LinearRegression
- loss function
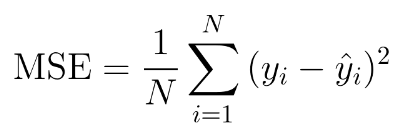
loss function 을 최소화 시키는 h를 찾는것이다.
loss function 는 2차함수이기 때문에 미분해서 미분값이 0인곳을 찾으면 보통 최소값이다.
Supervised Learning (지도학습)
머신러닝은 주어진 데이터 x를 이용해 y를 예측하는것이다.
y 를 예측하기 위해 를 대략적으로 알려주는것이 지도학습니다.
- classification : y 가 범주형일때
- regression : y 가 연속적일때
머신러닝은 결국 loss function 을 정의하고 이를 최소화 시키는 것!
- 분류와 회귀 모두 이를 위한 최적화 기법들이 있다.
Training error & Validation error
Training error : 학습 시킨 데이터에 대해서 발생하는 오차
Validation error : 학습에 사용하지 않았던 데이터에 대해서 검증한 오차

under fitting : 모형이 너무 심플할 경우 (학습을 잘 못했다.)
over fitting : 모형이 너무 복잡할 경우 (너무 세부적인 것 까지 학습했다.)
하이퍼파라메터
이런 모델 복잡도에 하이퍼파라메터가 영향을 준다 .
하이퍼파라메터란 모델의 특성을 규정하는 모델의 외적인 요소이다. (사람이 결정해 줘야 하는 요소라고 생각하면 된다.) 하이퍼파라메터를 조절하면서 가장 좋은 모델을 찾는 과정이 필요하다.
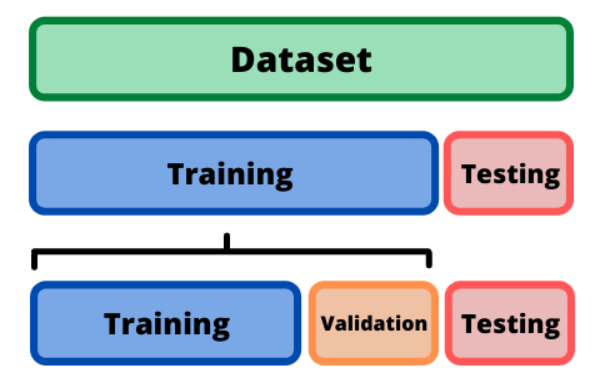
- validation 으로 먼저 검증해보고, 괜찮은 하이퍼파라메터를 찾아서 학습시킨 다음에 test 에 적용하는 방식이 제일 좋다.

- cross validation 방식은 데이터가 적을때 사용하면 좋다. train데이터를 쪼개서 번갈아가면서 validation 데이터가 되어주는 방법이다.

열심히 사는 중