오늘은 크로스 엔트로피 함수에 대해 공부했습니다.
📚 Cross Entropy(크로스 엔트로피)
크로스 엔트로피 함수는 다중 분류에서 사용되는 비용 함수입니다.
비용 함수는 모델이 예측한 값과 실제 값의 차이를 나타내는 함수입니다.
기존 회귀에서는 MSE, RMSE, RMSLE등의 비용 함수를 많이 사용했습니다.
하지만, 다중 분류에서 위 식은 거의 쓰이지 않습니다.
크로스 엔트로피는 모델의 출력이 다중이냐 단일이냐에 따라 Categorical Cross Entropy, Binary Cross Entropy로 나뉩니다.(Cross Entropy를 여기서 CE라고 말하겠습니다.)
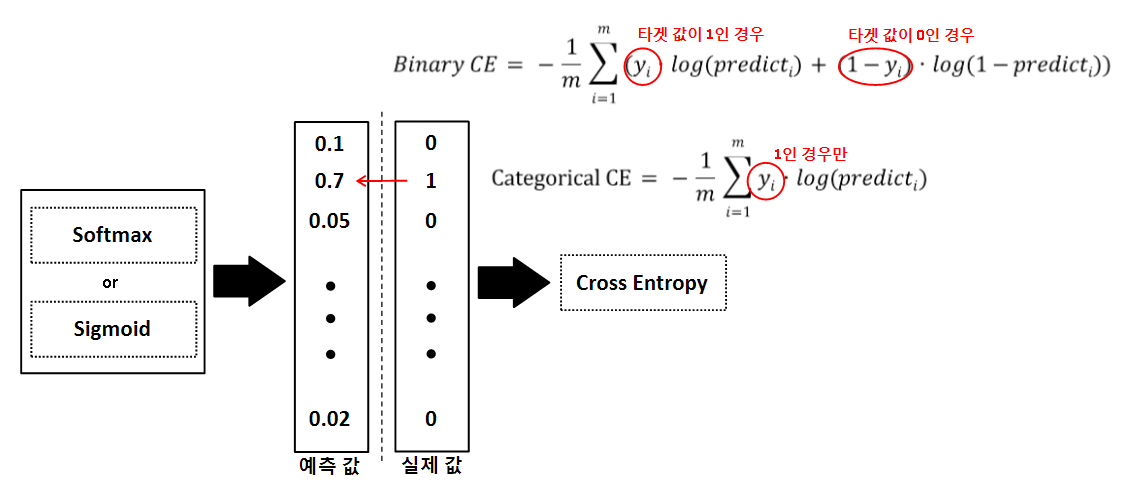
Categorical CE와 Binary CE의 식은 다음과 같습니다.

분류의 경우 Output Layer의 활성화 함수는 다중 분류인 경우 Softmax, 이진 분류인 경우 Sigmoid함수를 사용합니다. 그렇다면, Categorical CE는 Softmax와, Binary CE는 Sigmoid와 짝을 이룬다고 생각하면 편할 것입니다.
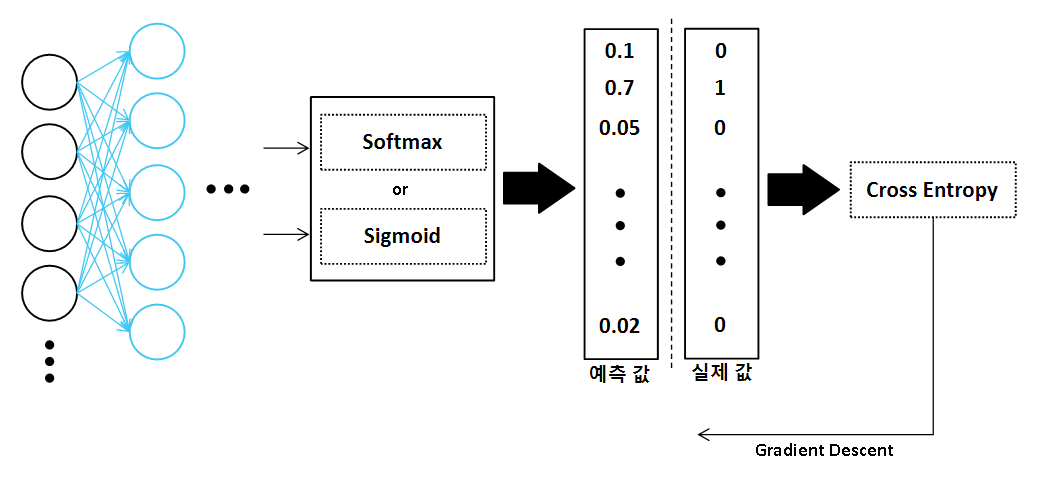
✅ Cross Entropy 특징
크로스 엔트로피는 실제 클래스에 해당하는 결과 값에만 Loss를 부여합니다.
예를들어, Categorical CE의 경우 i번 째에 해당되는 예측 값과 결과 값을 기반으로 식을 계산합니다.
이때, 결과 값은 원-핫 인코딩이 되어 있으므로 0과 1의 값으로만 존재합니다.
식에서 i번 째 결과 값을 곱하므로 결과 값이 1인 경우(해당되는 클래스)에만, Loss를 부여하게 됩니다.
Binary CE의 경우에는 타겟 값에 해당되는 부분만 Loss를 적용합니다.
또한, log함수의 특성상 아주 잘못된 예측 결과에는 매우 높은 Loss를 부여하게 됩니다.
기존의 Squared Error는 오류 값에 대해 상대적으로 작은 오류의 경우 변화량이 컸지만, CE는 변화량이 적습니다.(오류 값이 그렇게 크지 않은 경우)
반면에, 오류 값이 상대적으로 많이 증가한 경우 Squared Error는 변화량이 작았지만, CE는 변화량이 큽니다.
📜 Reference
딥러닝 CNN 완벽 가이드 - TFKeras 버전
[CNN] Activation Function(활성화 함수)
