
안녕하세요, 오늘은 HashMap에 대해서 알아보고자 합니다,
사실 HashMap이 뭔지는 이미 알고 있지만 저가 알고 있는게 정확한지(사실 야매로 알고있음)
한 번 복기하는 용도 + HashMap에 대해서 더 자세히 알고자 포스팅 하게 됐습니다.

HashMap이란?
요약
일단 HashMap을 정의하자면
Key와 Value이라는 쌍으로 된 데이터를 저장하는 자료구조입니다.
이때 각 키는 고유해야하며 이를 사용하여 빠르게 데이터를 검색할 수 있는데요,
과거 POCU 아카데미에서 실습 과정을 했을 때 HashMap을 통해서 LRU Cache를 구현해서
유통기한이 지난 제품들을 바꾸는 코드를 작성한 적이 있어 아직까지 기억하고 있습니다..
(아닐수도 있음)
여튼 HashMap은 내부적으로 배열을 사용해서 데이터를 저장하게 되는데
키의 해시코드를 사용하여 값을 저장하고 검색하는 위치를 결정할 수 있습니다,
해시코드란?
해시코드란 객체를 식별하는 하나의 고유 정수값을 의미합니다즉 해시코드는 식별자라고 생각하면 되는데 자바의 최상의 클래스인
Object 클래스의 hashCode() 메소드가 바로 객체의 hashcode를 반환합니다.

아 그리고 HashMap을 사용하면 내부적으로 해시 함수를 알아서 사용하는데요
해시 함수란 키 -> 해시값 -> 인덱스 -> 데이터 저장 또는 검색
이 순서로 동작하며 간단하게 말 그대로 key 값을 value로 변환시켜주는 함수라고 생각하면 됩니다.
만약에 두 개 이상의 키가 동일한 해시값을 가지면 어떻게 될까요?
앞서 말했듯이 HashMap은 key와 Value로 이루어진 하나의 쌍이라고 했습니다,
근데 해시값을 같으면 동일한 인덱스를 저장또는 검색하게 될 겁니다 이거를 예를 들자면
Apple(key) -> 동일한 해시값 -> fruit(value)
orange(key) -> 동일한 해시값 -> fruit(value)이런 문제가 발생합니다, 근데 그래서 충돌되면 뭐가 안 좋을까요?
orange의 값을 바꾸면 Apple의 값도 같이 바뀌는 엄청난 문제를 발생시킬까요?
사실 해시 충돌 자체는 데이터 값에 직접적인 오류를 발생시키진 않습니다.
하지만 왜 해시 충돌에 대해서 알고는 있어야 할까요?
- 성능 저하
- 충돌이 많이 발생하면 같은 해시값을 갖는 키들을 식별하기 위해
추가적인 비교 연산이 필요합니다.
- 충돌이 많이 발생하면 같은 해시값을 갖는 키들을 식별하기 위해
- 메모리 사용
- 성능 저하 때문에 "체이닝 기법" 같은걸 써야 하는데 이때
동일한 해시값을 가진 항목들에 대해서 연결 리스트로 관리하게 됩니다
덕분에 리스트가 길어지면 성능이 저하됩니다.
- 성능 저하 때문에 "체이닝 기법" 같은걸 써야 하는데 이때
- 오버플로우 발생
- 해시 충돌이 발생하면 충돌이 일어난 주소에 레코드가 추가로 담기는데
이때 공간이 충분하지 않으면 오버플로우가 발생합니다.
- 해시 충돌이 발생하면 충돌이 일어난 주소에 레코드가 추가로 담기는데
해시 충돌 해결법
-> 체이닝 기법
체이닝 기법 - 연결 리스트만 사용해주면 됨
private LinkedList<KeyValue>[] table; // 각 버킷에 연결 리스트로 데이터 저장해시 테이블과 해시 맵의 차이는?
근데 HashMap에 대한 포스팅을 하면서 새로 알게된 사실이 있습니다.. 사실 저는 해시 테이블과 해시 맵의 차이점에 대해서 정확하게 설명할 수 없었습니다 근데 이번 포스팅을 하면서 추가로 공부하게 됐는데.. 좀 애매한 관계인 거 같습니다
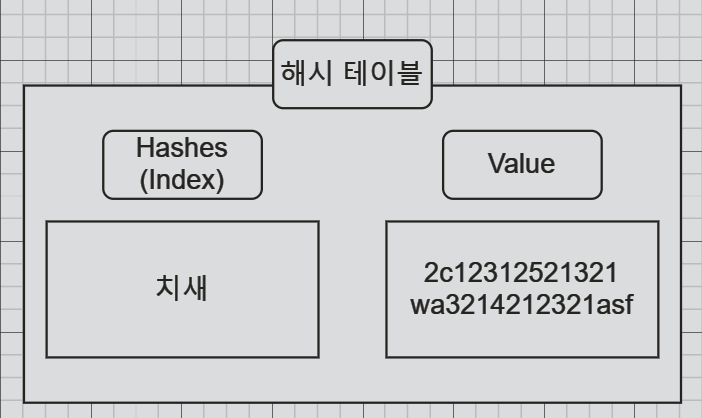
해시 테이블 (Hash Table)
- 해시 테이블은 키를 값에 매핑하는 자료구조인데요
이 자료구조의 핵심 기능은 해시 함수를 사용해서 키를 해시값으로 변환하고
해시값을 인덱스로 사용해서 데이터를 배열 같은 내부 구조에 저장하는겁니다..
위에서 본 내용과 동일하지 않나요?

해시 맵 (Hash Map)
- 해시 맵은 해시 테이블으로 구현한
구체적인 데이터 구조 또는 클래스입니다.
예) 자바에서 해시 테이블을 기반으로 하는 Map 인터페이스 구현
즉 해시 테이블은 개념적인 자료구조로
위에서 계속해서 언급했던 키와 값의 쌍을 저장하고 관리하는 알고리즘이며
해시 맵은 해시 테이블을 기반으로 한
구체적인 프로그래밍 구현체입니다.
HashTable -> 개념
HashMap -> 해시 테이블을 구현한 구체적인 데이터 구조근데 사실 이게 끝이 아닙니다.
Java에서 HashMap과 HashTable의 차이점
가장 큰 차이점으로는 매번 언급되는게 있습니다.
HashTable -> Thread-safe O
HashMap -> Thread-safe XHashMap은 Thread-safe 하지 않기 때문에 멀티 스레드 환경에서
동시에 객체의 Data를 조작할 경우 문제가 발생할 수 있습니다
(관련해서 아래에 테스트가 있습니다)
하지만 HashTable은
- 모든 데이터 변경 메소드가 Syncronized로 선언되어 있습니다.
- 메소드 호출 전 쓰레드간에 동기화 락이 되어있습니다.
- 동기화 락을 통해 쓰레드 환경에서 데이터의 무결성을 보장해준다.
Synchronized란
- 자바에서 사용하는 키워드이며 다중 쓰레드 환경에서
데이터의 무결성과 쓰레드의 안전성을 보장해줍니다
데이터 무결성(Data Integrity)란
- 다중 쓰레드 환경에서는 여러 쓰레드가 동시에 공유 데이터에 접근할 수
있기에 데이터의 일관성과 정확성을 보장하기 위한 동기화가 필요합니다특징
그러면 다시 돌아와서, HashMap의 특징으로는 어떤 것이 있을까요?
- 빠른 데이터 검색 및 삽입
- 키-값 쌍 저장
- 해시 충돌 처리
- Null 허용
- 동기화 지원
- 등등...
빠른 데이터 검색 및 삽입: HashMap은 해시 테이블을 기반으로 하며, 이를 사용하여 데이터를 검색하고 삽입할 때 매우 빠른 성능을 제공합니다. 해시 테이블의 해시 함수를 사용하여 키와 값을 관리하기 때문에 대용량 데이터도 빠르게 처리할 수 있습니다.
키-값 쌍 저장: HashMap은 키(key)와 값(value)을 저장하는데 사용됩니다. 각 키는 고유해야 하며, 해당 키에 연결된 값을 가져올 수 있습니다. 이러한 특성으로 데이터를 효율적으로 관리할 수 있습니다.
해시 충돌 처리: 해시 충돌은 서로 다른 키가 동일한 해시값을 가질 때 발생하는데, HashMap은 이를 충돌 해결 기법을 통해 처리합니다. 주로 체이닝(Chaining) 기법을 사용하여 동일한 해시값을 가진 데이터를 연결 리스트로 저장합니다.
동기화 지원: HashMap은 기본적으로 스레드 안전하지 않습니다. 다중 스레드 환경에서 사용할 때는 ConcurrentHashMap과 같은 동기화된 버전을 사용해야 합니다.
Null 허용: HashMap은 null 값을 키 또는 값으로 허용합니다. 따라서 null 키나 null 값을 저장하고 조회할 수 있습니다.
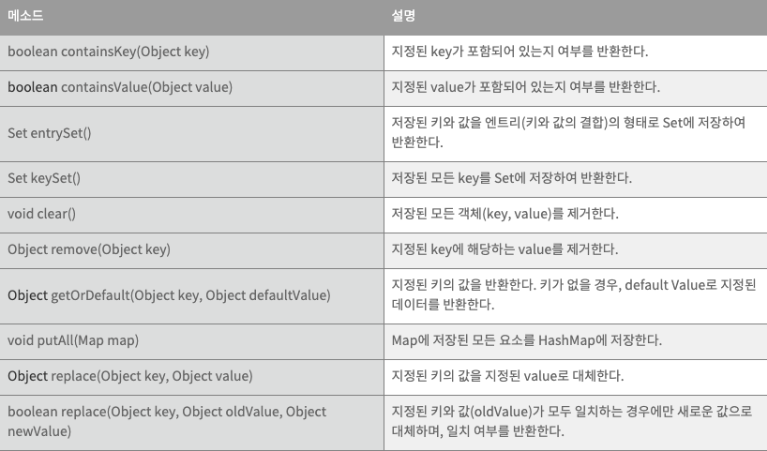
주요 메서드
HashMap종류
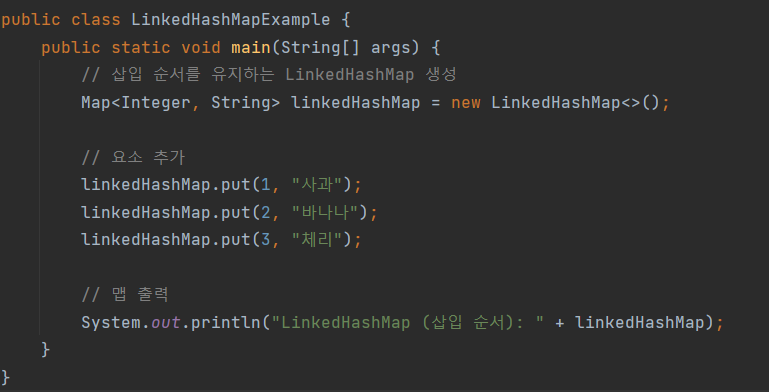
LinkedHashMap: 삽입 순서 또는 접근 순서를 유지하는 HashMap입니다.

TreeMap: 키가 정렬된 상태로 저장되는 Map 인터페이스를 구현한 자료구조입니다.

ConcurrentHashMap: 멀티스레드 환경에서 사용할 수 있는, 동시성을 지원하는 HashMap입니다.

멀티스레드 환경에서 HashMap 성능테스트
그럼 이제 HashMap에 대해서도 알아보고 여러가지 HashMap에 대해서도 알아봤는데...
이렇게 알아본 HashMap을 이용해서 실제로 개발 환경에서 어떤 부분에 적용하면 효과적인지
한번 탐구해보도록 합시다
멀티스레드 환경에서 HashMap 성능테스트 하기
실제로 개발을 하는 환경에서는 동시성과 성능 문제는 매우 중요한 사항인데요,
대부분의 애플리케이션에서는 멀티스레드를 사용하므로 이런 환경에서 데이터구조가 어떻게
동작하는지 이해하고 코드를 작성하는 것은 매우 중요합니다.
그러므로 오늘은 실제 멀티스레드 애플리케이션에서 데이터 구조의 성능과 안정성을
이해하기 위해 HashMap, ConcurrentHashMap, synchronizedMap 간의 성능 차이를 비교하며
적절한 자료구조를 선택할 수 있는 방법을 알아봅시다.
우선 실험을 하기에 앞서 동일한 조건에서 더 적절한 방법을 찾아야 하므로 조건을 먼저 정해주어야 합니다.
1. 다양한 스레드 수를 가진 환경에서 삽입, 삭제, 검색 작업을 수행한다
2. 각 자료구조의 성능을 비교함으로써 특정 상황에서 최적의 성능을 제공하는 방법을 찾는다
3. 결과를 바탕으로 각 자료 구조의 장단점과 적절한 예시를 정리한다public class HashTest {
// 테스트할 엔트리의 수
private static final int ENTRY_COUNT = 100000;
// 동시에 실행할 스레드의 수
private static final int THREAD_COUNT = 10;
public static void main(String[] args) throws InterruptedException {
Map<String, Integer> hashMap = new HashMap<>();
Map<String, Integer> synchronizedMap = Collections.synchronizedMap(new HashMap<>());
ConcurrentHashMap<String, Integer> concurrentHashMap = new ConcurrentHashMap<>();
long hashMapTime = testMap(hashMap);
long synchronizedMapTime = testMap(synchronizedMap);
long concurrentHashMapTime = testMap(concurrentHashMap);
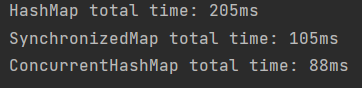
System.out.printf("HashMap total time: %dms\n", hashMapTime);
System.out.printf("SynchronizedMap total time: %dms\n", synchronizedMapTime);
System.out.printf("ConcurrentHashMap total time: %dms\n", concurrentHashMapTime);
}
private static long testMap(Map<String, Integer> map) throws InterruptedException {
ExecutorService executorService = Executors.newFixedThreadPool(THREAD_COUNT);
long startTime = System.currentTimeMillis();
for (int i = 0; i < THREAD_COUNT; i++) {
int threadNum = i;
executorService.execute(() -> {
for (int j = 0; j < ENTRY_COUNT / THREAD_COUNT; j++) {
// 삽입
map.put(String.format("%s-%s", threadNum, j), j);
// 검색
map.get(String.format("%s-%s", threadNum, j));
// 삭제
map.remove(String.format("%s-%s", threadNum, j));
}
});
}
executorService.shutdown();
executorService.awaitTermination(1, TimeUnit.HOURS);
long endTime = System.currentTimeMillis();
return endTime - startTime;
}
}
- 먼저 맵에 삽입할 엔트리의 수와 동시에 실행할 스레드의 수를 상수로 설정해줍니다.
- 각 자료구조를 생성하고 테스트 메소드를 만든 후 호출하여 자료구조의 성능을 테스트 합니다
2 - 1. 테스트 메소드 : 멀티스레드를 사용하여 삽입, 검색, 삭제 작업을 수행함
2 - 2. ExecutorService를 사용해 스레드 풀을 생성하고 각 스레드에서 맵 작업을 수행함 - 작업이 완료되면 ExecutorService를 종료시키고 전체 작업시간을 계싼하여 반환함.
위에서 말했던 각 HashMap의 종류 특성에 맞겠금 실제로 ConcurrentHashMap이 가장 성능상
이점들이 많았으며 이로써 멀티스레드 환경에서는 ConcurrentHashMap을 사용하는 것이 적절하다고
판단할 수 있었습니다, 하지만 동시성이 중요하지 않은 환경같은 단일 스레드 환경에서는
각각의 맵의 특성을 생각해 오히려 HashMap이 더 좋은 성능을 보일수도 있습니다.
얻은 점
오늘은 이렇게 HashMap의 개념, 특성, 종류, 적절한 자료구조 선택 방법등에 대해서 알아봤습니다..
솔직히 HashMap에 대해서 개념만 알고 여러 종류가 있고 그 종류에 따라서 자료구조를 어떻게 선택해야하는지, 부족한 점들이 많았었는데 조금이나마 더 고민을 해보고 선택할 수 있는 능력을 키운 거 같아 좋습니다. 감사합니다
