XGBoost
GBM은 잔차를 계속 줄이기 때문에 과적합된다는 문제점이 있다.
GBM에 정규화 식 (regularization term)을 추가한 알고리즘
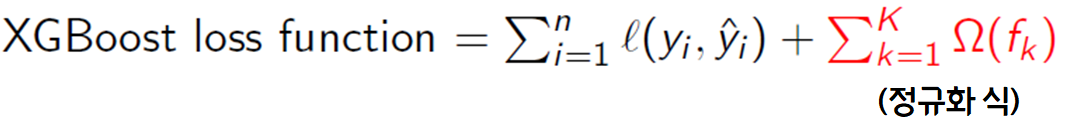
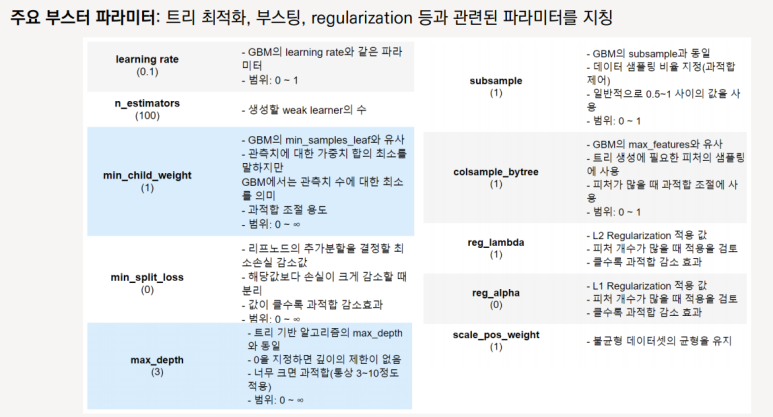
CART를 기반으로 해 분류, 회귀 둘 다 가능
(CART는 모든 리프들이 모델의 최종 스코어에 연관이 있어 최종 스코어를 비교하면 됨.)
<특징>
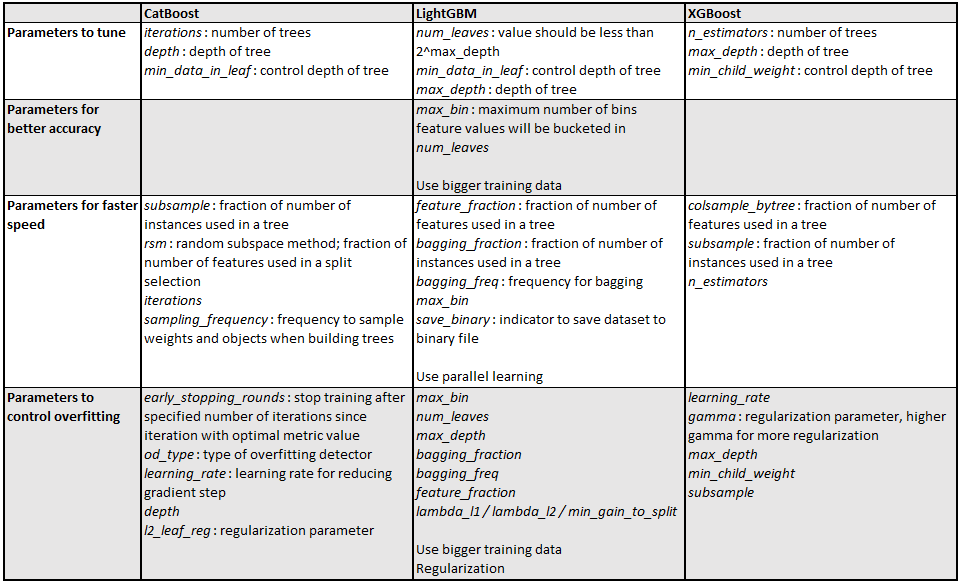
1) 병렬처리를 통한 빠른 학습 → GBM 대비 빠른 수행 시간
2) 유연한 learning system (다양한 loss function 지원)
3) overfitting 방지를 위한 설계 (tree 복잡도↑, loss에 페널티 부여)
4) 다양한 시나리오에 대한 확장성
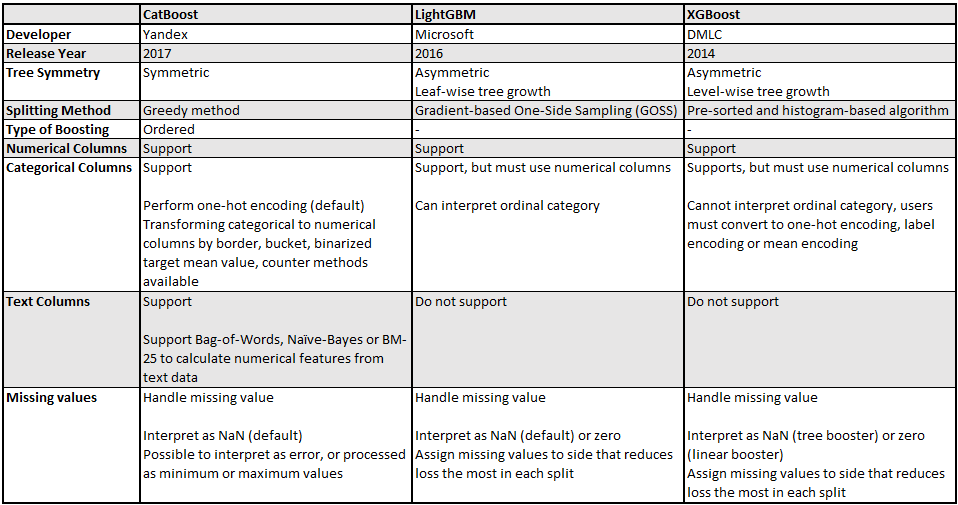
5) 결측치의 내부적 처리
LightGBM
XGBoost의 효율성 문제를 보완하여 나온 알고리즘
→ 기존 효율성 정확도의 trade-off를 해결
기존 알고리즘의 정확도를 유지하면서 훨씬 좋은 효율성
XGBoost 보다 더 간소화, 그러나 예측 성능은 크게 차이를 보이지 않음.
트리 생성 시간 단축 (리프 중심 트리 분할 이용)
다만 10,000개 이하 정도의 적은 데이터에서는 적용할 경우, 과적합이 발생하기 쉽다는 단점이 있음.
LightGBM은 높은 cost 문제를 histogram-based/GOSS/EFB 등의 알고리즘을 통해 tree를 구축하기 위한 scan 데이터 양을 줄임으로써 해결
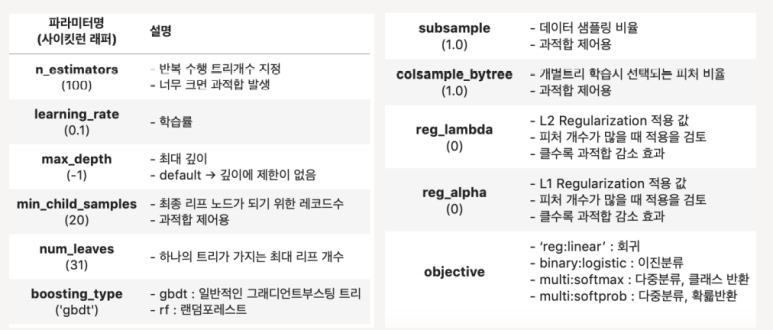
num_leaves의 개수를 중심으로,
min_child_samples, max_depth를 함께 조정하여 모델의 복잡도를 줄이는 것이 기본적.
-
num_leaves : 개별 트리가 가질 수 있는 최대 잎의 개수, 정확도가 높아지지만, 과적합 위험 발생.
-
min_child_samples : (통상적으로) 크게 설정하면 트리가 깊어지는 것을 방지함.
-
max_depth : 깊이의 정도를 제한함.
CatBoost
순서(order)에 따라 모델을 학습시키고 순차적으로 잔차를 계산하는 과정을 반복하는 알고리즘.
범주형(categorical) 변수를 처리하는 데 유용한 알고리즘.
-
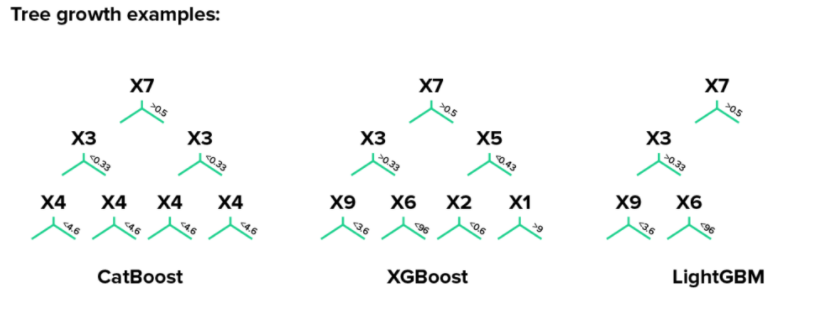
XGBoost와 같은 방식의 Level-wise 트리 방식.
(LightGBM 은 Leaf-wise 트리 방식) -
기존의 부스팅 모델이 일괄적으로 모든 훈련 데이터를 대상으로 잔차계산을 했다면, Catboost 는 일부만 가지고 잔차계산을 한 뒤, 이걸로 모델을 만들고, 그 뒤에 데이터의 잔차는 이 모델로 예측한 값을 사용.
(Ordered Boosting) -
데이터 순서를 섞어주지 않으면 매번 같은 순서대로 잔차를 예측하는 모델을 만들 가능성 때문에 순서를 매번 섞는 과정을 거친다.
(Random Permutation) -
과거의 데이터를 이용해 현재의 데이터를 인코딩 하여, 데이터 부족의 문제를 방지한다.
(Ordered Target Encoding)
이 밖에도 Categorical Feauture Combinations, One-hot Encoding, Optimized Parameter tuning 의 방식을 이용하는 특징을 갖고 있다.
<장점>
- 다른 GBM에 비해 overfitting이 적다.
- 범주형 변수에 대해 특정 인코딩 방식으로 인해, 모델의 정확도와 속도가 높다.
<한계점>
- 결측치가 많은 데이터셋은 처리하지 못한다.
- 데이터 대부분이 수치형 변수인 경우, LightGBM 보다 학습 속도가 느리다.
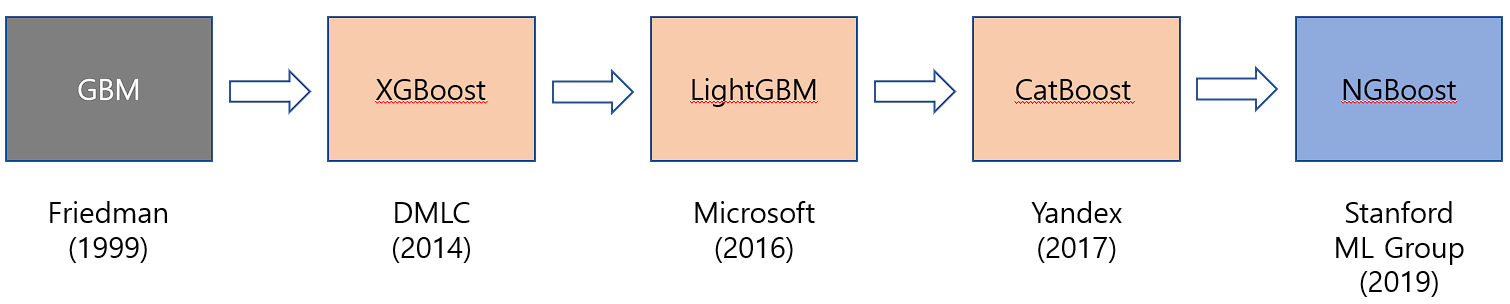
각 부스팅 알고리즘 별 비교
ref )
https://soobarkbar.tistory.com/41
https://blog.naver.com/PostView.naver?blogId=hajuny2903&logNo=222422524636&parentCategoryNo=&categoryNo=24&viewDate=&isShowPopularPosts=false&from=postView
