안녕하세요. 오늘은 R-CNN 논문 리뷰를 해보려고 합니다.
R-CNN은 PASCAL VOC에서 주최한 Object Detection 대회에서 딥러닝(CNN)을 적용해 좋은 성능을 보여준 모델입니다.
RCNN Paper
본 장에서는 논문 리뷰를 하지만, 논문 내용을 그대로 직역했다기 보다는 저의 개인적인 견해와 저의 지식을 통합하였습니다. 또한, 제목과 순서도 논문과는 다를 수 있습니다.
Abstract

지난 몇 년간 Object Detection은 정체기였습니다.
이런 상황 속 논문에서는 PASCAL VOC에서 mAP성능을 기존보다 30% 끌어올린 간단하고, 확장 가능한 알고리즘을 소개합니다. 저자들은 아래의 두가지 포인트에 집중했습니다.
-
대용량 Convolutional Layer 적용.
-
데이터가 희소할 때, 비슷한 업무에서 지도학습된 모델이 원하는 도메인에서 파인 튜닝이 적용된다면 성능 향상을 나타냄.
Region Proposal과 CNN을 이용했기 때문에 R-CNN이라고 이름이 지어졌습니다.
이렇게 만들어진 R-CNN은 이전 OverFeat 모델보다 좋은 성능을 보여줬습니다.
1. Introduction

기존 SIFT와 HOG기반의 Object Detection 방식에는 한계가 있었고, 2010-2012년 사이 발전은 더뎠습니다.
또한, 저 당시 인간의 인지능력이 DownStream 단계를 거치면서 이루어 진다는 것을 알았습니다.
이는 feature 연산 과정에서 인지 단계에 계층적이고, 멀티 스테이지 과정이 있음을 보여줍니다.
이전에도 이를 구현하려고 시도한 적이 있었지만, 알고리즘이 부족했습니다.
하지만, SGD를 통한 GD의 구현이 가능해지면서 다시 시도가 가능해졌습니다.

1990년에도 존재했던 CNN이 2012 ImageNet 대회로 인해 다시 화두가 되었습니다.
이는 "Classification에서 좋은 성능을 내보인 CNN이 이제 Object Detection으로 어떻게 확장될 것인가?"에 대해 연구가 이뤄지는 계기가 되었습니다.
논문에서는 이 질문에 대해 Classification과 Object Detection 사이의 차이를 연결하며 CNN이 Object Detection분야에서 좋은 성능을 이끈다는 것을 보여주려고 합니다.
목표를 달성하기 위해서 두 가지 문제에 초점을 맞췄습니다.
1. 어떻게 딥러닝을 이용해 Object를 Localization할 것인가?
2. 어떻게 적은 양의 데이터로 높은 성능을 이끌어낼 것인가?

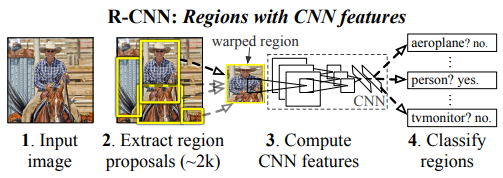
1. 이미지 분류와는 다르게, Detection은 Localizing을 요구합니다.
Localization 자체를 회귀 문제로 접근하려는 시도가 있었지만, 좋은 성능을 내진 못했습니다.
또다른 대안으로 슬라이딩 윈도우 방식도 있었지만, 기술적인 문제에 부딪히게 됩니다.
논문에서는 Localization 문제를 "recognition using region"을 통해 해결하려고 했습니다.
이 방법은 이미지에서 2000개의 카테고리를 뽑아내는 방식으로, 이렇게 뽑아낸 이미지를 고정된 피처 벡터로 추출합니다. 그리고 SVM 알고리즘을 활용해 분류합니다.
뽑아낸 region shape에 관계없이 적용될 수 있다는 장점이 있습니다.

2. 이미지 데이터가 모델이 학습하기에 충분하지 않다는 점입니다.
이에 논문에서는 다른 데이터로 pre-trained된 모델에 다시 fine-tuning을 적용하는 방식을 제시합니다.
이는 데이터가 희소할 때, 모델 성능을 향상시킵니다.
실제로 논문의 실험에서 fine-tuning을 적용한 모델이 기존에 비해 mAP를 8% 올렸다고 합니다.
이렇게 문제를 해결함으로써 간단한 bounding-box regression 방법이 Localization 오류를 줄인다는 것을 입증했습니다.
2. R-CNN Architecture
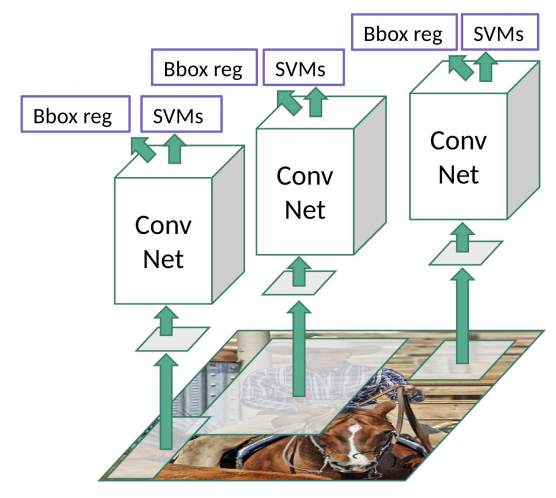
R-CNN은 다음과 같이 크게 3가지 방식으로 구성됩니다.
-
Region Proposal
-
Convolutional Layer
-
SVM
✔ Module design
Region proposals

최근 Region Proposal과 관련해서 objectness, selective search, category-independence object proposals 등 다양한 논문이 나오고 있습니다. R-CNN은 Selective Search방식을 이용합니다.
Selective Search와 관련해서는 이전에 공부한 내용이 있으니 참고하시면 좋을 것 같습니다.
[CV] Sliding Window / Selective Search(슬라이딩 윈도우 / 영역 추정)
Feature extraction

Region Proposal이후 CNN 아키텍처를 통해 Feature extraction을 진행합니다.
R-CNN은 최종적으로 4096차원의 feature map을 추출합니다.
들어온 이미지는 전처리되어 227 X 227 RGB가 되고, 이는 Convolutional layer를 통해 feature extraction됩니다.

이때, CNN에 적용하기 위해 앞서 Region Proposal된 이미지를 비율에 상관없이 모델의 입력 크기로 warp해줍니다. 이렇게 resize된 이미지를 CNN 아키텍처에 넣을 때, region proposal된 Bounding Box를 딱 맞게 넣는 것이 아니라 p 픽셀만큼의 공간을 여유로 두고 넣습니다.
(논문에서는 p=16으로 지정했습니다.)
SVM
R-CNN의 특징은 CNN을 통해 나온 feature map에 대해서 각 클래스에 대해 SVM을 적용한다는 것입니다.
이때, CNN과 SVM에서 적용되는 sample은 positive sample과 negative sample에 대해 차이가 있습니다.
(✔ Training 부분을 참고해주세요.)
✔ Test-time detection

R-CNN이 작동하는 원리는 다음과 같습니다.
Selective Search를 이용해 2000개의 region proposal을 수행하고, 이를 CNN 아키텍처에 warp하여 넣습니다. 이후 SVM 모델을 이용해 각 feature map에 점수를 매깁니다.
이렇게 주어진 score를 통해 NMS를 수행하여, 필요없는 Bounding Box를 제거하는 방식으로 진행됩니다.
논문에서는 R-CNN의 두 가지 특징이 모델 성능에 향상에 영향을 미친다고 말합니다.
1. R-CNN은 모든 CNN 파라미터가 모든 카테고리와 섞여 공유됩니다.
2. R-CNN의 feature vector는 기존보다는 상대적으로 저차원 형태이기 때문에 연산 시간도 효율적입니다.
그리고 이렇게 나온 feature vector는 최종적으로 SVM에 들어갈 때, 2000 X 4096 행렬로 들어갑니다. 이는 4096 차원 feature map과 2000개 예측 클래스의 결합입니다. 이에 따라 SVM의 weight 수는 2000 X 4096이 됩니다.
✔ Training

Pre-Training
pre-trained 모델을 사용할 때, 2012 ImageNet 데이터를 사용했습니다.
Fine-Tuning
ImageNet에서 사용한 CNN 모델 아키텍처는 그대로 사용하고, classification layer만 (N+1)로 변경되었습니다. 여기서 N은 Class 개수로, PASCAL VOC의 경우 20입니다.
추정된 region proposal은 IOU threshold가 0.5로 산정되었습니다.
즉, IOU가 0.5보다 작은 경우 Negative로 sample이 됩니다.
각 SGD에서 mini-batch는 positive sample 32, negative sample 96이 되도록 맞췄습니다.(1개 미니배치 = 128) 일반적으로 negative sample이 훨씬 많기 때문에 positive sample에 더 초점을 두었습니다.
Classifier
R-CNN은 최종적으로 SVM을 적용한다고 했습니다.
SVM을 학습시킬 때, 앞에 파인튜닝에서 적용한 IOU threshold와 다른 기준치로 positive sample과 negative sample을 나눕니다. threshold=0.3.
논문에서 threshold를 각각 다르게 설정한 이유는 둘 다 같게 설정을 했을 때보다 성능이 더 좋았기 때문이라고 합니다.
3. Bounding Box Regression
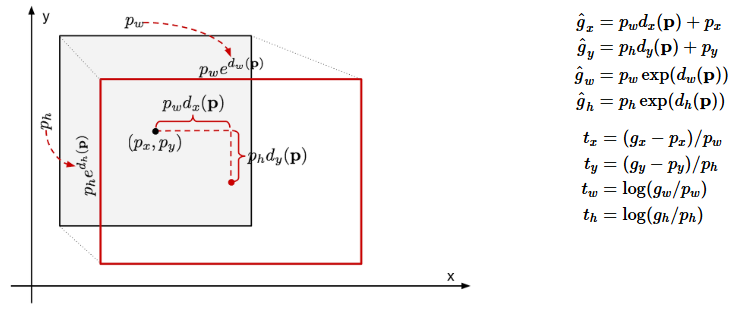
일반적으로 Selective Search를 이용해 추정한 것은 부정확합니다. 이를 위해 R-CNN에서는 Selective Search된 Box의 위치를 조정해줍니다.
Selective Search된 Box는 Px, Py, Pw, Ph로 나타낼 수 있습니다.
(Px, Py는 center 좌표, Pw, Ph는 width, height)
마찬가지로 Ground Truth도 Gx, Gy, Gw, Gh로 나타낼 수 있습니다. 모델은 Pi가 Gi로 최대한 근접하게 하는 것을 목표로 합니다. Pi가 인풋으로 들어왔을 때, 모델이 찾아야 하는 함수는 다음과 같습니다.
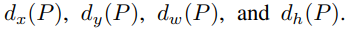
x, y는 이미지의 크기에 상관없이 위치만 바꿔주면 되고, w, h는 이미지의 크기에 비례하여 조정해야 합니다. 이런 특성을 반영하여 예측된 식은 다음과 같습니다.
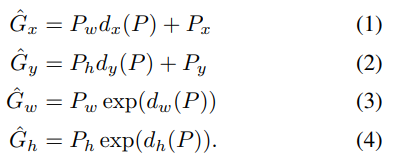
위 식을 통해, 우리가 최종적으로 예측하고자 하는 함수 d는 다음과 같이 나타낼 수 있습니다.
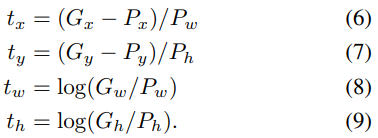
이렇게 만들어진, P, G, G^, t, d를 통해 논문에서는 Loss함수를 만들었습니다. 모델은 Loss함수를 통해 학습합니다. Loss함수에는 L2 규제를 적용했으며, 람다는 1000으로 설정했습니다.
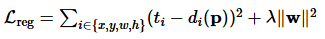
정리하자면, R-CNN에서는 Bounding Box 문제를 Regression 문제로 만들어서 해결했습니다.
4. Conclusion

최근 Object Detection과 관련한 발전은 미진했고, 논문에서는 이를 해결하고자 노력하였습니다.
「PASCAL VOC 2012」에서 이전보다 30% 뛰어난 성능을 보여준 R-CNN은 Region Proposal과 CNN의 결합으로 만들어낸 모델입니다. 이는 기존에 존재하는 기술의 통합을 통해 만들어낸 결과로써 중요성을 가집니다.
Reference
R-CNN 논문(Rich feature hierarchies for accurate object detection and semantic segmentation) 리뷰
논문 리뷰 - R-CNN 톺아보기
갈아먹는 Object Detection [1] R-CNN
