GPT

인풋레이어 -> 임베딩 레이어 -> 디코더레이어 -> logit 레이어
디코더레이어가 핵심이다.
여기서 파라메터수를 조정하고 그에 따라 텍스트 생성 성능이 바뀔수 있다.
텍스트 생성을 위한 평가지표
- Perplexity, BLUE, ROUGE



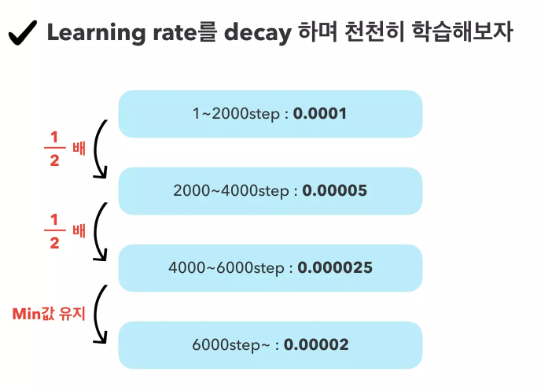

참고링크
http://aidev.co.kr/index.php?mid=chatbotdeeplearning&page=8&document_srl=7033
https://github.com/haven-jeon/KoGPT2-chatbot
https://keep-steady.tistory.com/6
https://github.com/IllgamhoDuck/ko_novel_generator
오늘 저녁까지 파인튜닝 잘 모르겠으면
이 책을 사버리자
Do it! BERT와 GPT로 배우는 자연어 처리
참고자료
[ML] GPT2를 활용한 미세 조정(fine-tuning) 학습
BERT에서는 트랜스포머의 인코더 구조만 사용한 반면 GPT1에서는 트랜스포머의 디코더 구조만 사용했다.
BERT에서 인코더를 사용했던 것과 달리 GPT 에서 디코더를 사용했다는 것은 순방향 마스크 어텐션을 사용했다는 것으로 볼 수 있다.BERT에서 진행한 사전 학습 방식은 두 가지로 구성돼 있다 : 마스크 언어 모델과 다음 문장 예측 학습 방식을 사용했다.
GTP1에서는 전통적인 언어 모델 방식, 즉 앞의 단어들을 활용해 해당 단어를 예측하는 방식을 사용했다.
문장에서 앞의 단어들을 활용해 다음 단어를 예측하는 방식으로 사전 학습을 진행한다.
라벨이 별도로 존재하지 않는 데이터라도 학습을 진행할 수 있기 때문에 비지도 학습으로 분류되고, BERT와 마찬가지로 많은 데이터를 통해 모델의 가중치를 사전 학습할 수 있다.
사전 학습 모델과 미세 조정의 차이점은 무엇일까?
사전 학습 모델은 아주 큰 데이터셋으로 학습해서 가장 일반화된 언어 생성 모델을 만드는 것이 목적이다. 반면 미세 조정 모델은 생성하고자 하는 목적을 가진 데이터셋으로 학습해서 특정한 결과를 얻을 수 있는 언어가 생성될 수 있게 하는 것이 목표다.
참고
개인 프로젝트: 나처럼 말하는 봇을 만들어보자!
BERT나 Electra같은 양방향 모델은 강력한 성능을 자랑하지만, 생성 태스크에는 맞지 않는 모델이다.
Transformer와 같은 인코더 - 디코더 모델이나, 혹은 GPT 종류와 같이 디코더를 기반으로 한 모델이 생성 태스크에 적합한 모델이다.위 모델들은 사전학습 모델(Pre-trained Model)에 속한다. 사전학습 모델은 기존에 대용량의 데이터로 미리 학습을 해놓고, 특정 도메인에 속하는 상대적으로 적은 데이터로 미세조정(Fine-Tunining)해 사용하는 모델이다.
