인공지능 특히, 딥러닝을 공부하면서 옵티마이저를 모르고 넘어가려는 분은 없을 거라고 생각합니다.
하지만, 경사하강법과 옵티마이저의 차이를 제대로 알지 못하는 것이 실제 모습입니다.😂
이번 기회를 통해 저는 물론이고 이를 읽는 모든 사람이 옵티마이저에 대해 확실히 알기를 바라는 마음입니다.
피드백은 언제나 환영입니다.😊
📚 Optimizer(옵티마이저)
'옵티마이저(Optimizer)'라는 말을 들으면 어떤 그림이 떠오르시나요?
저는 처음 옵티마이저라는 말을 듣고 "무언가를 최적화 해주는 건가?"라고 생각했습니다.
옵티마이저는 "파라미터 값을 최적으로 업데이트해주는 알고리즘"입니다.
이 정의를 보면 경사하강법(Gradient Descent)과 비슷한 개념이라고 생각이 듭니다.
기존에는 경사하강법을 적용해 업데이트된 weight값을 그대로 적용했다면, 옵티마이저를 이용해 한차례 더 weight값을 업데이트한다고 보면 됩니다.
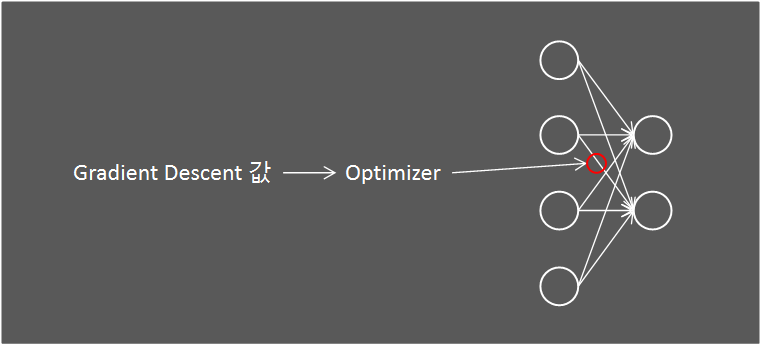
옵티마이저는 경사하강법중 특히 SGD(Stochastic Gradient Descent)에서 파생된 경우가 대다수 입니다.
경사하강법에 대해선 앞에서 다뤘으니 참고해 주시면 감사하겠습니다.
경사하강법(Gradient Descent)을 공부해보자
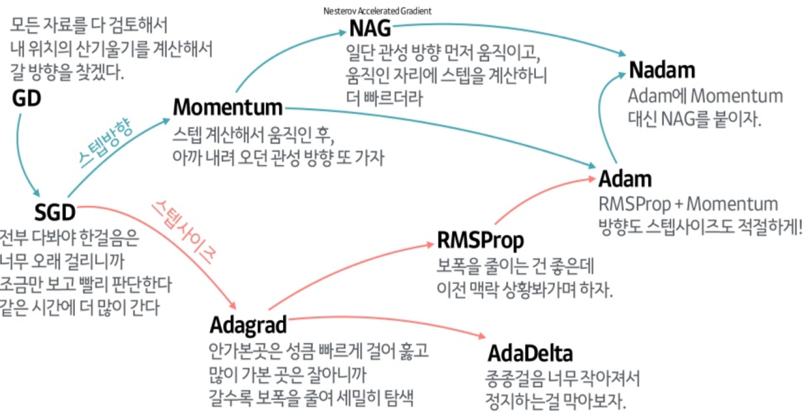
✅ Momentum
Optimizer 방식으로는 크게 이전의 미분 값을 반영하는 방법, learning rate를 조절해주는 방법으로 나누어 집니다.
Momentum은 이전의 미분 값을 반영하는 방법입니다.
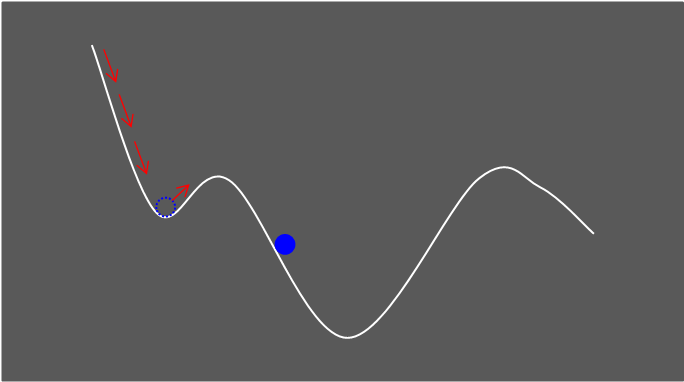
기존에 내리막길이었다면 현재가 오르막길이어도 내려가던 관성을 조금 더 유지해준다고 생각하시면 편합니다.
Momentum을 좀 더 수학적으로 파고들어 알아봅시다.
기존 경사하강법은 다음과 같은 방법으로 w값을 업데이트 했습니다. (여기서 w는 파라미터 입니다.)
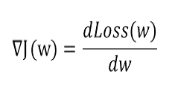
하지만, 이런 방법은 이전 Gradient값을 반영할 수 없습니다.
Momentum은 이런 문제점을 인식하고 과거의 Gradient값을 반영하기 위해 momentum계수를 추가합니다.
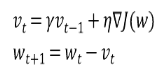
이런식으로 Momentum을 적용하게 되면 비교적 최근 Gradient를 더 반영하게 되고, 비교적 과거의 Gradient는 영향력이 줄어들게 됩니다.
momentum계수는 0 ~ 1사이값을 사용합니다. 보통 0.9를 많이 사용한다고 합니다.
SGD기법을 이용해 w를 업데이트하게 되면 지그재그로 많이 요동치며 향하게 됩니다.
하지만, Momentum을 적용하면 비교적 덜 요동치며 Global Minima로 이동하게 됩니다.
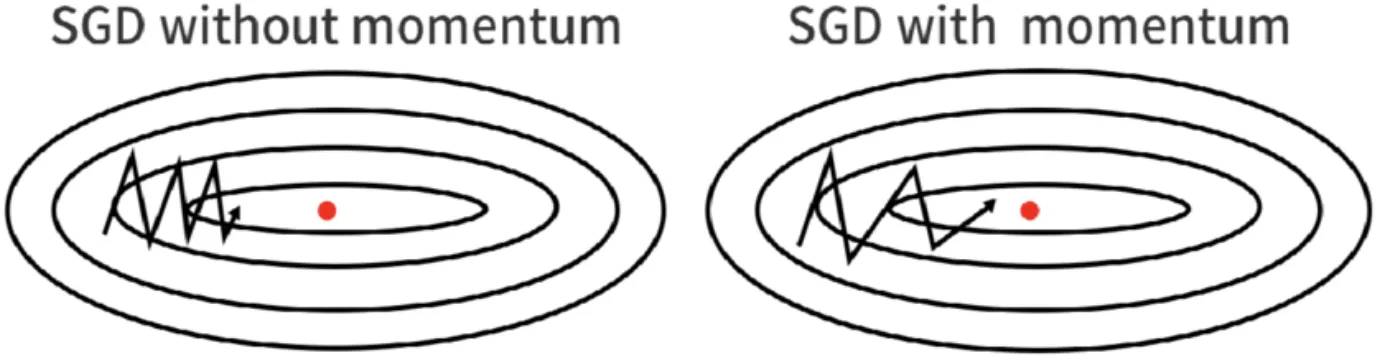
image 출처: Momentum (SGD)
✅ AdaGrad(Adaptive Gradient)
앞서 Mometum이 과거의 Gradient를 반영하는 기법이었다면, AdaGrad(Adaptive Gradient)는 learning rate를 수정하는 기법입니다.
AdaGrad는 이전에 큰 learning rate였다면 보다 작은 learning rate로, 작은 learning rate였다면 보다 큰 learning rate를 적용시킵니다.
이를 위해 이전 learning rate의 제곱 합에 루트를 씌워 learning rate를 나누는 수학적 기법을 사용합니다.
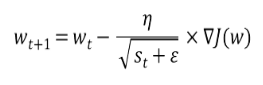
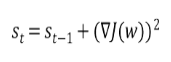
AdaGrad는 최저점에 가까워질수록 learning rate가 작아진다는 특징이 있습니다.
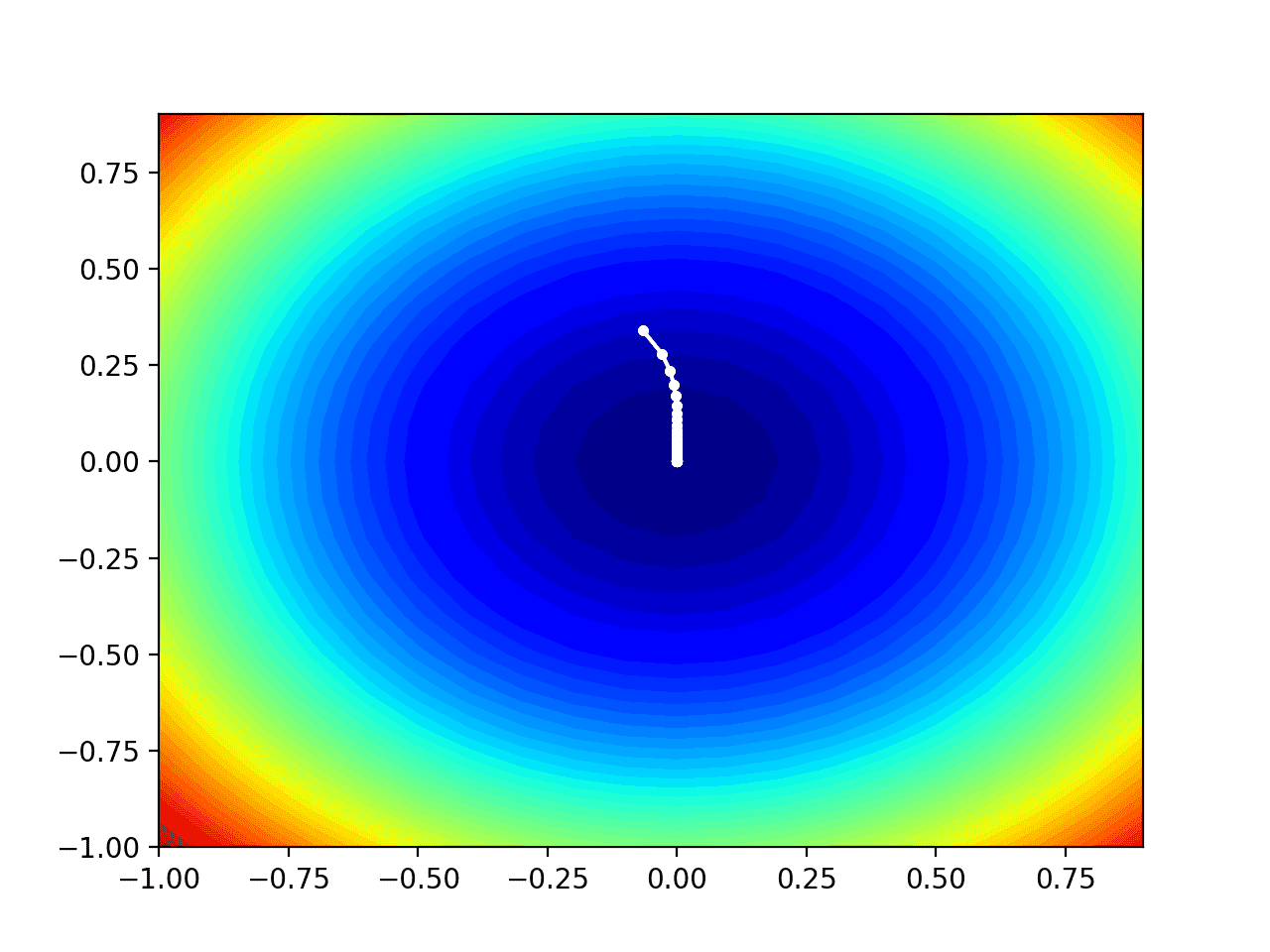
image 출처: Gradient Descent With AdaGrad From Scratch
하지만, AdaGrad는 아무리 과거의 learning rate값이 작더라도 계속 제곱되어 합해지기 때문에 learning rate가 최종적으로는 너무 작아진다는 단점이 있습니다.
✅ RMSProp
RMSProp은 AdaGrad의 단점을 해결하고자 지수가중평균법(Exponentially WeightedAverage)을 적용한 옵티마이저입니다.
지수가중평균법이란, 오래된 데이터가 미치는 영향을 지속적으로 감소시켜주는 방식입니다.
AdaGrad와 수학적 기법은 비슷하지만 기존 s에 지수가중평균을 적용한 것에서 차이가 있습니다.
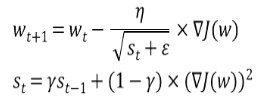
s함수에서 첫 번째 항은 과거의 값이라고 생각하면 되고 두 번째 항은 최근 값이라고 생각하면 됩니다.
감마 값은 1보다 작은 값이기 때문에 과거 값의 중요성이 상대적으로 줄어들게 됩니다.
✅ Adam
Adam은 update gradient value에 따라 learning rate를 동적으로 바꿔주는 동시에 update gradient value에 Momentum을 이용하는 방식입니다.
다만, 기존의 Momentum방식과는 차이가 있는데 지수가중평균법을 적용하는 것 입니다.
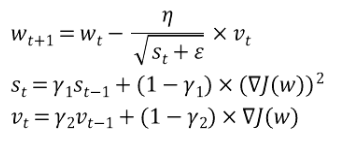
RMSProp방식과 Momentum방식을 섞었으며 기존 Momentum방식에서 지수가중평균법을 적용한 것 입니다.
Adam을 사용함으로써 learning rate와 gradient값을 한번에 동적으로 변경할 수 있게 된 것 입니다.
정리하자면 Adam은 RMSProp과 Momentum을 합친 방식으로, 진행하던 Gradient에 관성을 주고 이전 곡면 변화율에 맞춰 learning rate를 변동하는 알고리즘입니다.
다음은 SGD, Momentum, AdaGrad, RMSProp이 Global Minima를 찾아가는 과정을 잘 설명해준 영상입니다.
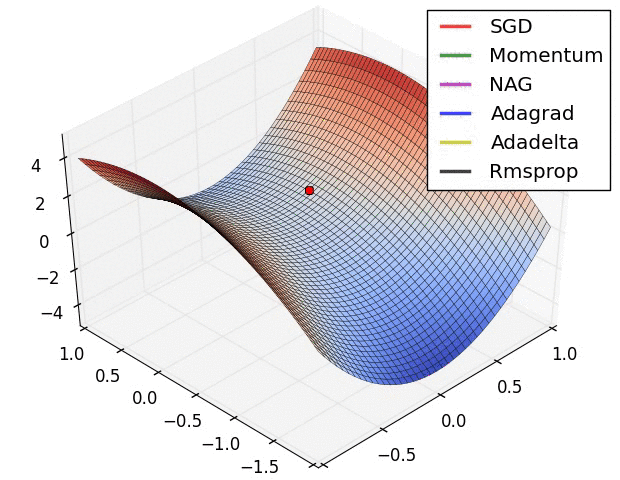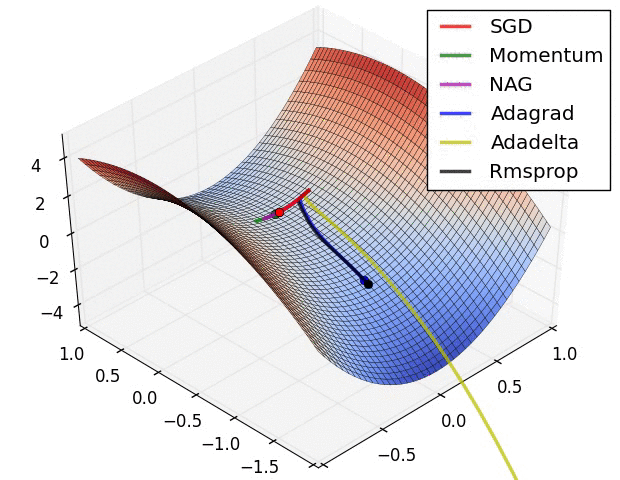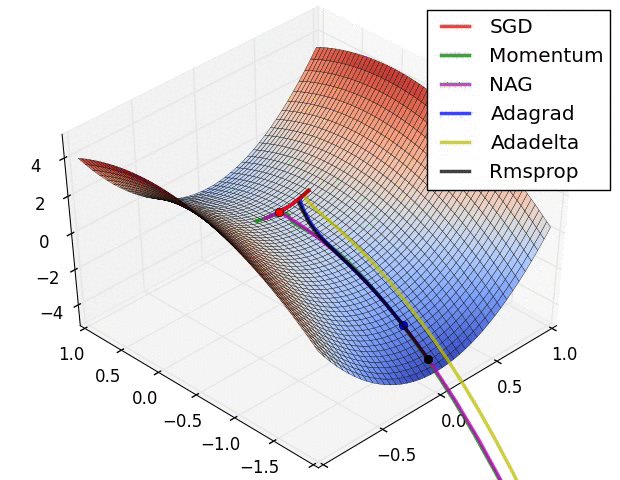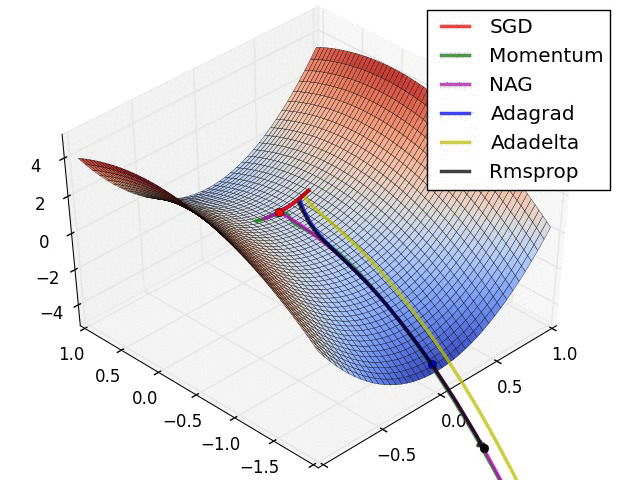
Adam도 포함한 영상이 있었는데 어디갔는지 못찾겠습니다.. 찾으면 다시 수정하겠습니다..
Reference
Comprehensive overview of solvers/optimizers in Deep Learning
Momentum (SGD)
지수가중평균(Exponentially WeightedAverage)
[딥러닝] 딥러닝 최적화 알고리즘 알고 쓰자. 딥러닝 옵티마이저(optimizer) 총정리
