Feature Scaling (데이터 스케일링)
데이터 스케일링(Feature Scaling)이란 데이터 전처리 과정의 하나이며, 굉장히 중요한 과정.
-
서로 각기 다른 변수들의 범위 혹은 분포를 일정한 수준으로 같게 만드는 작업.
-
이를 통해 각 변수들이 동일한 조건(혹은 범위)을 가지게 되어, 이 변수들에 대한 상대 비교가 가능.
※ 데이터 스케일링을 해주는 이유
데이터의 값이 너무 크거나 혹은 작은 경우에, 모델 알고리즘 학습과정에서 0으로 수렴하거나 무한으로 발산해버릴 수 있기 때문.
※ 데이터 스케일링의 효과
1. 변수 값의 범위 또는 단위가 달라서 발생 가능한 문제를 예방할 수 있다.
2. 머신러닝 모델이 특정 데이터의 편향성을 갖는 걸 방지할 수 있다.
3. 데이터 범위 크기에 따라 모델이 학습하는 데 있어서 bias가 달라질 수 있으므로, 하나의 범위 크기로 통일해주는 작업이 필요할 수 있다.
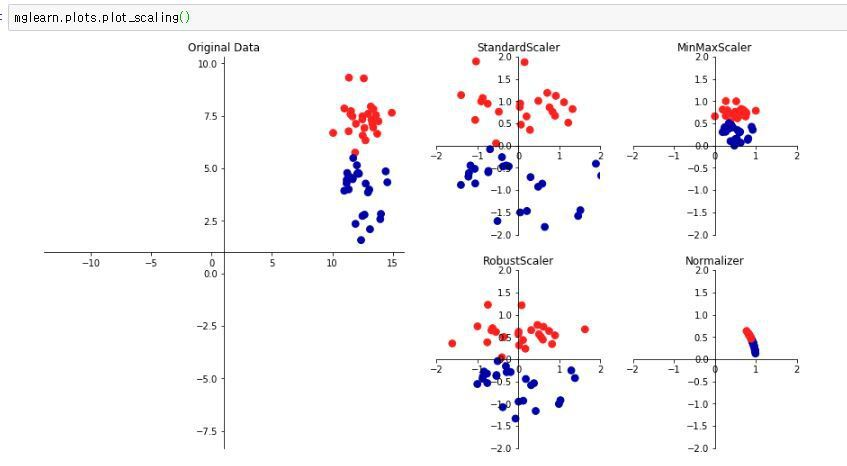
Scaling 과정에는 여러 유형들이 있으나, 그 중에서 가장 대표적인 과정들을 소개한다.
예) StandardScaler, RobustScaler, MinMaxScaler, Normalizer 등
Generalization (일반화)
학습 데이터와 Input data가 달라져도 출력에 대한 성능 차이가 나지 않게 하는 것.
모델의 이미 학습된 데이터 뿐만 아니라, 새로운 외부의 데이터를 모델에 집어 넣어도, 비슷한 결과 값을 갖게 하는 것이 목적.
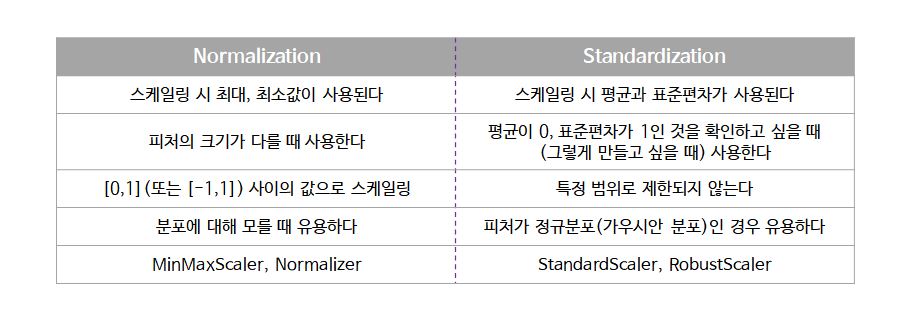
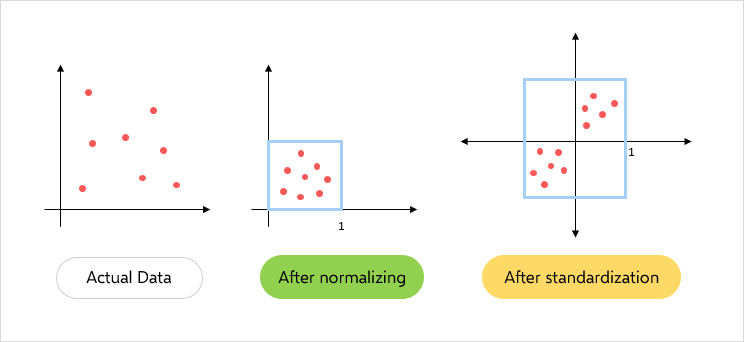
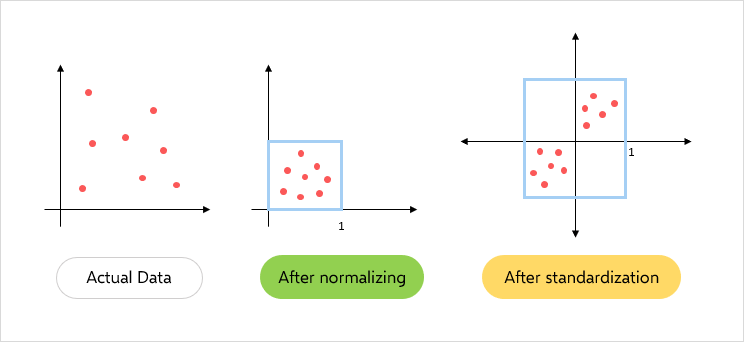
Normalization (정규화)
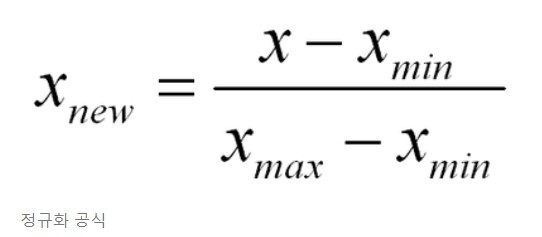
서로 다른 범위의 변수들의 크기를 통일하기 위해 이를 변환하는 작업.
2개 이상의 feature 값에 대해 각각의 value 값을 똑같이 학습할 수 있도록 하는 것이 목적.
※ 일반적으로 [0, 1] 범위의 분포로 조정.
Standardization (표준화)
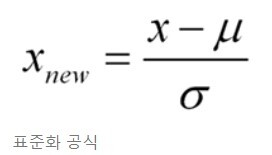
서로 다른 범위의 변수들을 평균이 0, 분산이 1인 가우시안(종 모양) 정규 분포를 가진 값으로 변환하는 작업.
머신러닝에서 사용하는 Support Vector Machine (SVM), Linear Regression, Logistic Regression 모델은 데이터가 가우시안 분포를 가지고 있다고 가정하여 구현되어 있어서, 사전에 학습 데이터에 관해 표준화를 적용하는 것이 모델의 예측 성능 향상에 중요하다.
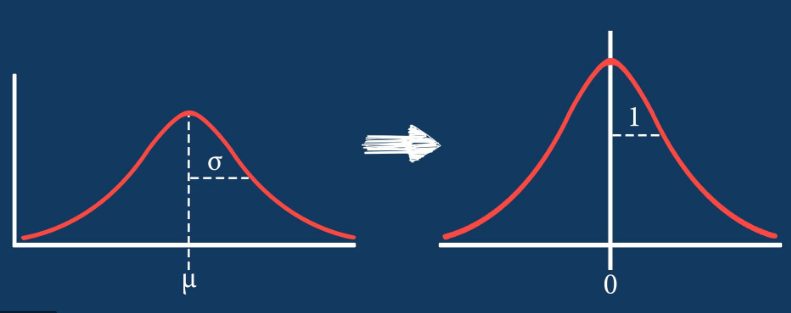
Normalization vs Standardization
normalizaion과 다르게 standardization은 최소값, 최대값을 제한하지 않기 때문에 outlier(이상치)를 파악할 수 있다.