Supervised Learning
- Classification : 범주형을 예측
- 이미지분류, 텍스트 분류 등
- Regression : 연속형을 예측
- 주식, 날씨, 온도, 센서값 등
하이퍼파라메터란
머신러닝에서 하이퍼파라미터는 최적의 훈련 모델을 구현하기 위해 모델에 설정하는 변수다. 하이퍼파라미터 튜닝 기법을 적용하여 훈련 모델의 최적값들을 찾을 수 있다.
하이퍼파라메터로 모델 복잡도를 통제할 수 있다.
파라메터와의 차이
파라메터란 매개변수라는 뜻이다.
머신러닝 모델에는 많은 매개변수가 있는데 그 중에서 데이터에 의해 정해지는 매개변수가 있고, 사용자가 조절해줄 수 있는 매개변수가 있다.
그래서 데이터에 의해서 정해진(바꿀 수 없는) 매개변수를 '파라메터' 라고 하고 사용자가 조정해줄 수 있는 매개변수를 '하이퍼파라메터'라고 한다.
머신러닝 모델의 파라메터의 예
데이터를 통해서 구해진 값이며 모델 내부적으로 결정된다.
평균(μ)
표준편차(σ)
분산
IQR 등이다.
하이퍼파라미터의 예
학습률
손실 함수
일반화 파라미터
미니배치 크기
에포크 수
가중치 초기화
은닉층의 개수
k-NN의 k값
하이퍼파라미터의 튜닝 기법
그리드 탐색
랜덤 탐색
베이지안 최적화
휴리스틱 탐색
모델 복잡도
Bias - Variance
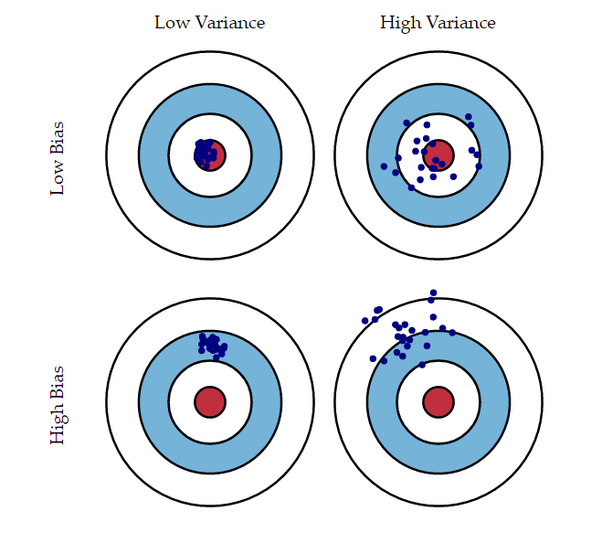
Bias
편향이라는 뜻으로 실제 값에서 예측값이 얼마나 치우쳐져 있는지 즉 오차를 뜻한다.- bias 는참 값들과 추정 값들의 차이(or 평균간의 거리)를 말한다.

빨간색이 실제값, 파란색이 예측값, 회식이 예측값의 평균이다.
bias 는 빨간값과 회색값에 대한 이야기이다.
bias를 수식적으로 보면 아래와 같다.
실제값과 예측평균값의 거리를 구하기 위해서 제곱을 해준다.

Variance
분산을 의미한다.- variance는 예측 값들끼리 서로 흩어진 정도를 의미합니다.
- 분산은 위의 그림에서 파란점들과 회색점에 대한 이야기다.

편향과 분산은 모델이 복잡하게 생긴 정도와 관련이 있다.
편향(Bias)과 분산(Variance)은 한쪽이 증가하면 다른 한쪽이 감소하고, 한쪽이 감소하면 다른 한쪽이 증가하는 경향을 보인다.
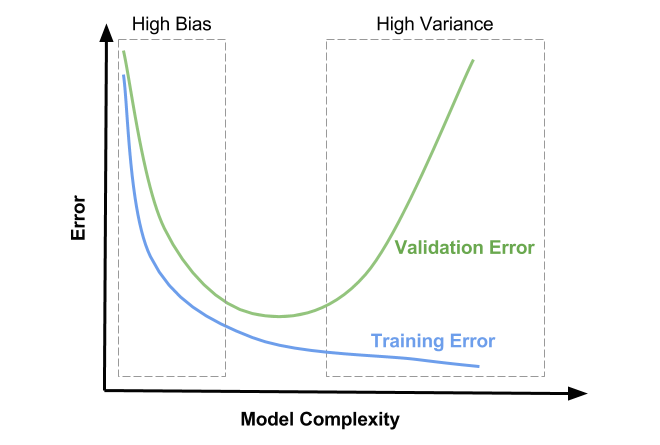
모델이 데이터를 학습하는 횟수가 늘어날 수록 모델이 복잡한 정도가 늘어나게되는데, train 데이터셋을 외우게 되기 때문이다. 그래서 학습할수록 train error 는 줄어들지만, validation error는 어느정도까지 줄어들다가 상승한다. 너무 미세하게 학습을 했기 때문에 데이터가 변했을때 오차가 커지는것이다.
validation error 가 최소인 지점에서 학습을 멈추는게 가장 좋다.
-회귀 예시
그림에서 점들이 실제값이고, 점선이 예측모델이다.
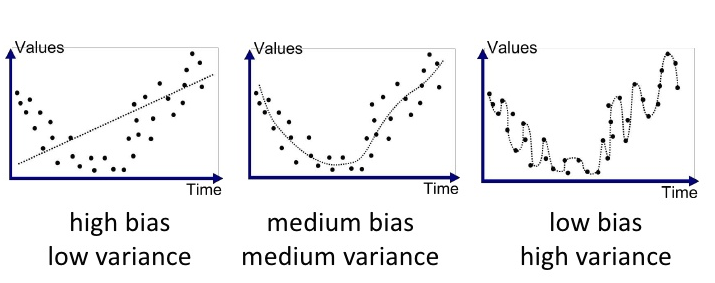
왼쪽부터, 복잡도가 낮은 모델 > 중간모델 > 복잡도가 높은모델이다.
- 분류 예시
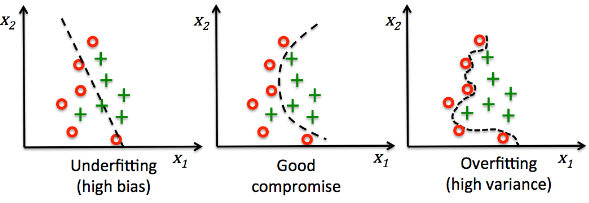
왼쪽부터, 복잡도가 낮은 모델 > 중간모델 > 복잡도가 높은모델이다.
모델이 너무 단순하게 생겼으면(=훈련이 너무 덜 되어 있으면) 정답을 잘 내놓지를 못하고
모델이 너무 복잡하게 생겼으면(=훈련이 너무 심하게 되어 있으면), 훈련용 데이터를 외우게 된 수준이기 때문에 새로 제시되는 데이터에 대해서 틀린 답을 내놓을 가능성이 높다.
