중요 참고 사이트
https://neptune.ai/blog/image-classification-tips-and-tricks-from-13-kaggle-competitions
Baseline
Data Analysis -> Data Processing -> Modeling -> Training
-
Data Analysis
- EDA
-
Data Processing
- Dataset
- Pre-processing
- Generator
- Augmentation
-
Modeling
- Torch Model
- Pretrained Model
- Loss, Opt, Metric
-
Training
- Training Process
- Ensemble
DATA
Vanilla Data
- Vanilla Data를 모델이 좋아하는 형태의 Dataset으로 바꿔준다.
Pre-processing
Train / Validation
- test data는 건드리면 안됨
Data Augmentation
-
데이터를 일반화하는 가정
-
여러가지 상황을 고려해줄때 사용

-
torch.transforms 이용
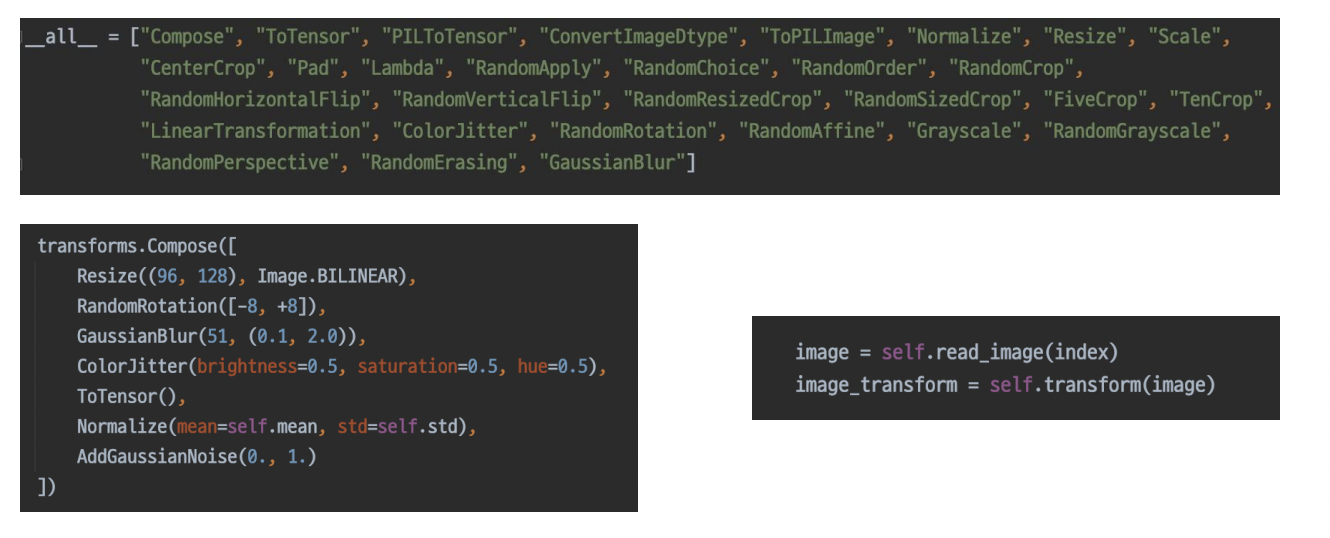
-
albumentations 이용
- torch.transforms보다 다양하고 빠르다.

- torch.transforms보다 다양하고 빠르다.
-
data augmentation은 무조건 항상 좋은 결과를 가져다 주는 것은 아니다.
-
transforms.Compose()를 할 때, Resize와 rotation의 순서로도 dataset의 생성 속도가 엄청나게 차이난다.

validation data set
- test data set과 비슷하게 구성되는게 가장 좋음. 그러기 위해서 test data set의 구성을 예상해보고 그에 맞춰서 validation set을 어떤식으로 나눌지 생각봐야 한다. (ex | 인물별, 클래스별, ...)
