오늘은 VGG 논문을 리뷰하려고 합니다.
2014년 ImageNet Classification 대회에서 2등을 한 모델입니다. 상대적으로 간단한 아키텍처를 가지고, 높은 성능을 보여주었습니다.
VGG Paper
본 장에서는 논문 리뷰를 하지만, 논문 내용을 그대로 직역했다기 보다는 저의 개인적인 견해와 저의 지식을 통합하였습니다. 또한, 제목과 순서도 논문과는 다를 수 있습니다.
Abstract
VGG는 2014 ImageNet Challenge에서 2등의 성과를 거둔 모델입니다.
논문에서는 모델의 성능 향상을 convolutional network의 깊이와 연관지어 생각했습니다. (특히, 큰 이미지에서 더욱 연관있다고 생각했습니다.)
따라서 네트워크를 VGG16, VGG19와 같이 깊이가 16, 19나 되는 모델을 만들었습니다.
기존 AlexNet에서 11 X 11처럼 큰 kernel을 사용했지만, VGG는 오로지 3 X 3 kernel을 사용하여 computing 비용을 감소시킬 수 있었습니다.
참고로 2012년 AlexNet의 경우 컴퓨팅 비용과 하드웨어 문제로 깊이를 더 늘리지 못했습니다.
1. Introduction
Convolutional networks는 큰 이미지에서 좋은 성과를 냈습니다.
ConvNets이 컴퓨터 비전에서 더 자리잡으면서, 기존 아키텍처를 향상시키기 위한 시도가 있었습니다.
대표적인 시도로 첫 번째 layer에 더 작은 kernel 사이즈와(논문에서는 window size라고 언급) 더 작은 stride를 적용하려고 했었습니다.
논문에서는 또다른 중요한 측면인 깊이에 대해 다뤘습니다.
모든 layer에 매우 작은 3 X 3 kernel을 사용하며 Convolution layer의 증가를 이뤄냈습니다.
3 X 3 kernel을 사용하면 큰 kernel에 비해 적은 파라미터가 필요하게 됩니다.
결론적으로, VGG는 ImageNet에서 좋은 성능을 보여주었을 뿐만 아니라 다른 이미지에 대해서도 좋은 성능을 보여주었습니다.
VGG는 상대적으로 간단한 파이프라인으로 구성되어 있음에도 불구하고 좋은 성능을 내어 화제가 되었습니다.
2. ConvNet Configurations
✔ Architecture
논문에서 아키텍처 구조는 크게 3가지로 설명합니다.
Image Preprocessing
이미지 전처리는 224 X 224 형식으로 RGB 이미지를 고정시켰으며, RGB 평균 값을 빼는 방식으로 진행했습니다. (학습 데이터에서 계산된 RGB 각각의 평균을 구합니다.)
Convs layer
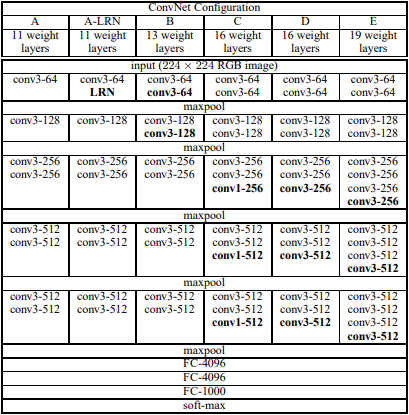
Convolution 진행 시 kernel은 3 X 3으로 고정 시켰으며, 간혹 1 X 1도 사용했다고 언급합니다. 1 X 1은 논문에서 자세히 언급하지 않지만, VGG16에 적용한 것으로 보입니다.
아래 그림에서 C 모델입니다.
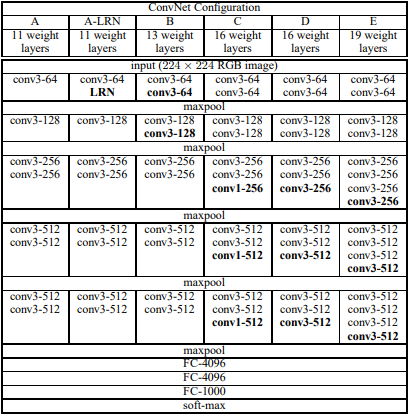
모든 convolution 연산시 stride는 1로 고정시켰습니다. 또한, 3 X 3 conv에서 1 padding을 적용 했습니다.
이렇게 3 X 3 conv를 적용함으로써 파라미터 수를 줄일 수 있다는 것을 증명했습니다.
예를들어, 다음과 같이 5 X 5 데이터에 대해 3 X 3과 5 X 5 kernel Conv를 적용한 결과를 보면 3 X 3 두 개를 적용한 것과 5 X 5 하나를 적용한 것의 결과는 같지만, 파라미터는 3 X 3이 더 적은 것을 알 수 있습니다.
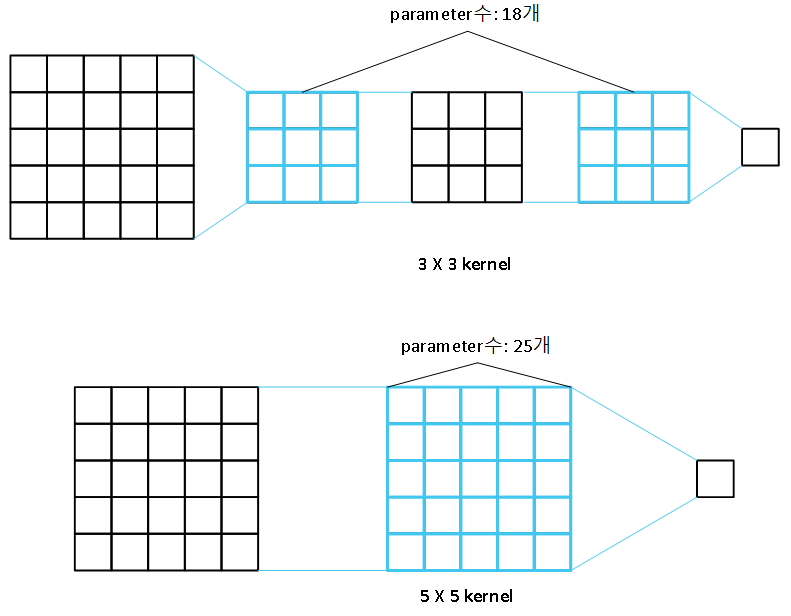
논문에 제시된 내용을 언급해 보자면,
3 X 3 conv와 7 X 7 conv가 존재한다고 가정합시다.
이때, 채널 C에 대해 각 parameter수를 공식으로 표현하면 3 X 3 conv는 3(9C^2), 7 X 7 conv는 49C^2입니다. 7 X 7을 적용할 때, 3 X 3에 비해 81%정도 parameter가 증가합니다.
3 X 3 conv에서 3을 더 곱하는 이유는 7 X 7 conv의 효과를 내기 위해 적용하는 layer 수 때문입니다.
MaxPooling
MaxPooling을 적용할 때, kernel=2 X 2이며, stride=2로 진행했습니다.
즉, Overlapping이 발생하지 않습니다.
아래는 VGG16 아키텍처를 잘 표현한 그림을 가져와봤습니다.(reference 참조)
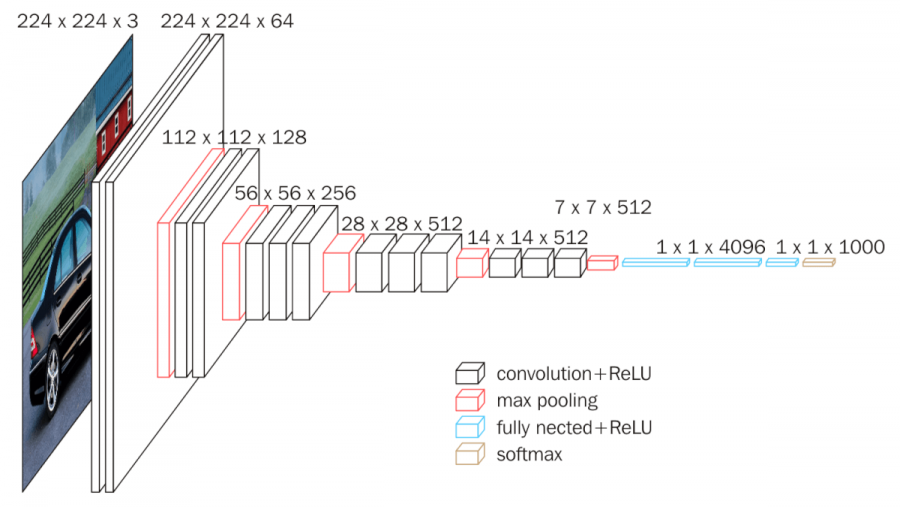
이러한 VGG 아키텍처는 모델의 깊이를 대폭 늘림에도 불구하고 파라미터 수를 통제하는 데 기여했습니다.
3. Conclusion
결론적으로, 논문에서는 모델의 깊이가 classification 성능에 효율적인 영향을 미친다는 것을 증명했습니다. 또한, 이렇게 만들어진 VGG는 넓은 범위의 데이터셋에 대해 일반화된 성능을 보였습니다.
VGG는 2014년에 진행된 ImageNet Classification 대회에서 top-5 error 6.8%를 보이며, 근소한 차이로 2등을 했습니다.(1등 GoogLeNet은 6.7%)
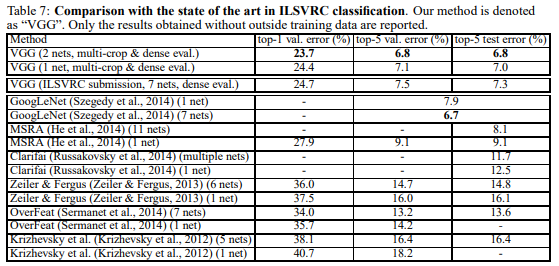
비록 1등은 아니었지만, 매우 간결한 모델로 이렇게 성능을 높일 수 있다는 것을 보여준 모델이었습니다.
tensorflow 구현
from tensorflow.keras.layers import Input, Conv2D, Activation, BatchNormalization, MaxPooling2D
from tensorflow.keras.layers import GlobalAveragePooling2D, Flatten, Dense, Dropout
from tensorflow.keras.models import Model
def conv_block(x, filters, kernel_size, padding, iter=2, IsPooling=False):
for _ in range(iter):
x = Conv2D(filters=filters, kernel_size=kernel_size, padding=padding)(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
if IsPooling:
x = MaxPooling2D(2)(x)
return x
input_tensor = Input(shape=(224, 224, 3))
# 1block
x = conv_block(input_tensor, filters=64, kernel_size=(3, 3), padding='same', iter=2, IsPooling=True)
# 2block
x = conv_block(x, filters=128, kernel_size=(3, 3), padding='same', iter=2, IsPooling=True)
# 3block
x = conv_block(x, filters=256, kernel_size=(3, 3), padding='same', iter=3, IsPooling=True)
# 4block
x = conv_block(x, filters=512, kernel_size=(3, 3), padding='same', iter=3, IsPooling=True)
# 5block
x = conv_block(x, filters=512, kernel_size=(3, 3), padding='same', iter=3, IsPooling=True)
x = Flatten()(x)
x = Dense(4096, activation='relu')(x)
x = Dropout(0.5)(x)
x = Dense(4096, activation='relu')(x)
x = Dropout(0.5)(x)
x = Dense(1000, activation='relu')(x)
vgg_model = Model(inputs=input_tensor, outputs=x)Reference
