파이널
1.[멋사][F-study] 허깅페이스

n 행시 구현을 위해서 허깅페이스 공부시작참고자료\[DLD 2022] 허깅페이스로 나만의 BERT Pretraining 해보기: bert 개념이 아직 생소해서 듣다가 포기210407 자연어처리 4차강의: huggingface 라이브러리: 그나마 하던 내용이랑 비슷해서
2.[멋사][F-study] GPT & 파인튜닝

https://aifactory.space/learning/detail/2177인풋레이어 -> 임베딩 레이어 -> 디코더레이어 -> logit 레이어디코더레이어가 핵심이다. 여기서 파라메터수를 조정하고 그에 따라 텍스트 생성 성능이 바뀔수 있다. 텍스트 생성을
3.[모델] Transformer 의 BART 모델
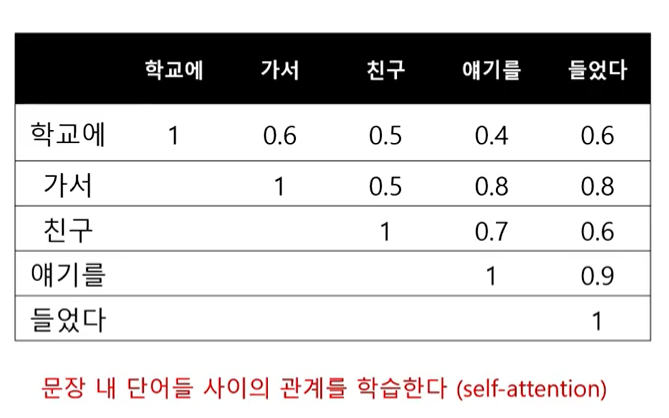
요약1\. Transformer 구조라는 건 encoder - decoder 로 이루어진 seq to seq model 이다. 2\. BERT 는 transformer 에서 encoder 만 가지고 만든 모델 (모델이라기 보다는 엄밀히 말하면 training 방식 자체
4.[BART] 모델
Token Masking : BERT의 사전학습 방식으로 문장의 특정 토큰을 MASK 원소로 대체하여 해당 자리에 들어갈 단어를 예측하는 학습 방식이다. Token Deletion : 토큰을 임의로 삭제하여 어느 위치의 토큰이 사라졌는지를 학습한다. 참고BART논문리뷰
5.[파이널] Few Shot Learning , 메타 러닝
딥러닝은 데이터의 양이 많은 수록 학습을 잘한다. 여기에는 다양하고 품질이 우수한 데이터와 막대한 컴퓨팅 자원이 필요하다. 기계는 소량의 데이터로는 학습할 수 없을까??데이터수가 매우 적을 때 활용되는방법이며,퓨삿 러닝시에는 훈련용 서포트 데이터(Support data
6.[BART] 모델 사용해보자!!! vs GPT
참고Korean SmileStyle Dataset으로 문체 스타일을 바꾸는 모델 만들어보기
7.[GPT] 파라메터 알아보기
https://huggingface.co/docs/transformers/v4.25.1/en/model_doc/gpt2PreTrainedTokenizer(https://huggingface.co/docs/transformers/v4.25.1/en/ma