데이터 통계 분석 방법은 자료의 속성과 분석의 목적에 따라 달라진다.
따라서 자료에 대한 이해와 자료의 속성을 잘 파악해야만 적절한 통계 분석 방법을 적용할 수 있다.
수치형자료(Numerical data)
수치형자료는 관측된 값이 수치로 측정되는 자료를 말한다.
양적자료(Quantitative Data)라고도 한다.
- 키
- 몸무게
- 시험성적
- 발생 횟수
- 출산 횟수
연속형자료
연속형자료는 키, 몸무게와 같이 연속적인 자료를 말한다.
이산형자료
출산 횟수처럼 셀 수 있는 자료를 말한다.
범주형자료(categorical data)
범주형자료는 관측 결과가 몇 개의 범주 또는 항목의 형태로 나타나는 자료를 말한다.
- 성별: 남자, 여자
- 혈액형: A, B, O, AB
- 선호도: 좋다, 싫다, 그저그렇다
범주형 자료도 수치형 자료처럼 표현 할 수 있다.
남자를 1 여자를 0으로 표현 할 수도 있고, 선호도를 점수로 나타낼 수도 있다. 하지만 표현만 숫자일 뿐이지, 남자가 여자가 1만큼 차이가 난다는 뜻이 아니다. 숫자로 표현되어 있는 범주형 자료를 잘 구분해야 한다.
범주형데이터임에도 bool, int, float 다 가능하기 때문이다.
순위형자료
범주간에 순서가 의미있는 자료를 말한다.
매우좋다, 좋다, 그저그렇다, 싫다, 매우싫다 처럼 순서가 있는 경우이다.
명목형자료
범주간에 순서의 의미가 없는 자료이다. 분류를 목적으로 한다. ex) 혈액형
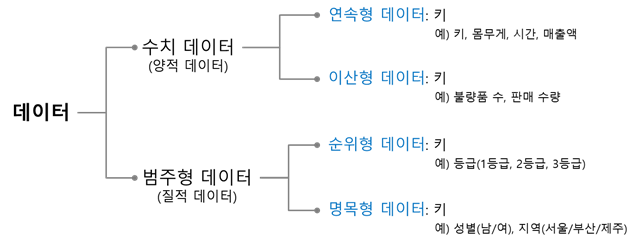
자료에 따라서 분석 방법과 시각화 방법이 달라진다.
수치형자료 데이터 파악하기 with pandas
import pandas as pd
import numpy as np
# 데이터를 시각화 할 때 필요한 라이브러리들
import seaborn as sns
import matplotlib.pyplot as plt
df = sns.load_dataset("penguins")
#일부 데이터만 보기
df.head()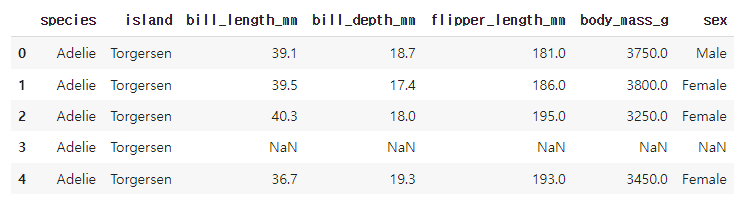
# 데이터 길이
len (df) # 344
df.shape # (344, 7)
# 요약정보 보기
df.info()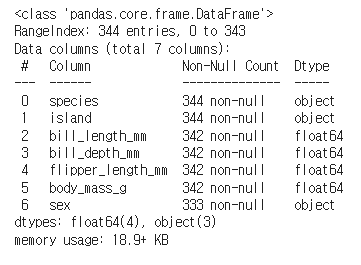
어떤 컬럼들이 있고, 어떤 타입인지, 결측치가 몇개나 있는지 대략적으로 알 수 있다.
# 결측치 합계
df.isnull().sum()
# 결측치의 비율
df.isnull().mean()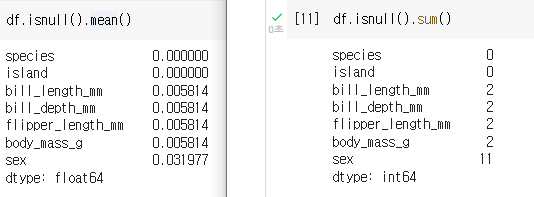
비율은 X100 해서 생각하면 된다.
describe()
pandas 객체의 설명적 통계량을 생성하는데 사용된다.
NaN 값을 제외한 데이터의 분포 형상, 중심 경향, 분산 등이 표현된다.
# 수치형 자료의 기술통계 보기
df.describe()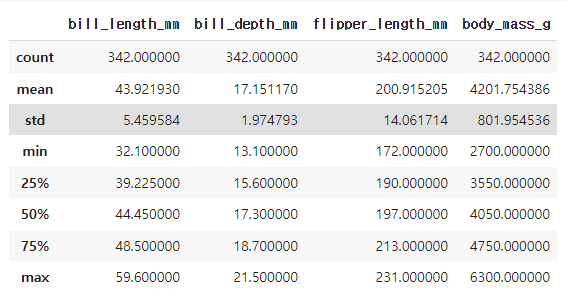
count 는 결측치를 제외한 갯수이다.
mean 평균 / std 표준편차
min 최솟값 / max 최대값
# 범주형 자료의 기술통계 보기
df.describe(include="object")
df.describe(include=[object])
df.describe(exclude=[np.number])
# 위의 세개 다 결과가 같다.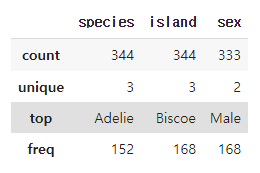
Count 총 데이터 수
unique 중복없이 나오는 고유한 데이터 값의 갯수
top 최빈값
freq 최빈값이 몇번 나왔는지
# 수치형 데이터를 범주형 데이터로 바꾸는 법
df["bill_length_mm"].astype("str").describe()
# 범주형으로 결과가 나온다.# 유니크값의 갯수를 구한다. NaN 제외하고
df["body_mass_g"].nunique()
# 유니크 값을 list 로 반환한다.
df["body_mass_g"].unique()
TIP. 특정 컬럼 선택
df["island"] # Series
df[["island"]] # dataFrame
df[["island", "sex"]] 컬럼 두개 뽑을 때는 dataFrame 으로 뽑아야 한다.
TIP. plt에서 사용 가능한 색상을 코드로 알아 볼 수있다.
plt.colormaps?
print(plt.colormaps())
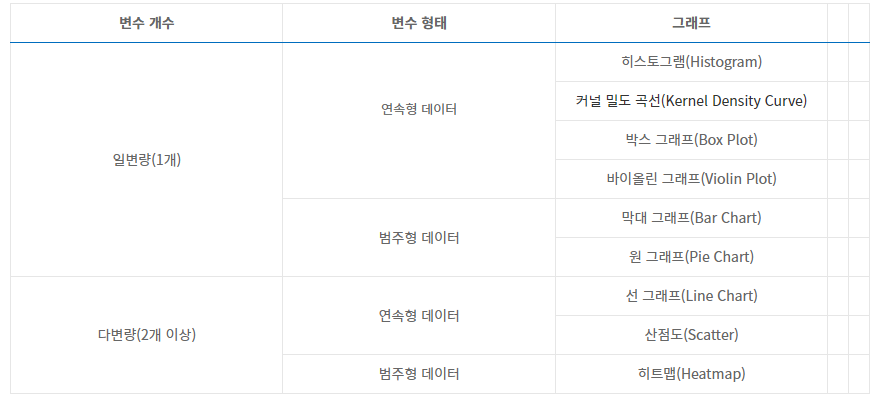
# ['Accent', 'Accent_r', 'Blues', 'Blues_r', 'BrBG'...]수치형 자료 시각화하기 with seaborn
결측치를 시각화해서 나타 낼 수 있다.
plt.figure(figsize=(14,10))
sns.heatmap(df.isnull(), cmap="gray")
# 결측치가 있는 곳을 나타낸다. 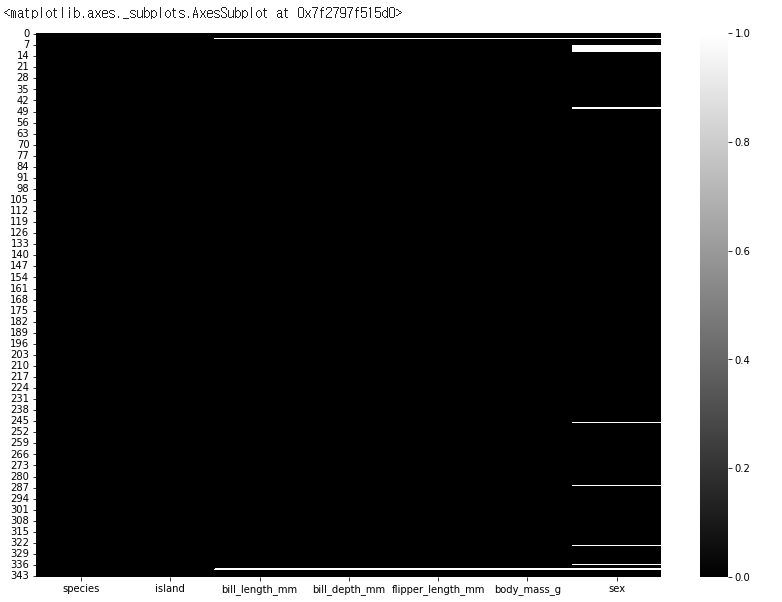
pandas 에서 histogram 그리기
# hist()를 통해 전체 수치변수에 대한 히스토그램 그리기
df.hist(figsize=(10,14), bins=15)
plt.show() # 로그를 보고싶지 않을 때 쓴다. 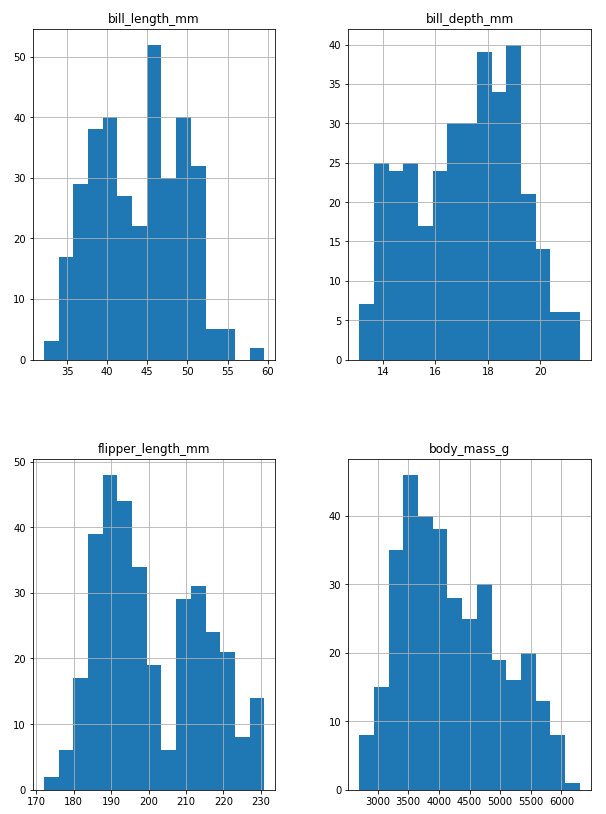
수치형 데이터에 대해서 히스토그램을 나타낸다.
bin 의 default 값은 10이고, 막대 영역의 범위를 나타낸다.
bin 의 값이 n 일 때, 데이터의 (범위 / n+1)이 막대 영역의 범위이다.
seaborn 에서는 서브플롯을 제공 하는 그래프를 따로 제공한다.
boxplot 은
대표값만 표현하기 때문에 데이터 분포를 알 수가 없다.
상자와 수염은 4분위수를 표현하고 밴드는 2분위수(중간값)이다.
그리는 방법
- 데이터에서 각 사분위수를 계산한다.
- 데이터값들을 줄을 세워서 생각하자. - 1사분위와 3사분위를 밑변으로 하는 직사각형을 그리고
2사분위에 해당하는 위치에 선분을 그린다.
violin plot 같은 경우에는 FacetGrid 를 제공하지 않는다.
col 이나 col_wrap 같은 기능이 violin plot 에는 없다.
그래서 서브플롯을 사용하기 위해 catplot 을 사용한다.
seaborn은 알아서 통계값을 그려준다.
수치형변수를 시각화 할때, 범주형 변수를 시각화 할 때 쓰는게 다르다.
seaborn 에 있는 example 을 다 따라해 보는걸 추천한다.
