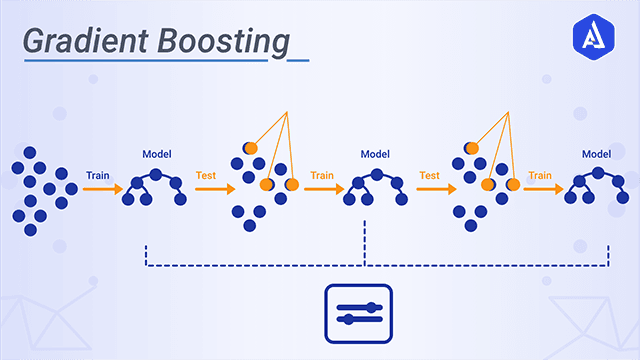
Boosting
여러 개의 약한 학습기(weak learner)를 순차적으로 학습/예측하며 잘못 예측한 데이터에 가중치 부여를 통해 오류를 개선해 나가면서 학습하는 방식.
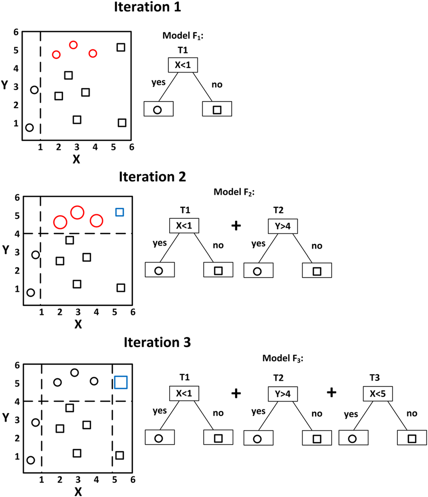
Residual Error (잔차)
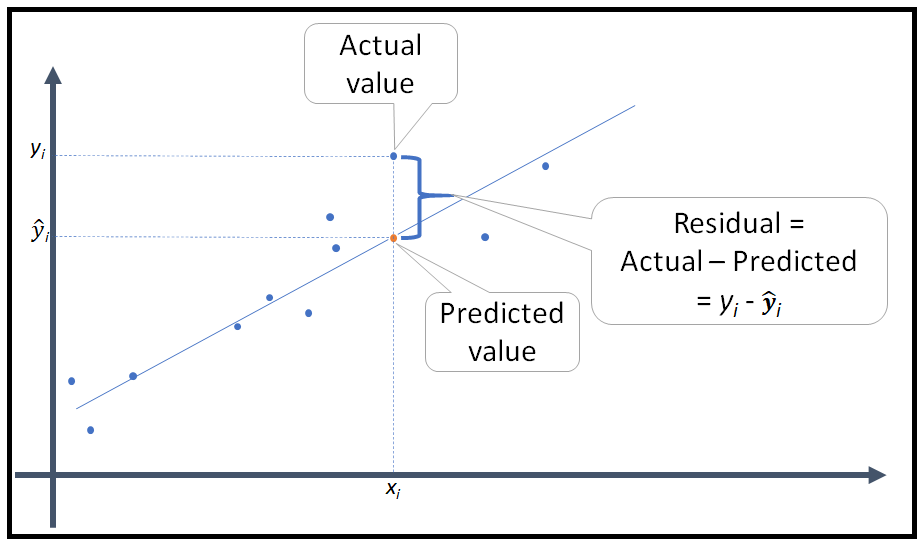
실제 값들의 평균과 실제 값의 차이
residual에 fitting해서 다음 모델을 순차적으로 만들어 나가는 것
→ negative gradient를 이용해 다음 모델을 순차적으로 만들어 나가는 것
gradient boosting은 다음 모델을 만들 때, negative gradient를 이용
※ 아래에서 설명할 Gradient Boosting Mach은 바로 이 잔차를 줄이기 위해 반복 학습을 거치는 과정, 기법이라고 할 수 있다.
Gradient Descent (경사 하강법)
함수 값이 낮아지는 방향으로 이동하며 최솟값을 탐색하는 방식
→ 아무 것도 보이지 않는 산에서 낮아지는 방향으로 이동하여 한 발자국 씩 산을 내려가는 방법.
기울기가 양수: 가 커질수록 값이 커짐
기울기가 음수: 가 커질수록 값이 작아짐
기울기 부호의 반대로 움직여야 최솟값으로 가는 방향
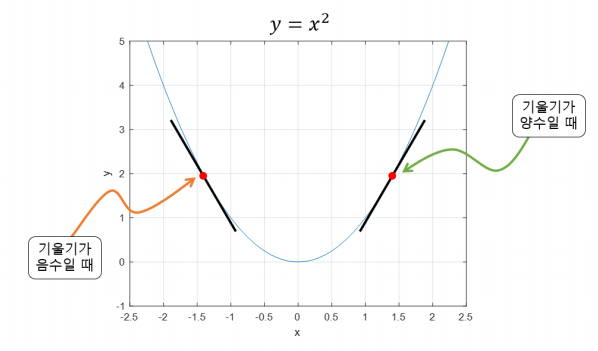
※ 아래에서 설명할 Gradient Boosting Machine은 경사 하강법의 방식을 이용하여 가중치를 업데이트 한다.
Gradient Boosting Machine (GBM)
회귀 또는 분류 분석을 수행할 수 있는 예측모형, 예측모형의 앙상블 방법론 중 부스팅 계열에 속하는 알고리즘
GBM은 계산량이 상당히 많이 필요한 알고리즘
→ 하드웨어에 부담이 많이 가는 알고리즘
- 대표적으로 LightGBM, CatBoost, XGBoost 같은 파이썬 패키지들이 모두 하드웨어 효율적으로 구현하는 패키지들이다.
가중치 업데이트의 방식은 경사하강법(Gradient Descent)을 이용
오류값은 (실제값 - 예측값, residual error)이 되고 이 오류 식을 최소화하는 방향으로 반복적으로 가중치를 업데이트
장점 - 뛰어난 예측 성능
단점 - 너무 오래 걸리는 학습시간 (순차적으로 진행하기 때문)
과적합의 위험
※ y = 𝑓 𝑥 + 𝜀 : 노이즈까지 학습해버리기 때문
※ GBM에서 loss function은 주로 MSE , L1 loss, Logistic loss가 사용
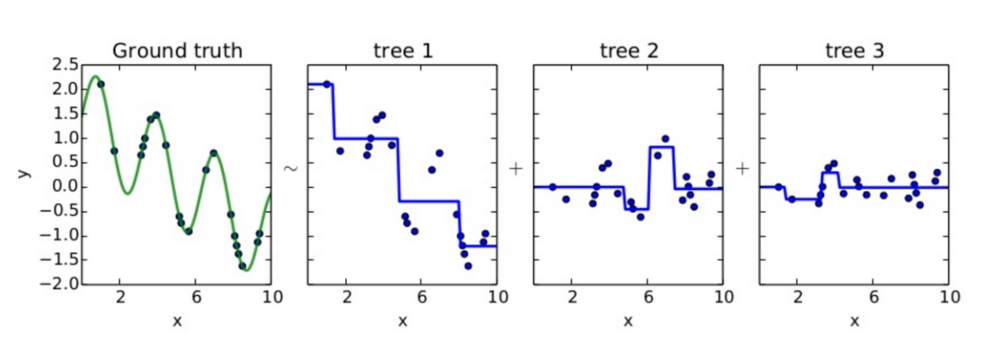
앙상블에 이전까지의 오차를 보정하도록 예측기를 순차적으로 추가한다.
그리고 이전 예측기가 만든 residual error에 새로운 예측기를 학습시킨다.
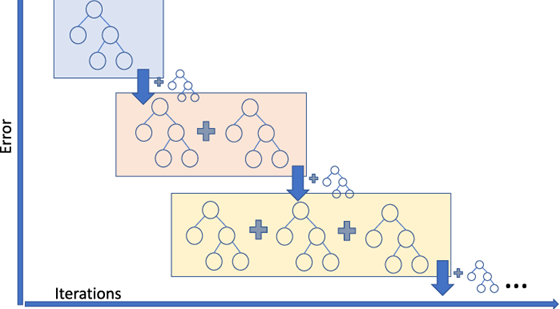
과정
weak learner로는 tree model을 사용
. 로 초기 예측값을 준다.
. 학습을 진행하는데 1 ~ 번 iteration을 돌린다.
(A) 앞서 정의한 loss를 미분해서 negative gradient = residual을 구한다.
(B) (A)에서 구한 residual을 target으로 하는 tree model (weak learner) 만들고 fitting 시킨다.
(C) loss를 최소로 하는 tree 결과값을 출력한다. (이 과정은 생략되기도 한다)
(D) tree로 fitting 시켜서 구한 residual로 기존 예측값()을 update 한다.
이 때, gradient descent 알고리즘과 비슷하게 learning rate를 준다.
. 위 과정을 iteration 횟수만큼 반복 한 뒤, 최종 예측값을 출력한다.
