앞서 Ensemble(앙상블)에 대해 공부했습니다.
오늘은 앙상블 중에서도 부스팅 알고리즘에 대해 공부하려고 합니다.(그중에서도 XGBoost와 LightGBM)
Classification과 Regression의 작동 방식은 비슷하니 Classification에 대해 설명하겠습니다.
부스팅과 GBM에 관한 설명은 앞에서 설명했으니 참고 바랍니다.😀
[ML] Ensemble Learning (앙상블 학습)
📚 XGBoost(eXtreme Gradient Boosting)
XGBoost는 트리 기반의 앙상블 학습에서 가장 각광받고 있는 알고리즘 중 하나입니다.
XGBoost는 GBM에 기반하고 있지만, GBM의 단점인 느린 수행 시간 및 과적합 Regularization(규제) 부재 등의 문제를 해결했습니다. 특히, XGBoost는 병렬 CPU 환경에서 병렬 학습이 가능합니다.
XGBoost의 장점을 요약하면 다음과 같습니다.
- 뛰어난 예측 성능
- GBM 대비 빠른 수행 시간
- Overfitting Regularizaion(과적합 규제)
- Tree Pruning(나무 가지치기)
- 자체 내장된 교차 검증
- 결손 값 자체 처리
XGBoost는 GBM에 기반하고 있다고 했습니다.
이는 각 weak learner의 가중치를 Gradient Descent(경사 하강법)를 통해 업데이트 한다는 의미입니다.
기존 GBM은 성능은 좋았으나, 시간이 다른 앙상블 알고리즘에 비해 오래걸린다는 단점이 있었습니다.
XGBoost는 GBM의 시간 문제를 어느정도 해결하였습니다.
✅ Parameter
XGBoost에서는 sklearn wrapper 클래스 XGBClassifier를 제공합니다.
from xgboost import XGBClassifier
evals = [(X_train, y_train), (X_val, y_val)]
xgb_clf = XGBClassifier(n_estimators=100, learning_rate=0.2, early_stopping_rounds=50, eval_metrics='logloss')
xgb_clf.fit(X_train, y_train, eval_set=evals, verbose=1)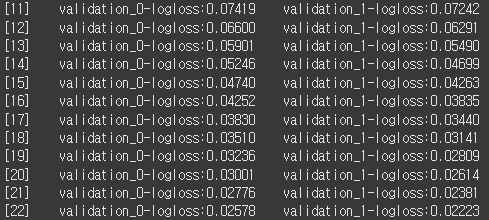
XGBoostClassifier의 주요 파라미터는 다음과 같습니다.
- n_estimators: weak learner 수
- max_depth: 각 결정 트리의 최대 깊이
- max_leaves: 최대 리프 노드 수
- learning_rate: 학습율
- booster: 사용할 부스터('gbtree', 'gblinear' or 'dart')
- n_jobs: 사용할 CPU 스레드(-1이면 모두 쓰겠다는 의미)
- subsample: 데이터 샘플링시 사용할 비율
- colsample_bytree: 학습 시 데이터에서 사용할 컬럼 비율
- reg_alpha: L1 규제 가중치
- reg_lambda: L2 규제 가중치
- random_state: random_state
- eval_metric: 평가 지표
- early_stopping_rounds: 조기 종료 callback function
- callbacks: 콜백 함수(콜백 함수를 list형으로 받음)
- eval_set: XGBClassifier를 fit할 때, [(X_train, y_train), (X_val, y_val)]형식으로 입력하면 자체 교차검증을 validation data로 수행
대부분은 GBM에도 있는 parameter임을 알 수 있습니다.
서 달라진 점은 L1, L2규제가 생겼으며, eval_metric와 eval_set같은 자체 검증을 위한 parameter가 생겼다는 점입니다.
이를 통해, early_stopping과 같은 콜백 함수를 이용할 수 있습니다.
이외에도 다양한 parameter가 있으니 자세한 내용은 reference부분의 공식 문서를 참고해주세요.
✅ plot_importance
xgboost는 plot_importance() API를 통해 feature importance를 시각화 해줍니다.
from xgboost import plot_importance
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize=(10, 12))
plot_importance(xgb_clf, ax=ax)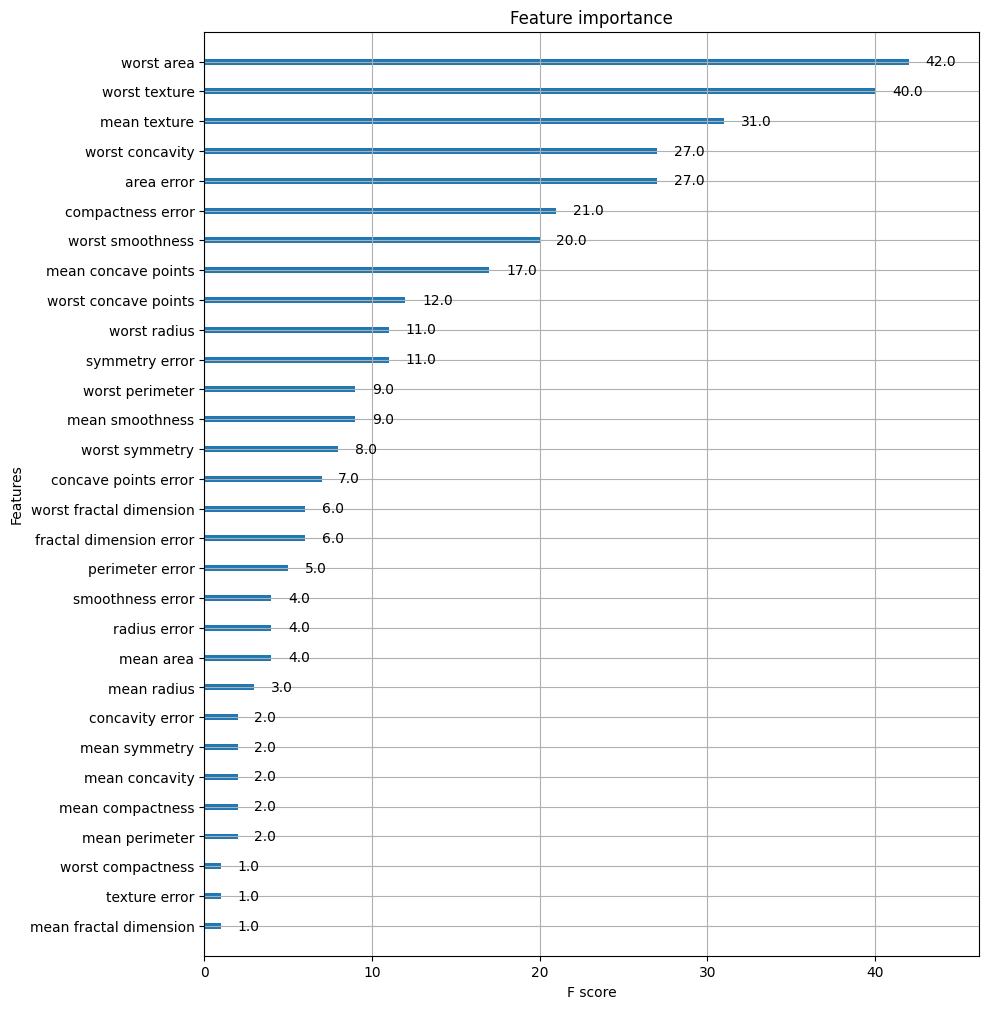
결정 트리에서도 그렇듯이 feature importance를 너무 신뢰해서는 안됩니다.
feature importance는 노드 분할에 따른 가중치 이기 때문입니다.
📚 LightGBM
LightGBM은 XGBoost가 나온 2년 뒤에 나온 부스팅 계열 알고리즘입니다.
XGBoost와 마찬가지로 부스팅 계열 알고리즘에서 각광 받고 있습니다.
LightGBM의 가장 큰 장점은 XGBoost보다 학습에 걸리는 시간이 훨씬 적으며, 메모리 사용량도 적다는 점입니다. 또한, XGBoost와 비교해도 성능은 별다른 차이가 없습니다.
(개인적으로 대용량 데이터에서는 LightGBM의 성능이 더 좋다고 생각합니다.)
LightGBM의 단점이라면, 적은 데이터 세트에 적용할 경우 과적합이 발생하기 쉽다는 것입니다.
공식 문서에서는 10,000건 이하의 데이터 세트 이상은 되어야 한다고 기술합니다.
따라서 LightGBM의 XGBoost 대비 장/단점은 다음과 같습니다.
- 더 빠른 학습과 예측
- 더 적은 메모리 사용량
- Category형 피처의 자동 변환
- 적은 데이터셋에서는 과적합 발생 높음
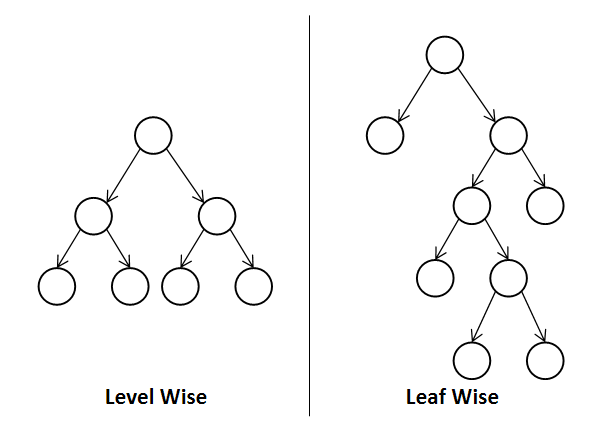
✅ Level Wise / Leaf Wise
LightGBM은 일반 GBM 계열의 트리 분할 방법과 다르게 Leaf Wise(리프 중심 트리 분할)방식을 사용합니다.
기존 대부분 트리 기반 알고리즘들은 트리의 깊이를 줄이기 위해 Level Wise(균형 트리 분할)방식을 사용합니다.
일반적으로 균형 트리 분할 방식이 과적합을 방지하는데 유리하다고 생각했지만, LightGBM은 리프 중심 분할 방식이 아직 발견되지 않은 규칙을 발견해 학습한 트리들의 종합으로 오류는 줄어들 것이라고 판단했습니다.
균형 트리 분할은 최대한 균형 잡힌 트리를 구성하고, 리프 중심 분할은 이에 종속되지 않습니다.
✅ Parameter
lightgbm에서는 sklearn wrapper LGBMClassifier를 제공합니다.
from lightgbm import LGBMClassifier
import lightgbm as lgb
lgb_clf = LGBMClassifier(n_estimators=1000, learning_rate=0.1, eval_metric='logloss', max_depth=4, verbose=-1)
lgb_clf.fit(X_train, y_train, eval_set=evals, callbacks=[lgb.early_stopping(1), lgb.log_evaluation(period=1)])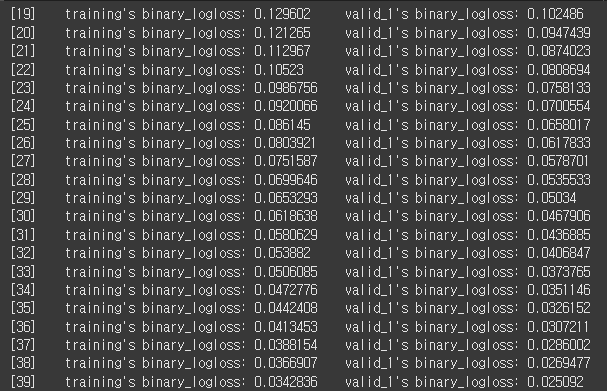
LGBMClassifier의 주요 파라미터는 다음과 같습니다.
- boosting_type: 부스팅 종류
- num_leaves: 최대 리프 노드 수
- max_depth: 트리 최대 깊이
- learning_rate: 학습율
- n_estimators: weak learner 수
- objective: 목적함수('binary', 'multiclass')
- min_child_weight: 리프 노드의 최소 가중치 합
- min_child_samples: 리프 노드의 최소 샘플 수
- subsample: 데이터 샘플링시 사용할 비율
- colsample_bytree: 학습 시 데이터에서 사용할 컬럼 비율
- reg_alpha: L1 규제 가중치
- reg_lambda: L2 규제 가중치
- random_state: random_state
- n_jobs: 사용할 CPU 스레드(-1이면 모두 쓰겠다는 의미)
- eval_set: LGBMClassifier를 fit할 때, [(X_train, y_train), (X_val, y_val)]형식으로 입력하면 자체 교차검증을 validation data로 수행
- eval_metric: LGBMClassifier를 fit할 때, 사용할 평가 지표
- callbacks: LGBMClassifier를 fit할 때, 콜백 함수(콜백 함수를 list형으로 받음)
- boost_from_average: Objective Parameter로 불균형한 데이터일 때 False를 해주는 것이 좋음(default=True)
LGBMClassifier는 max_depth보다 num_leaves를 중심으로 파라미터를 튜닝하는 것이 일반적으로 더 좋습니다.
앞서 설명 드렸듯이, Leaf Wise 방식으로 트리를 분할하기 때문입니다.
파라미터중 XGBoost와 차이라고 한다면 estimator 자체 하이퍼 파라미터에 들어가는 지, fit 메서드에 들어가는 지 정도의 차이일 것입니다.
또한, LGBMClassifier에는 early_stopping_rounds가 따로 존재하지 않으며 callback에 따로 입력 해주어야 합니다.
저의 지식 부족일지도 모르겠지만, LGBMClassifier는 XGBClassifier와는 다르게 로그를 보여주지 않더군요.
이때, callbacks 파라미터에 lgb.log_evaluation(period=1)를 사용해주면 지정된 period마다 로그를 보여주게 됩니다.😁
✅ plot_importance
LightGBM도 XGBoost와 마찬가지로 plot_importace API를 제공합니다.
from lightgbm import plot_importance
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize=(10, 12))
plot_importance(lgb_clf, ax=ax)
📜 Reference
