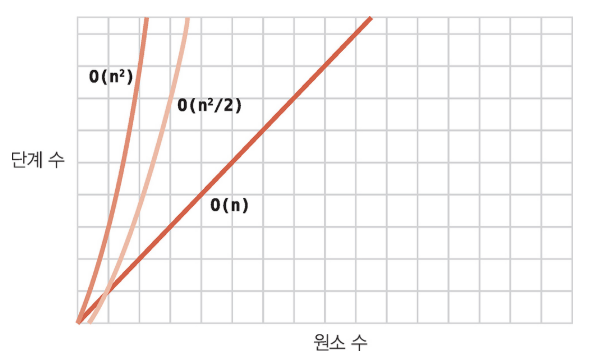
이러한 패턴에 따르면 대락 N^2/2번 비교가 일어난다.
시프트의 경우 비교가 일어날 때마다 값을 시프트 해야 하르모 N^2/2번 시프트가 발생된다.
비교 + 시프트 = N^2임을 알 수 있다. 이 때 삭제와 삽입은 패스스루당 한 번 일어나게 된다.
패스 스루는 N-1번 이므로 N^2+2-2번의 단계를 필요로 한다.
하지만 빅오는 상수를 무시하므로 최악의 경우 O(N^2)이다.
최악이 아닌 평균적인 경우
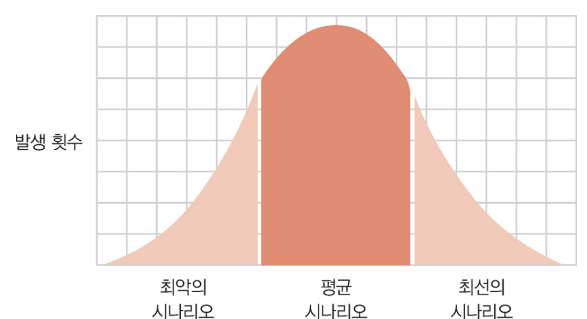
위 그래프를 본다면 최악과 최선의 시나리오보다 평균 시나리오가 자주 발생하는 것을 알 수 있다.
그렇다면 삽입 정렬은 시나리오 마다 어떠한 단게를 가지는지 알아보자.
삽입 정렬의 최악은 O(N^2)이라는걸 확인 했다.
그렇다면 최선의 경우, 이미 모든 배열이 정렬되어 있다면, 값을 삭제하고 다시 단 한번의 비교 후 삽입 일어난다. 그렇기에 O(N)이다.
평균 시나리오에서 즉 절반 정도가 이미 정렬되어 있다고 생각하자. 그 경우 O(N^2/2) 효율성을 가진다.
세 종류의 성능을 위 그래프로 표현 할 수 있다.
그렇다면 삽입 정렬과 선택 정렬의 세 시나리오에서는 어떠한 결과를 가지는지 비교해보자.
모든 시나리오를 고려 했을 경우 임의로 정렬된 배열이 평균 보다 많다면 오히려 삽입 정렬이 더욱 뛰어난 효율성을 가질 수 있다는 걸 확인 할 수 있었다.

실제 코드와 사례
아래 두 코드의 빅오는 O(N^2)으로 동일하다. 하지만 최선의 경우와 평균의 경우를 따지면 달라진다.
for(int i = 0; i < fa.length; i++){ for(int j = 0; j < sa.length; j++){ if(fa[i] == sa[j]) { System.out.print(sa[j]); } } }for(int i = 0; i < fa.length; i++){ for(int j = 0; j < sa.length; j++){ if(fa[i] == sa[j]) { System.out.print(sa[j]); break; } } }최선의 경우 N번 동작하고 평균의 경우 N과 N^2 사이 만큼 동작한다. 이렇게 실제 코드를 통해
최선의 경우와 평균의 경우도 고려해야하는 이유를 확인 해봤다.
결론
빅 오는 최악의 시나리오를 가정하고 표현한다. 빅 오로 알고리즘을 선택하는 것 또한 좋은 방법이지만, 다른 시나리오를 고려해 볼 필요성을 확인 할 수 있다.
