요약
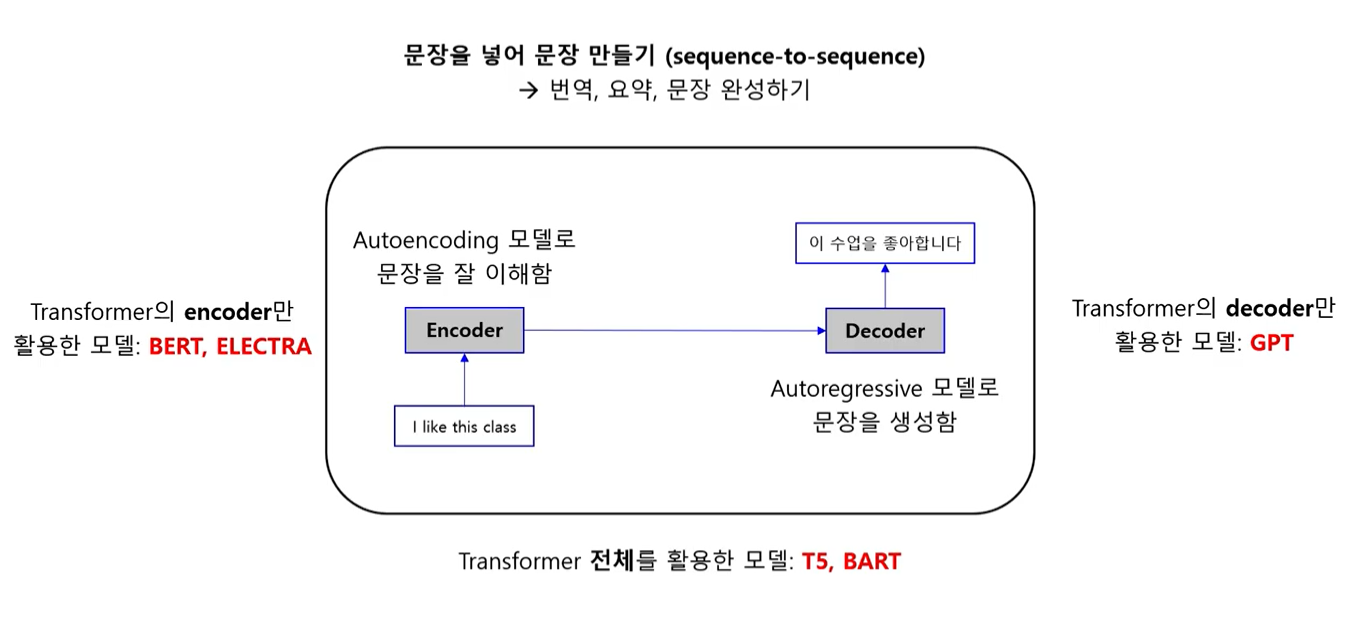
1. Transformer 구조라는 건 encoder - decoder 로 이루어진 seq to seq model 이다.
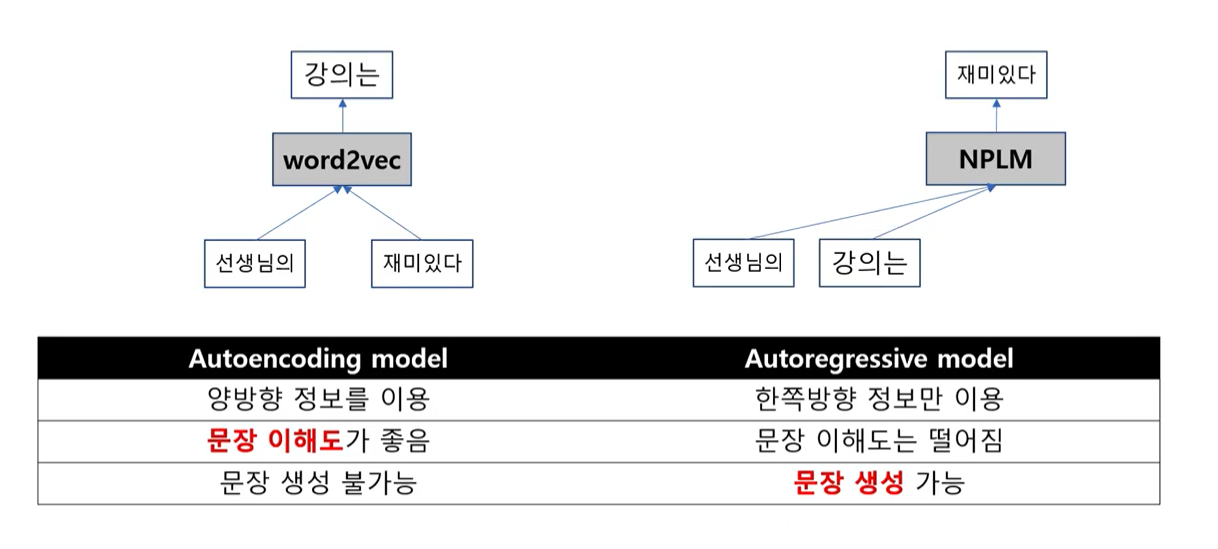
2. BERT 는 transformer 에서 encoder 만 가지고 만든 모델 (모델이라기 보다는 엄밀히 말하면 training 방식 자체를 의미하는 거라고 보는 게 맞다)
3. GT2 는 transformer decoder blocks 만 가지고 만든 모델이다.
4. BART 는 bert encoder + gpt2 decoder 이다.Q. 그럼 결국 BART 도 transformer 아닌가?
A. 조금씩 차이가 있다. 예를 들어 transformer 의 decoder 에는 encoder-decoder attention 이 있는데 gpt2 에서는 encoder 블록이 없기 때문에 이 layer 가 없음. 그렇기 때문에 정확히 transformer 같다 라고 하기에는 차이가 있는 듯..? BART 는 결국 transformer based language model 인 건 맞음.
BART : Bidirectional Auto-Regressive Transformer
-
BART는 BERT와 GPT를 하나로 합친 형태로, 기존 Sequence to Sequence 트랜스포머 모델을 새로운 Pre-training objective를 통해 학습하여 하나로 합친 모델이다.
-
bidirectional : 양방향으로 언어 시퀀스의 토큰들을 어텐션 메커니즘을 통해 모두 반영하여 문자를 인코딩 한다.
BART 논문 리뷰
-
BERT는 엔코더이기 때문에 Generation task에 대응할 수 없다.
-
GPT는 디코더만 존재하기 때문에 양방향 문맥정보를 반영하지 못한다.
-
BART는 Bidirectional과 Auto-Regressive Transformer를 합친 모델이다.
-
BART는 seq2seq 모델로 만들어진 denoising autoencoder로, 많은 종류의 downstream 태스크에서 잘 동작한다.
-
BART의 사전학습(Pretraining) 2가지 단계
1) 텍스트가 임의적인 noising 함수를 통해 오염된다.(다른 토큰[Mask]으로 교체되거나, 없애거나, 순서를 바꾸거나 등)
2) seq2seq모델이 원래의 텍스트를 복원하기 위해 학습된다.
BART 의 장점
- noising의 유연성 : 어떤 임의의 변형이라도 기존 텍스트에 바로 적용될 수 있으며, 심지어 길이도 변화시킬 수 있다.
저자는 여러 noising 방법론을 실험하였고, 최고의 성능을 보이는 것은 바로 기존 문장의 순서를 랜덤하게 섞고 임의의 길이의 텍스트를 하나의 단일 마스크 토큰으로 교체하는 것이라는 것을 발견하였다. - BART는 텍스트 생성에 fine-tuning하였을 때 특히 효율적이지만, comprehension(이해) 태스크에서도 역시 잘 동작한다.
BART의 fine-tuning 방법
- BART 모델에 몇개의 추가적인 transformer 레이어를 쌓아 올리는 것으로 기계 번역에 대한 새로운 방법론을 제시했다.
- 추가적인 레이어는 외국어를 noise가 적용된 영어로 번역하는 것을 학습한다.
BERT : Bidirectional Encoder Representation from Transformer
- 한번의 프리트레인으로 4개의 파인튜닝이 가능하다
- 문장 2개 관계 판단 (Sequence pair classification)
- 문장분류 (Single Sentence Classification)
- 질의응답 (Question Answering)
- 개체 분석 (Single Sentence Tagging)
더 알아볼것
어텐션 매커니즘
트랜스포머
트랜스 포머는 자기자신을 자기 자신과 비교해서 문장 내에서 각 단어가 다른 단어와 어떤 연관관계가 있는지 학습하는 것.
-> self attention
-> 문장내 단어들의 관계 특성?을 알 수 있다.
트랜스포머는 self attention 을 여러번 해서 배열을 만든다.
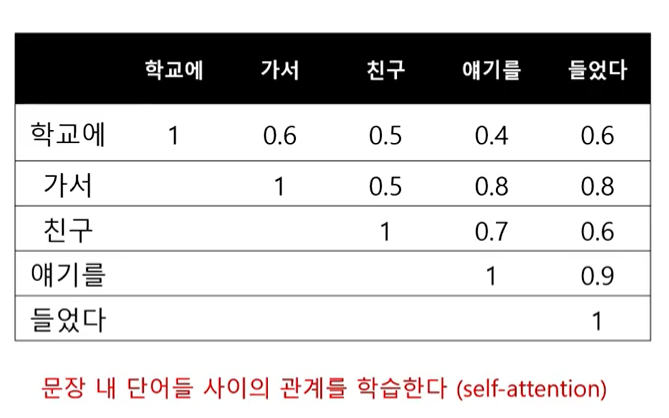
참고
Transformer / Bert /GPT2 / BART의 차이
[논문리뷰] BART
자연어처리 3차 강의

BERT + GPT가 BART는 아니에요. BART는 아키텍쳐상으로는 Transformer와 완전 동일합니다.
예컨대 BERT에 있는 segment embedding이나 추가 linear layer는 없고, GPT에 없는 cross-attention이 있습니다. 즉 Transformer == BART != BERT + GPT
Transformer와 BART의 차이점은 BART는 denoising autoencoder 방식으로 '사전 학습'을 하여 언어 이해도를 확보해놓고, 나중에 약간의 fine-tuning만으로 task 별 작업을 수행할 수 있다는 것입니다.
BART 논문 제목을 보시면 BART를 'pre-training' 으로 정의했습니다.
(BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension)