
계기
안녕하세요, 오늘은 k6를 이용한 데이터 처리 최적화 과정에 대해서 알아보고자 합니다,
일단 이 포스팅을 하게 된 계기로는 최근에 서비스를 만들면서 그렇게 많은 데이터가 아님에도 불구하고
api 응답 속도가 조금 느려서 프론트에서 로딩창을 만들어주어야 하는 상황이 발생했었습니다,
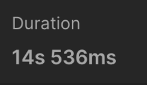
(실제로 14초나 걸린건 아닙니다)
때문에 굳이 로딩창을 만들 필요 없을 정도로 빠르게 api가 응답했으면 좋겠다 싶은 마음에
데이터 처리 과정에서 어떤 점들을 숙지하면 더 빠르게 데이터를 처리할 수 있는지, 알아보고자
포스팅을 하게 됐습니다,
참고로 저가 아직 프론트가 많이 미흡해서(백엔드도 미흡함..) API를 받을 떄 백엔드 성능 최적화 말고도
프론트에서 더 적절하게 처리할 수도 있었을 거 같은데.. 아쉬운 점이 많습니다
우선, 데이터 처리 최적화 과정을 하기에 앞서 모든 환경을 동일하게 맞춰주어야 하는데요,
1. post 객체를 호출함 (id, title, content을 포함)
2. 이때 300만개의 post 데이터를 가져옴
3. 300만개의 데이터를 가져올 때 걸리는 시간을 측정이 순서로 어떤식으로 최적화하면 데이터 처리 속도가 점점 빨라지는지 확인해보도록 하겠습니다.
측정하기
Post 엔티티 만들기
@Entity
@Setter
@Getter
public class Post {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY) // 이 부분은 자동 생성되는 경우에 사용합니다.
private Long id;
private String title;
private String content;
// 생성자
public Post(String title, String content) {
this.title = title;
this.content = content;
}
// getter와 setter
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
}PostController 만들기
@RestController
public class PostController {
@GetMapping("/posts")
public List<Post> getPosts() {
List<Post> posts = new ArrayList<>();
for (int i = 0; i < 3000000; i++) {
posts.add(new Post("Title " + i, "Content of post " + i));
}
return posts;
}
}k6 활용해서 측정하기
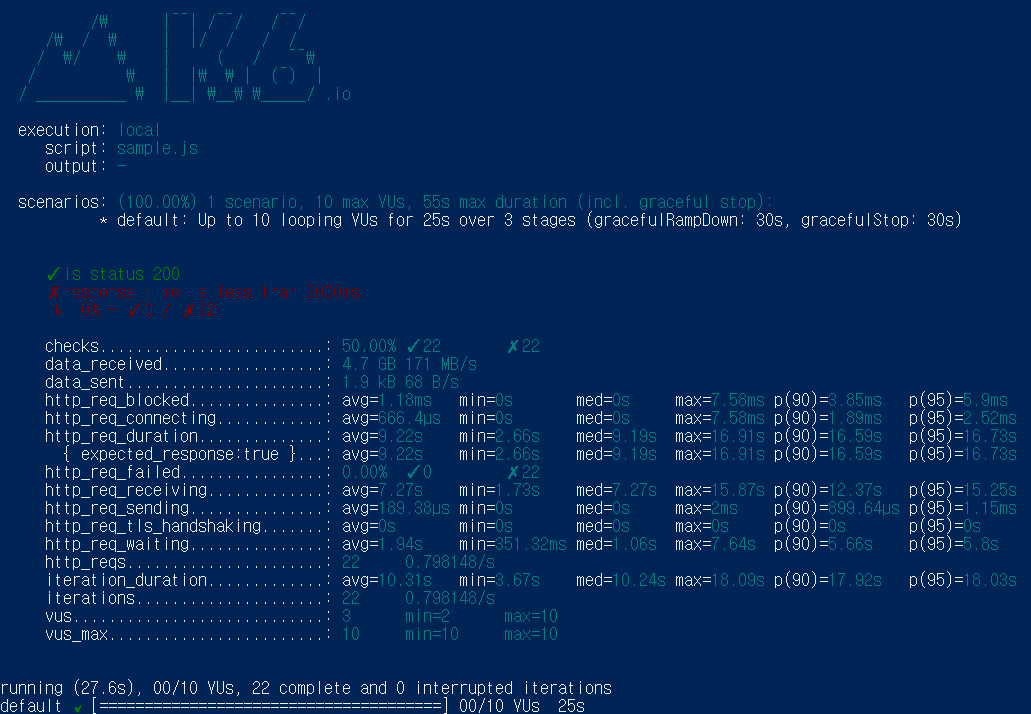
위 내용을 보면 평균적인 응답 속도는 9.22s 로 가장 적을때는 2.66s 가장 클 떄는 16.91s 정도 걸립니다..
평균적으로 약 9초 정도 데이터를 가져오는데 시간이 걸리기 때문에 만약 실제 서비스에서 이정도 속도라면
모든 사용자들이 나갈 거 같습니다.. 지금부터 속도를 더 줄여보도록 합시다 !
컬렉션 최적화
ArrayList는 초기 용량이 작으면 자주 리사이즈를 해야 하므로,
초기 용량을 크게 설정합니다. 예: new ArrayList<>(3000000).
@RestController
public class PostController {
@GetMapping("/posts")
public List<Post> getPosts() {
List<Post> posts = new ArrayList<>(3000000); // 초기 용량 설정
for (int i = 0; i < 3000000; i++) {
posts.add(new Post("Title " + i, "Content " + i)); // 데이터 타입 최적화 가능
}
return posts;
}
}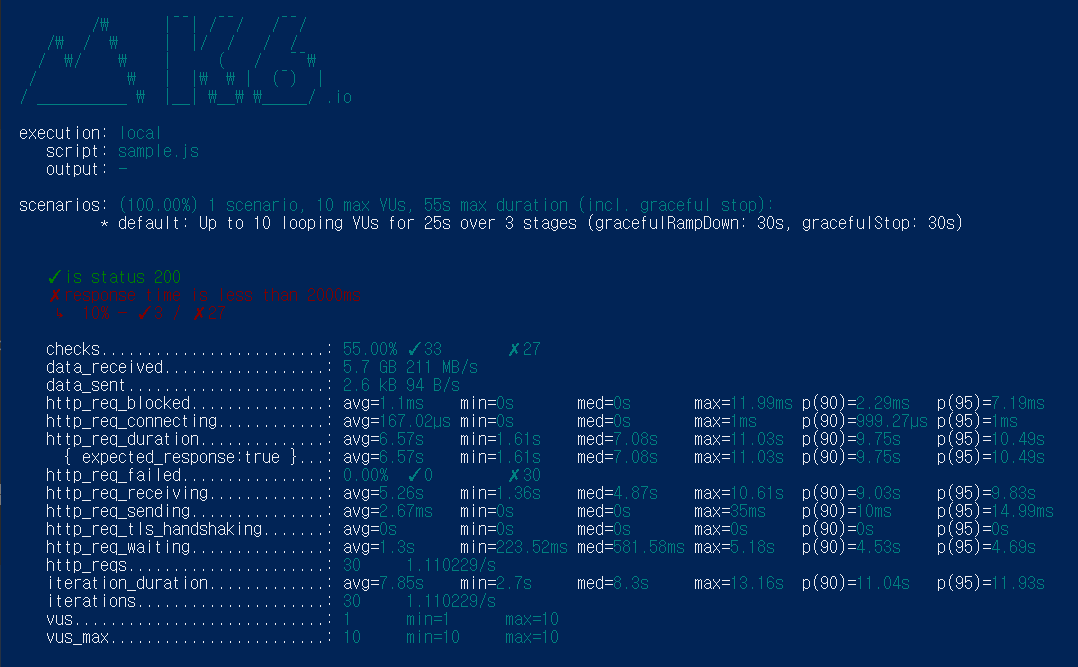
ist<Post> posts = new ArrayList<>(3000000); // 초기 용량 설정컬렉션을 최적화 해준 것 만으로도 약 3초 정도 단축시켜 평균 6.57s 정도에
응답하고 있습니다, 가장 적은 값은 1.61s, 가장 큰 값은 11.03s로 아직까지도
실제 서비스 환경에서는 적절하지 않은 속도입니다. 더 줄여보도록 합시다 !
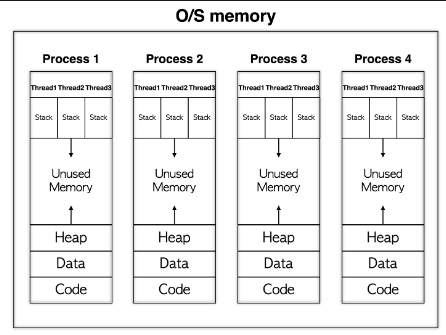
멀티스레딩 활용
멀티스레딩이란?
멀티스레딩이라는 단어 개발을 하면 많이 듣게 되실텐데요.. 정확하게 어떤 뜻일까요?
멀티스레딩은 프로그램 또는 프로세스가 동시에 여러 작업을 수행할 수 있게 해주는 기술입니다.
멀티스레딩을 통해 컴퓨터의 여러 코어를 효율적으로 사용하여 성능을 향상시킬 수 있습니다.
스레드란
- 스레드는 프로세스 내에서 실행되는 독립적인 실행 단위입니다.
- 한 프로세스 내에서는 여러 스레드가 동시에 실행되며 이들은 프로세스의 자원
(메모리, 파일 등)을 공유합니다.
멀티스레드의 장점
- 자원 효율 : 한 프로세스 내에서 자원을 공유하기에 메모리 사용이 효율적입니다
- 성능 향상 : 여러 작업을 동시에 처리할 수 있기에 CPU 사용률을 극대화합니다
- 응답성 향상 : 한 스레드가 긴 작업을 처리하는 동안 다른 스레드가 사용자 상호작용과
같은 작업을 계속해서 처리할 수 있습니다.
멀티스레드의 단점
- 동기화 문제 : 여러 스레드가 같은 자원에 동시에 접근하려 할 때 발생할 수 있는 문제입니다,
이를 관리하기 위해서는 락(Lock)이나 세마포어(semaphore) 같은 동기화 매커니즘이 필요합니다, - 교착 상태(데드락) : 여러 스레드가 서로의 자원을 기다리며 무한히 대기하는 상태로
설계시 주의해야하는 점입니다,(나중에 추가로 포스팅 할까 싶습니다)
멀티스레딩은 병렬 처리를 통해 데이터 처리 속도를 향상시킬 수 있는 효과적인 방법입니다. Java에서는 ExecutorService와 같은 도구를 사용하여 멀티스레딩을 구현할 수 있습니다.
테스트 해보기
package nginxtest.demo.domain.post.entity;
import jakarta.persistence.Entity;
import jakarta.persistence.GeneratedValue;
import jakarta.persistence.GenerationType;
import jakarta.persistence.Id;
import lombok.Getter;
import lombok.Setter;
@Entity
@Setter
@Getter
public class Post {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String title;
private String content;
public Post(String title, String content) {
this.title = title;
this.content = content;
}
}
@RestController
public class PostController {
private static final int THREAD_COUNT = 10;
private static final int POST_COUNT = 3000000; // 총 포스트 수
@GetMapping("/posts")
public List<Post> getPosts() {
ExecutorService executor = Executors.newFixedThreadPool(THREAD_COUNT);
List<Future<List<Post>>> futures = new ArrayList<>();
for (int i = 0; i < THREAD_COUNT; i++) {
int finalI = i;
futures.add(executor.submit(() -> getPostChunk(finalI)));
}
List<Post> allPosts = new ArrayList<>();
for (Future<List<Post>> future : futures) {
try {
allPosts.addAll(future.get());
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
}
executor.shutdown();
return allPosts;
}
private List<Post> getPostChunk(int chunkNumber) {
int chunkSize = POST_COUNT / THREAD_COUNT;
int start = chunkNumber * chunkSize;
int end = (chunkNumber + 1) * chunkSize;
List<Post> posts = new ArrayList<>(chunkSize); // 초기 용량 설정
for (int i = start; i < end; i++) {
posts.add(new Post("Title", "Content")); // 메모리 사용 최적화
}
return posts;
}
}먼저 멀티스레딩을 구현해야하는데요, ExceutorService를 사용해볼려고 합니다,
ExceutorService란 여러 작업(Threads)를 효율적으로 관리할 수 있는 Java의 내장 유틸리티입니다.
그러므로 코드 실행 순서를 한번 알아봅시다.
1. Exceutors를 이용해 고정된 수의 스레드 풀을 생성합니다.
2. Post_count 만큼의 post 객체를 생성하고 Thread_count 만큼의 스레드에 분배하여 병렬처리 합니다.
3. 각 스레드는 getPostChunk 메서드를 호출하여 일정 범위의 Post 객체를 생성하고 리스트로 반환.
4. 각 스레드의 결과는 'Future' 객체에 저장되어 모든 스레드가 완료되면 결과가 병합됩니다.
5. 'future.get()'을 호출하여 각 스레드의 결과를 가져오며, 이 과정에서 발생할 수 있는 예외를 처리합니다.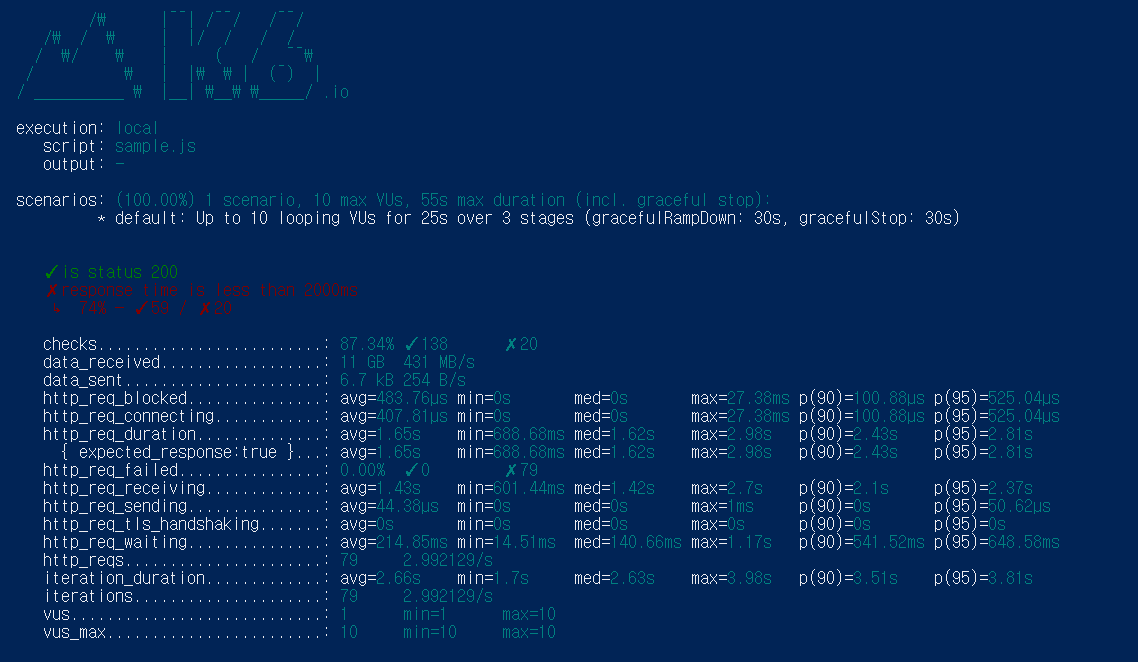
멀티스레딩을 사용함으로써 평균 응답 속도가 1.65s 까지 줄어들었습니다,
약 6.5s -> 1.5s로 5초정도 줄어들었는데요, 하지만 가장 작은 경우 668ms, 가장 큰 경우 2.98s로
여전히 가장 큰 경우는 2s를 초과하여 실제 서비스 환경에서 사용은 가능하겠지만 적절한 속도는 아닌 거 같습니다, 그러므로 여기서 추가로 더 줄여보도록 합시다 !
캐싱활용
캐싱이란?
캐싱은 데이터 최적화 부분에서 빠지지 않는 단어인데요, 캐싱을 요약하자면
자주 사용하는 데이터를 빠르게 접근할 수 있도록 메모레에 저장하는 기법
캐싱을 사용하게 되면 DB나 파일 시스템과 같이 느린 저장소에 매번 접근하는 것보다 데이터를 훨신 빠르게 검색할 수 있습니다, 그러니 캐싱의 주 목표는 애플리케이션의 성능을 향상시키고, 응답 시간을 단축하는 것 입니다.
캐싱의 특징
- 데이터 저장 : 자주 요청되는 데이터 또는 계산 결과를 메모리에 저장합니다
- 데이터 재사용 : 동일한 요청이 들어올 경우 저장된 데이터를 재사용하여 빠른 응답을 제공합니다
- 캐시 만료 : 저장된 데이터가 오래되거나 변경되면 캐시를 업데이트하거나 제거해야 합니다.
그리고 추가로 간단한 구현의 경우 ConcurrentHashMap과 같은 자바 컬렉션을 사용해도 되지만
복잡한 요구 사항을 가지고 있는 경우 Redis는 Memcached 같은 전용 캐싱 시스템을 사용하는 것이
보통의 방법입니다.
테스트 해보기
@Component
public class PostCache {
private Map<String, List<Post>> cache = new ConcurrentHashMap<>();
public List<Post> getPosts(String key) {
return cache.getOrDefault(key, new ArrayList<>());
}
public void savePosts(String key, List<Post> posts) {
cache.put(key, posts);
}
}@RestController
public class PostController {
private static final int POST_COUNT = 3000000; // 총 포스트 수
private PostCache postCache = new PostCache(); // 캐시 인스턴스 생성
@GetMapping("/posts")
public List<Post> getPosts() {
String cacheKey = "posts";
List<Post> cachedPosts = postCache.getPosts(cacheKey);
if (!cachedPosts.isEmpty()) {
return cachedPosts; // 캐시된 데이터 반환
}
int coreCount = Runtime.getRuntime().availableProcessors(); // CPU 코어 수에 맞춘 스레드 풀 크기
ExecutorService executor = Executors.newFixedThreadPool(coreCount);
List<Future<List<Post>>> futures = new ArrayList<>();
for (int i = 0; i < coreCount; i++) {
int finalI = i;
futures.add(executor.submit(() -> getPostChunk(finalI, coreCount)));
}
List<Post> allPosts = new ArrayList<>();
for (Future<List<Post>> future : futures) {
try {
allPosts.addAll(future.get());
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
}
executor.shutdown();
postCache.savePosts(cacheKey, allPosts); // 결과를 캐시에 저장
return allPosts;
}
private List<Post> getPostChunk(int chunkNumber, int coreCount) {
int chunkSize = POST_COUNT / coreCount;
int start = chunkNumber * chunkSize;
int end = (chunkNumber + 1) * chunkSize;
List<Post> posts = new ArrayList<>(chunkSize);
for (int i = start; i < end; i++) {
posts.add(new Post("Title", "Content"));
}
return posts;
}
}- PostCache 클래스 도입
- 내부적으로 ConcurrentHashMap을 사용해서 'Post' 객체의 리스트를 캐시함
- 'getPosts' 메서드를 이용해 캐시에서 키에 해당하는 포르스 리스트를 가져올 수 있음
- 'savePosts' 메서드로 새로운 포스트 리스트를 캐시에 저장가능함
- 캐싱 로직 추가
- 'getPosts" 메서드에서 캐시를 확인 후 데이터가 있을 경우 즉시 반환하여 데이터 생성 로직을 스킵할 수 있음
- 데이터가 캐시에 없는 경우 멀티스레딩을 통해 데이터를 생성 후 생성한 데이터는 캐시에 저장
- 성능 최적화
- 캐싱을 통해서 대량의 데이터를 처리할 때 응답 시간을 단축시킬 수 있었음.
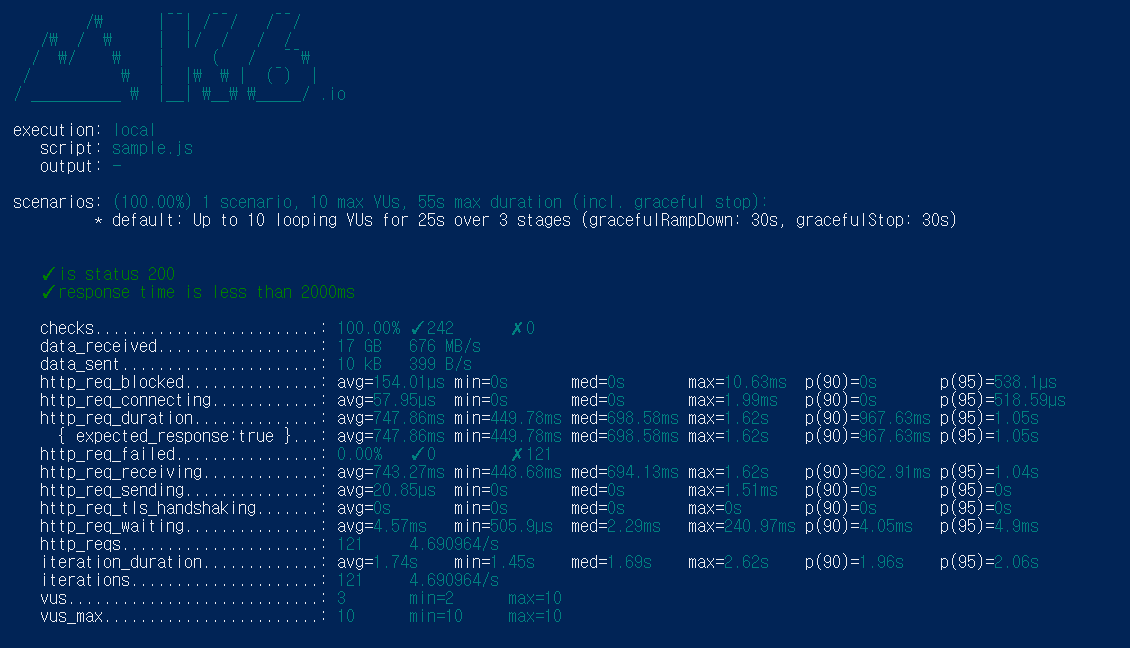
이렇게 캐싱까지 사용해서 데이터 처리를 최적화 해봤는데요,
캐싱을 이용하네 평균 747ms로 약 1.5s 에서 절반 정도로 단축할 수 있었으며
가장 큰 응답시간 역시 1.62s로 이전 응답 시간의 평균보다 아주 조금 높은 수준을
보여주고 있습니다.
Service 레이어 나누기
그리고 포스팅을 마치기 전에 Controller에서 너무 많은 처리를 하기에 좀 나눠주겠습니다.
@RestController
@RequiredArgsConstructor
public class PostController {
private final PostService postService;
@GetMapping("/posts")
public ResponseEntity<List<Post>> getPosts() {
List<Post> posts = postService.getPosts();
return ResponseEntity.ok(posts);
}
}public interface PostService {
List<Post> getPosts();
}@Service
@RequiredArgsConstructor
public class PostServiceImpl implements PostService {
private static final int POST_COUNT = 3000000; // 총 포스트 수
private final PostCache postCache; // 캐시 인스턴스
public List<Post> getPosts() {
String cacheKey = "posts";
List<Post> cachedPosts = postCache.getPosts(cacheKey);
if (!cachedPosts.isEmpty()) {
return cachedPosts;
}
List<Post> allPosts = processPosts();
postCache.savePosts(cacheKey, allPosts);
return allPosts;
}
private List<Post> processPosts() {
int coreCount = Runtime.getRuntime().availableProcessors();
ExecutorService executor = Executors.newFixedThreadPool(coreCount);
List<Future<List<Post>>> futures = new ArrayList<>();
for (int i = 0; i < coreCount; i++) {
int finalI = i;
futures.add(executor.submit(() -> getPostChunk(finalI, coreCount)));
}
List<Post> allPosts = new ArrayList<>();
for (Future<List<Post>> future : futures) {
try {
allPosts.addAll(future.get());
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
}
executor.shutdown();
return allPosts;
}
private List<Post> getPostChunk(int chunkNumber, int coreCount) {
int chunkSize = POST_COUNT / coreCount;
int start = chunkNumber * chunkSize;
int end = (chunkNumber + 1) * chunkSize;
List<Post> posts = new ArrayList<>(chunkSize);
for (int i = start; i < end; i++) {
posts.add(new Post("Title", "Content"));
}
return posts;
}
}감사합니다.
utils 나누기
public class PostUtils {
public static ExecutorService createFixedThreadPool(int coreCount) {
return Executors.newFixedThreadPool(coreCount);
}
public static List<Post> getPostChunk(int chunkNumber, int chunkSize) {
int start = chunkNumber * chunkSize;
int end = (chunkNumber + 1) * chunkSize;
List<Post> posts = new ArrayList<>(chunkSize);
for (int i = start; i < end; i++) {
posts.add(new Post("Title", "Content"));
}
return posts;
}
}@Service
@RequiredArgsConstructor
public class PostServiceImpl implements PostService {
private static final int POST_COUNT = 3000000; // 총 포스트 수
private final PostCache postCache; // 캐시 인스턴스
public List<Post> getPosts() {
String cacheKey = "posts";
List<Post> cachedPosts = postCache.getPosts(cacheKey);
if (!cachedPosts.isEmpty()) {
return cachedPosts; // 캐시된 데이터 반환
}
List<Post> allPosts = processPosts();
postCache.savePosts(cacheKey, allPosts);
return allPosts;
}
private List<Post> processPosts() {
int coreCount = Runtime.getRuntime().availableProcessors(); // CPU 코어 수에 맞춘 스레드 풀 크기
ExecutorService executor = createFixedThreadPool(coreCount);
List<Future<List<Post>>> futures = new ArrayList<>();
for (int i = 0; i < coreCount; i++) {
int finalI = i;
futures.add(executor.submit(() -> getPostChunk(finalI, POST_COUNT / coreCount)));
}
List<Post> allPosts = new ArrayList<>();
for (Future<List<Post>> future : futures) {
try {
allPosts.addAll(future.get());
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
}
executor.shutdown();
return allPosts;
}
}얼마나 단축되었는지
이로써 최적화를 통해서
9.22s에서 747.86ms까지 http duration을 줄일 수 있었습니다
즉 91.9%의 성능 향상을 이루었으며, 약 12배 정도 성능이 향상되었습니다 !
