빅 오를 사용 했을 경우 선택 정렬과 버블 정렬 모두 O(n^2)이다. 하지만 이를 실직적으로 선택 정렬의 경우 n^2/2의 단계를 필요로 한다. 빅 오로 효율성이 같아 보이는 알고리즘을 구별해 내서 더 빠른 알고리즘을 고르는 법을 알아보자.
선택정렬
선택 정렬(選擇整列, selection sort)은 제자리 정렬 알고리즘의 하나이다.
선택 정렬의 동작 과정
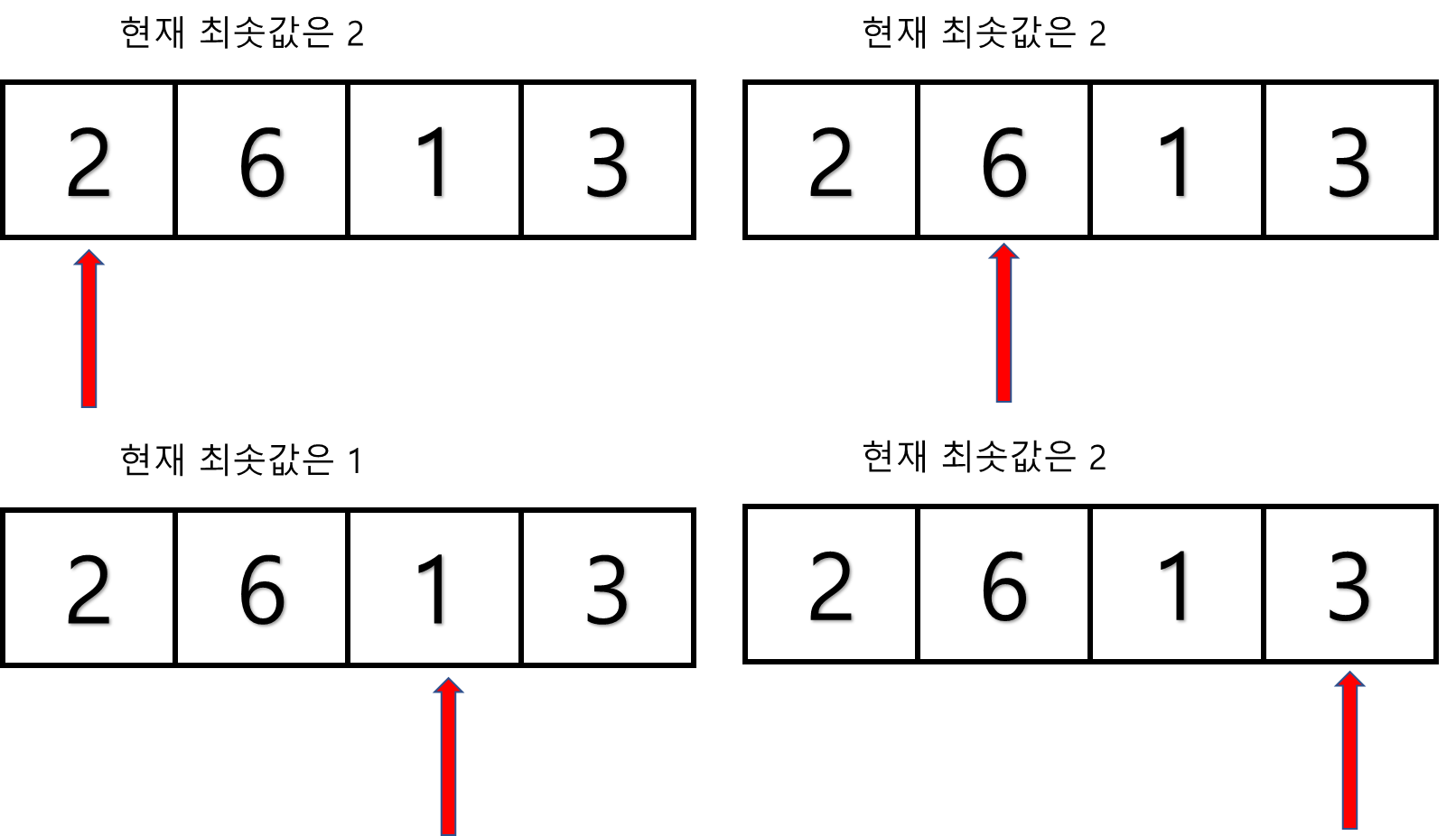
1. 주어진 리스트 중에 최소값을 찾는다.
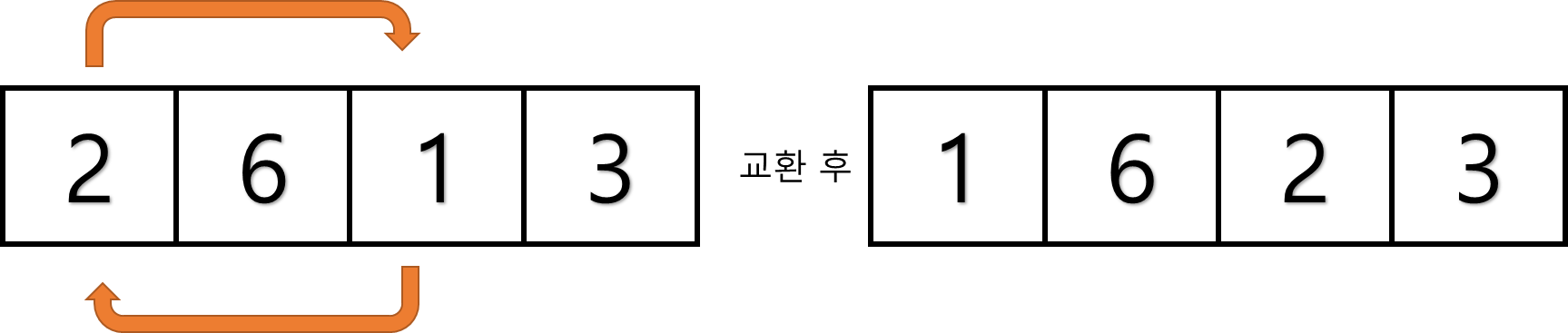
2. 그 값을 맨 앞에 위치한 값과 교체한다(패스(pass)).
3. 맨 처음 위치를 뺀 나머지 리스트를 같은 방법으로 교체한다.
4개의 원소를 가진 배열이 있을 경우
위 과정을 반복하여 정렬한다.
선택 정렬 코드
void selectionSort(int[] list) { int indexMin, temp; for (int i = 0; i < list.length - 1; i++) { indexMin = i; //min값을 찾기 위한 변수 for (int j = i + 1; j < list.length; j++) { if (list[j] < list[indexMin]) { indexMin = j; //값이 더 낮을 경우 저장. } } //교환 temp = list[indexMin]; list[indexMin] = list[i]; list[i] = temp; } }낮은 값을 찾아서 저장하고 교환한다.
선택 정렬 효율성
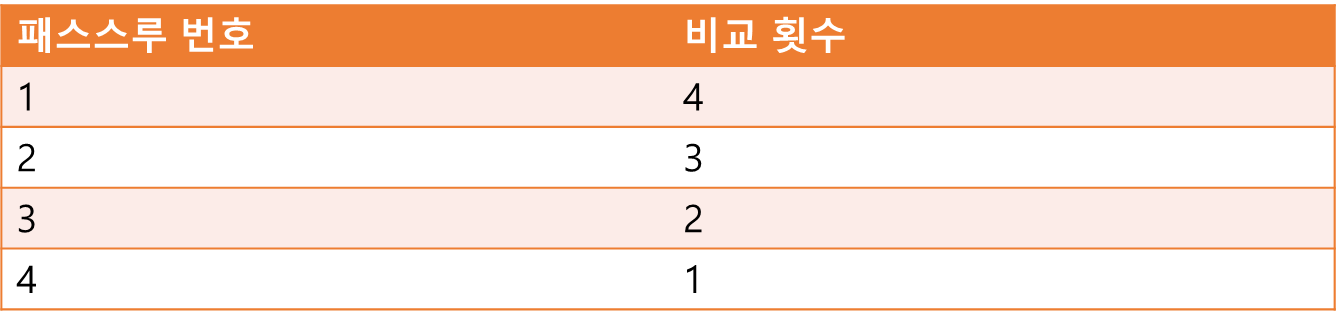
배열의 원소가 5개일 경우 선택 정렬은 비교 횟수
표로 보면 알 수 있듯이 선택 정렬의 비교 횟 수는 다음과 같다.
배열에 원소 N개가 있을 경우 (N-1)+(N-2)....+1번의 비교가 일어난다.
하지만 교환은 이와 달리 단 한번의 교환이 발생한다.
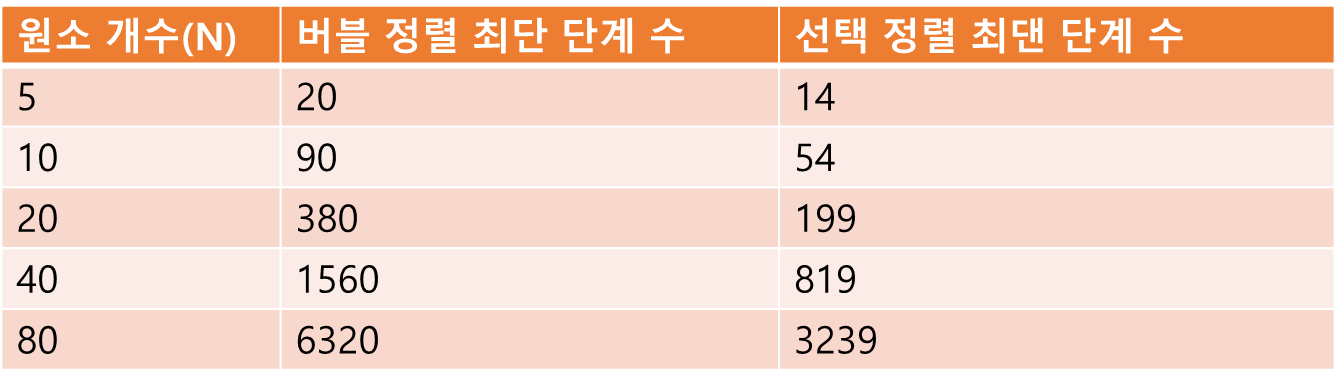
그렇다면 배열이 역순으로 정렬된 최악의 시나리오에서 버블 정렬과 선택 정렬을 비교해보자.
표를 확인하면 선택 정렬이 버블 정렬보다 약 2배는 빠르다는 걸 확인 할 수 있다.
상수 무시하기
하지만 빅오 표기법에서는 버블 정렬과 선택 정렬을 정확히 같은 방식으로 설명한다.
선택 정렬의 효율성을 표기한다면 O(N^2/2) 설명 할 수 있다. 하지만 어째서 O(N^2)으로 표현 할까??
O(N)은 직선 성장을 보여주고, O(N^2)은 지수 성장을 보여준다. 이 때 데이터의 개 수가 점점 무한의 가까워 진다면 다음과 같은 그래프를 그릴 수 있다.
즉 데이터가 커지면 커질 수록 상수는 의미가 적어진다는 걸 알 수 있다. 그렇기에 빅오 카테고리에 상수를 고합다고 해도 카테고리는 변하지 않는다.
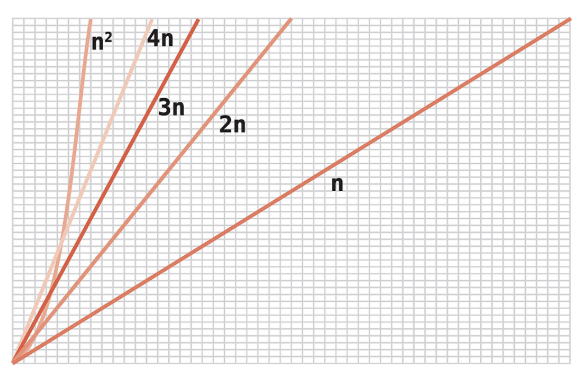
결론
빅 오로 표현 한다면 같은 카테고리에 있을 수 있다.
하지만 이를 단계로 표현하게 된다면 효율성에 차이점이 발생 할 수있다.
그렇기에 빅 오가 같은 카테고리라고 해도, 알고리즘의 효율성은 다를 수 있다.
