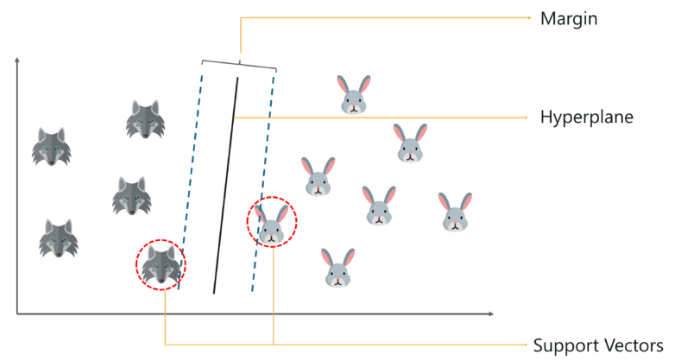
Support Vector Machine (SVM)
결정 경계(Decision Boundary), 즉 분류를 위한 기준 선을 정의하는 모델.
분류되지 않은 새로운 점이 나타나면 경계의 어느 쪽에 속하는지 확인해서 분류 과제를 수행할 수 있게 된다.
분류에 사용되는 지도학습 머신러닝 모델.
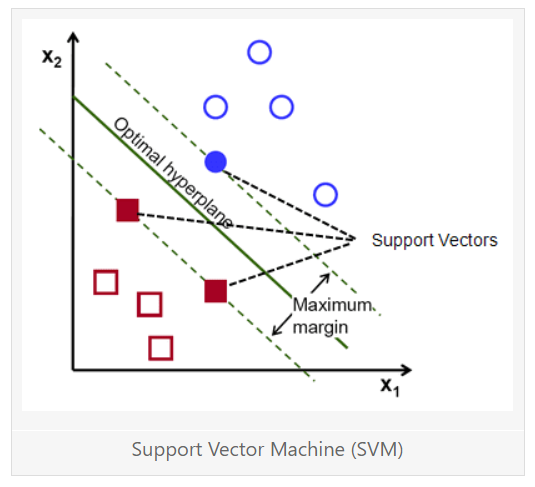
SVM 알고리즘 과정
1) 마진을 극대화하는 최적의 Hyperplane을 선택
2) 잘못된 분류에 대한 페널티를 더함으로써 SVM 손실 함수를 조정
3) 선형으로 분리되지 않는 데이터인 경우에, 선형으로 쉽게 분류할 수 있는 고차원 공간으로 데이터를 변환 (Kernel Trick)
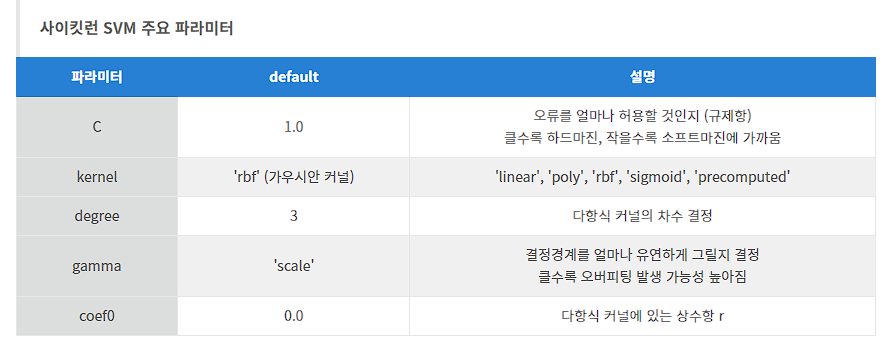
SVM의 Hyper-Parameter
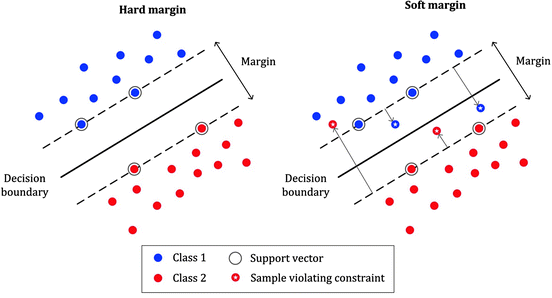
Margin
서포트 벡터와 결정 경계 사이의 거리
파라미터 C는 허용되는 오류 양을 조절한다.
C 값이 클수록 오류를 덜 허용하며 이를 하드 마진(hard margin)이라 부른다.
반대로 C 값이 작을수록 오류를 더 많이 허용해서 소프트 마진(soft margin)을 만든다.
다만 C값이 너무 크면 오버피팅, 너무 작으면 언더피팅이 발생할 수 있으므로 적정값을 찾아야 한다.
Kernel
선형으로 분리할 수 없는 점들을 분류하기 위해 커널(kernel)을 사용
커널(kernel)은 데이터 셋의 형태에 따라 다른데, 원래 가지고 있는 데이터를 더 높은 차원의 데이터로 변환한다.
2차원의 점으로 나타낼 수 있는 데이터를 다항식(polynomial) 커널은 3차원으로, RBF 커널은 점을 무한한 차원으로 변환한다.
선형 데이터셋의 경우 'linear'를, 비선형 데이터셋은 'poly(다항식)', 'rbf(가우시안)'을 주로 사용한다. 다항식 커널은 degree로 차수를 지정해줘야 하며 rbf커널이라면 gamma와 C값 조정이 필수적이다.
SVM 장 & 단점
장점
-
비선형 분리 데이터를 커널트릭을 사용하여 분류 모델링 가능
-
고차원 공간에서 원활하게 작동함 (예측 변수가 많은 경우)
-
텍스트 분류 및 이미지 분류에 효과적임
-
Multicollinearity problem(다중공선성 문제)를 회피함
단점
-
대용량 데이터셋 처리에는 많은 시간이 소요
-
확률 추정치를 직접적으로 반환하지 않음
-
선형 커널은 선형의 분리 가능한 데이터인 경우 로지스틱 회귀분석과 거의 유사함
