안녕하세요. 오늘은 AlexNet 논문을 정리하며 공부해보려고 합니다.
AlexNet은 딥러닝을 세상에 알린 모델로써 2012년 ImageNet에서 기존 전통적인 머신러닝보다 성능을 대폭 향상 시켰습니다.
AlexNet Paper
본 장에서는 논문 리뷰를 하지만, 논문 내용을 그대로 직역했다기 보다는 저의 개인적인 견해와 저의 지식을 통합하였습니다. 또한, 제목과 순서도 논문과는 다를 수 있습니다.
참고로 논문에는 입력 데이터가 224 X 224 X 3으로 나와있지만,
논문의 아키텍처처럼 나오려면 227 X 227 X 3이어야 합니다. 구현은 227로 했으며, 설명은 224를 기준으로 한 점 참고 바랍니다.
Abstract
AlexNet은 ImageNet LSVRC대회의 데이터를 통해 학습하고, 성능을 평가하였습니다.
2010년 데이터에서는 top-5 error가 17.0%정도로 기존 모델에 비해 높은 성능을 보여주었습니다.
AlexNet은 6천만개의 파라미터, 650,000개의 뉴런으로 구성된 복잡한 모델입니다.
최종적으로 2012년 대회에서는 top-5 error가 15.3%를 기록하며, 딥러닝을 세계에 알리게 되었습니다.
1. Introduction
기존의 MNIST,CIFAR과 같은 데이터는 현대에 요구되는 모델의 성능을 측정하기에 너무 작은 데이터셋 입니다. 실제 상황의 다양성을 따라가지 못합니다. 그렇게 양질의 데이터셋과 모델이 필요했으며, 그로인해 논문에서는 ImageNet 데이터셋을 이용하였고, AlexNet을 만들게 되었습니다.
AlexNet은 다양한 폭과 깊이로 조절될 수 있으며, 그로인해 성능이 바뀔 수 있다고 암시합니다.
예를 들어, 논문에서 발표한 AlexNet 모델은 5개의 convolution-layer와 3개의 fully-connected-layer로 구성되어 있습니다. 그 당시에는 지금보다 하드웨어가 발달되어 있지 않았기에 논문에서도 미래의 가능성을 시사하고 있습니다.
또한, 기존의 feed-forward neural network와 비교해 봤을 때, CNN이 더 적은 파라미터로 학습하기 쉽다고 합니다. 이렇게 좋은 CNN의 특성에도 불구하고, 비싼 컴퓨팅 비용 때문에 쉽게 적용하지 못했습니다.
논문에서도 깊이와 폭을 넓히고 싶어하는 것이 보였으나, 아마 당시의 하드웨어 문제로 더 실험하지 못한 것 같습니다. (논문에서 GTX 580 3GB GPUs를 사용.)
2. The Dataset

ImageNet의 데이터를 사용했지만, 전체 데이터셋을 사용한 건 아닙니다.
원본 ImageNet은 22,000개의 카테고리를 가진 1500만개의 데이터셋입니다.
ILSVRC는 이중 1000개의 카테고리를 가진 120만개의 데이터셋(학습용)을 sub-sampling한 것입니다.(검증용은 50,000개)
또한, ImageNet의 데이터의 크기가 다양해서 논문에서는 256 X 256으로 다운샘플링 했습니다.
정확히는 고정샘플링 했다는 표현이 맞을 것 같습니다.
(나중에 Data Augmentation을 할 때 최종적으로 224 X 224로 추출합니다.)
3. The Architecture
AlexNet은 아래와 같은 아키텍처를 가지고 있습니다.
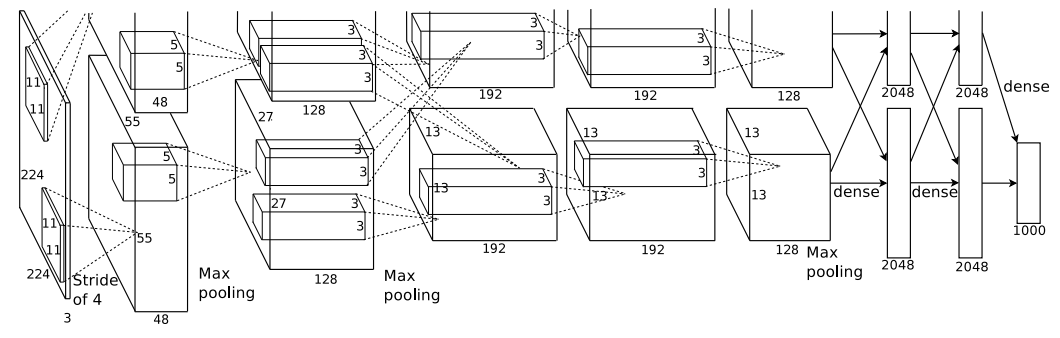
5개의 convolution layer와 3개의 fully-connected-layer로 구성되어 있습니다.
✔ ReLU Nonlinearity
AlexNet은 뉴런의 활성화 함수로 ReLU를 사용했습니다.
기존에는 tanh를 활성화 함수로 이용했었으나, 실험한 결과 ReLU가 tanh보다 최적화하는 시간이 더 빨랐다고 합니다. 그리고 최적화하는 시간이 빠른 쪽이 큰 모델을 학습하기에 좋은 영향을 미친다고 합니다.
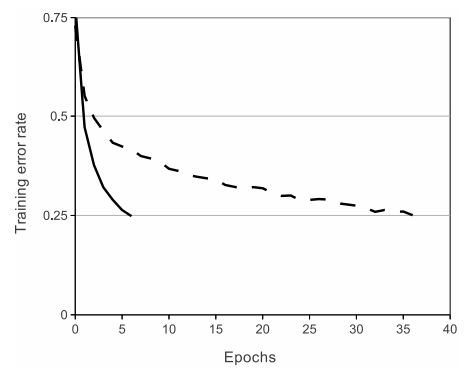
아래 그림에서 실선은 ReLU의 최적화를 나타낸 것이고, 점선은 tanh의 최적화를 나타낸 것입니다.
둘 다 같은 환경에서 작동했으며, 모델은 활성화 함수만 다릅니다.
ReLU의 경우 epoch가 6정도에서 Training error가 0.25에 도달했지만, tanh의 경우 epoch가 35회를 넘어서야 도달한 것을 볼 수 있습니다.
✔ Local Response Normalization
ReLU는 정규화를 사용하지 않아도 된다고 하지만, 논문에서는 일반화를 위해 Local Normalization을 모델에 구성했습니다.
이때, Local Response Normalization은 BatchNormalization과 비슷한 역할을 합니다.
이때, 이미지 전체에 대해 정규화를 적용하는 것이 아닌 local 단위로 정규화를 진행합니다.
식은 아래와 같습니다.
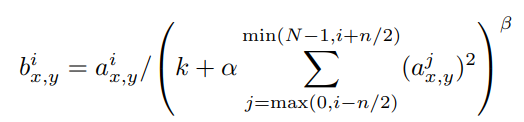
- n: 동일한 spatial에서 kernel 개수
- N: layer의 전체 kernel 개수
- x, y: spatial 정보
- i: 특정 spatial(x, y)에서의 kernel
- k, n, alpha, beta: hyper-parameter
AlexNet은 k=2, n=5, alpha=10e4, beta=0.75로 사용했습니다.
Local Response Normalization을 적용한 결과 성능이 좋아졌다고 합니다.
top-5 error는 1.2% 감소했다고 합니다.
✔ Overlapping Pooling
기존의 타 모델들은 Pooling시 Overlap되지 않도록 하였지만, AlexNet은 Pooling을 적용할 때, Overlap되도록 적용합니다.
여기서 Overlap이란, Pooling을 적용하기 위한 kernel이 겹치는 현상을 말합니다.
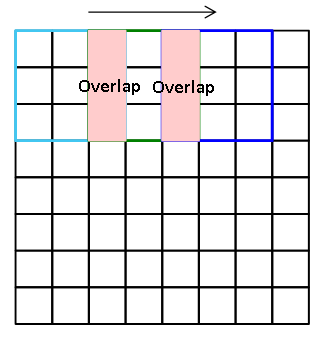
AlexNet은 커널 사이즈가 z X z라고 하고, stride가 s라고 할 때, s=2, z=3으로 설정되어 있습니다.
즉, s < z인 상태를 유지했습니다.
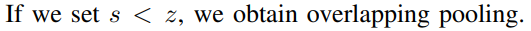
Overlapping Pooling을 적용한 결과 s=z=2인 기존의 Pooling 방식보다 top-5 error가 0.3% 낮아졌다고 합니다.
✔ Overall Architecture
AlexNet의 특징을 요약해보자면,
- 활성화 함수로 ReLU를 사용.
- Local Response Normalization 사용.(BatchNormalization과 유사)
- 기존 Pooling방식과는 달리 Overlapping Pooling을 사용.
AlexNet은 5개의 convolution layer와 3개의 fully-connected-layer를 가집니다.
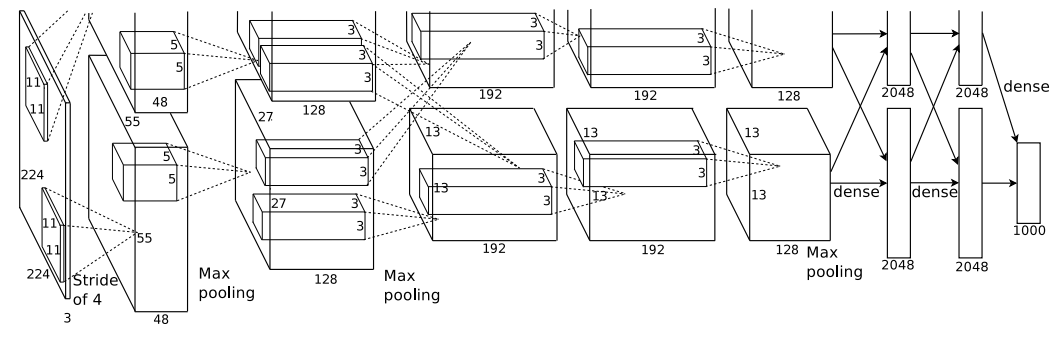
이중에서도 특징이라고 할 것은, 처음 kernel_size가 11X11로 매우 크다는 점. 마지막 convolution layer에서 kernel수가 384에서 256개로 줄었다는 점입니다.
4. Reducing Overfitting
1000개의 클래스에 대해 많은 데이터가 있지만,
AlexNet은 6천만개의 파라미터로 구성되어 있기 때문에 오버피팅이 일어나기 쉽습니다.
다시말해, 학습에 충분하지 않은 데이터로 오버피팅이 일어나기 쉽습니다.
논문에서는 이를 해결하기 위해 두 가지 해결책을 제시합니다.
✔ Data Augmentation
한정된 데이터에서 오버피팅을 줄이기 위해서 가장 쉬운 방법은 데이터 증강을 이용하는 것입니다.
AlexNet은 크게 두 가지 데이터 증강 기법을 사용했습니다.
1. translation / horizontal reflection
앞에서 데이터를 256 X 256으로 다운샘플링 했습니다. 이제 이 데이터를 랜덤하게 224 X 224로 패칭합니다.(translation)
그리고 좌우 반전을 적용합니다.(horizontal reflection)
2. Intensities of the RGB
다음으로 RGB 채널의 강도를 조절합니다.
이는 이미지 대비와 밝기 조절과 비슷한 증강 기법인 것 같습니다.
논문에서는 이를 위해 각 RGB 세트에 PCA 기법을 적용합니다.
이렇게 구해진 vector p, value lambda를 이용해 강도를 조절합니다.
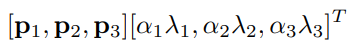
이렇게 구해진 행렬을 기존 RGB 채널에 더해줍니다. alpha는 랜덤한 값으로 각 이미지가 다시 학습될 때마다 정해지는 값 입니다.
이때, 한번에 모든 픽셀에 적용하는 것이 아닌 spatial x,y에 대해 적용합니다.
논문에서는 3 X 3이라고 명시되어 있습니다.
이러한 데이터 증강 기법을 통해 top-1 error를 1%줄였다고 합니다.
✔ Dropout
흔히, 앙상블이라고 불리는 기법은 모델의 성능을 올리기 좋은 방법입니다.
하지만, 이는 컴퓨팅 연산이 많이 들어갑니다. 특히나 AlexNet같은 larger model의 경우에는 더욱 자원이 많이 듭니다.
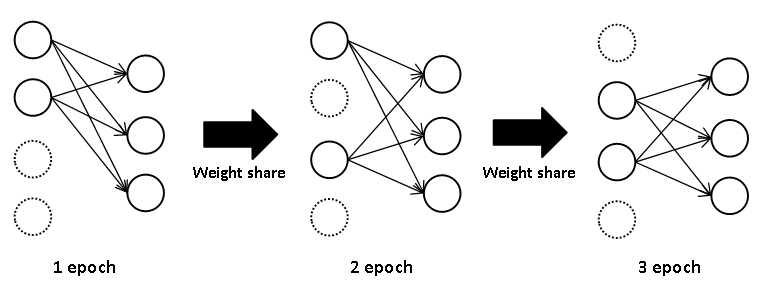
논문에서는 Dropout기법을 이용해 상대적으로 적은 컴퓨팅 연산을 이용해 앙상블과 같은 효과를 낼 수 있다고 말합니다.(단, 매 epoch마다 가중치는 공유됩니다.)

AlexNet은 fully-connected-layer의 첫 번째, 두 번째 layer에 적용합니다.(비율은 0.5)
이는 매 학습 시마다 다르게 적용되므로 다른 모델이 학습하는 것과 같은 효과를 낼 수 있습니다.
tensorflow 구현
마지막으로 텐서플로우를 통해 AlexNet을 구현하며 마치도록 하겠습니다.
from tensorflow.keras.layers import Input, Conv2D, Activation, BatchNormalization, MaxPooling2D
from tensorflow.keras.layers import Flatten, Dense, Dropout
from tensorflow.keras.models import Model
input_tensor = Input(shape=(227, 227, 3))
### convolutional layer
x = Conv2D(filters=96, kernel_size=(11, 11), strides=4)(input_tensor)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv2D(filters=256, kernel_size=(5, 5), padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = MaxPooling2D(pool_size=(3, 3), strides=2)(x)
x = Conv2D(filters=384, kernel_size=(3, 3), padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = MaxPooling2D(pool_size=(3, 3), strides=2)(x)
x = Conv2D(filters=384, kernel_size=(3, 3), padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv2D(filters=256, kernel_size=(3, 3), padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = MaxPooling2D(pool_size=(3, 3), strides=2)(x)
### fully-connected-layer
x = Flatten()(x)
x = Dense(4096, activation='relu')(x)
x = Dropout(0.5)(x)
x = Dense(4096, activation='relu')(x)
x = Dropout(0.5)(x)
output = Dense(1000, activation='softmax')(x)
model = Model(inputs=input_tensor, outputs=output)
model.summary()
Reference
