Q.정확도로 제대로 된 모델의 성능을 측정을 하기 어려운 사례는 어떤게 있을까?
클래스가 불균형한 데이터일 때, 제대로된 평가를 내리기 어렵습니다. 희귀병의 검사 결과 등
불량품검출
스팸메일 분류
금융 => 은행 대출 사기, 신용카드 사기, 상장폐지종목 여부
제조업 => 양불(양품, 불량품) 여부
헬스케어 => 희귀질병(암 진단여부)
IT관련 => 게임 어뷰저, 광고 어뷰저, 그외 어뷰저
대회에서 어뷰저 관련 내용을 찾을 때는 Fraud 등으로 검색하면 여러 사례를 찾을 수 있다.
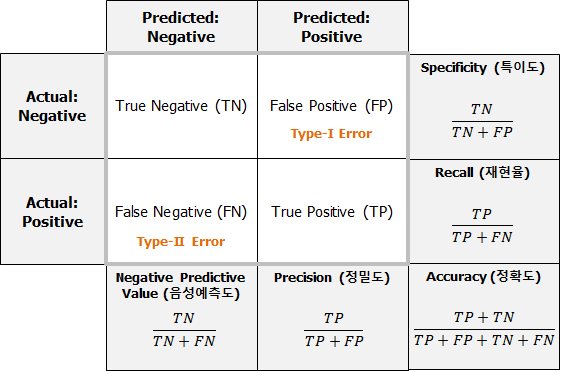
Q. 1종 오류의 사례 무엇이 있을까요?
중고차 성능 판별, 스팸메일, 유무죄 선고
(아닌데 맞다고 하는 경우)
Q. 1종 오류를 볼 때 어떤 측정 지표를 사용해야 할까요?
Precision
Q. 2종 오류의 사례는 무엇이 있고 어떤 측정 지표를 사용해야 할까요?
임신인데 아니라고 해서 술을먹었다거나.
암인데 암이 아니라고 예측
화재인데 화재가 아니라고 예측
지진이 났는데도 지진이 아니라고 예측해서 대피방송을 안한다거나.
(맞는데 아니라 한 경우)측정지표 : Recall
ROC 와 AUC
둘다 1에 가까울 수록 좋은 점수이다.
Threshold
기존에는 예측을 할 때 주로 predict 를 사용했지만 predict_proba 를 하게 되면 0,1 등의 클래스 값이 아닌 확률값으로 반환한다.
임계값을 직접 정해서 True, False를 결정하게 되는데 보통 0.5 로 하기도 하고 0.3, 0.7 등으로 정하기도 한다.
임계값 == Threshold
실습 : Credit Card Fraud Detection
colab 에서 실습 진행.
google 드라이브에 데이터 파일을 올리고, 이를 마운트 해서 사용. (용량이 커서)
- predict_proba
- Predict class probabilities of the input samples X.
- 입력 표본 X의 클래스 확률을 예측한다.
# predict_proba 는 확률 값을 예측한다.
# 각 클래스마다의 확률을 예측한다.
# 0, 1 일때 각각의 확률을 의미한다.
# [0.5, 0.5], [0.3, 0.7] 이렇게 나오기도 한다.
y_pred_proba = model.predict_proba(X_test)
y_pred_proba[:5]
>>> 결과
array([[1., 0.],
[1., 0.],
[1., 0.],
[1., 0.],
[1., 0.]])확률값으로 반환 됐을때는 아래처럼 결과를 추출해볼 수 있다.
# np.argmax 값이 가장 큰 인덱스를 반환한다.
import numpy as np
y_pred_proba_class = np.argmax(y_pred_proba, axis=1)
y_pred_proba_class
>>> array([0, 0, 0, ..., 0, 0, 0])
accuracy_score(y_test, y_pred)
>>> 0.9991397773954567
f1_score(y_test, y_pred)
>>> 0.7487179487179487
precision_score(y_test, y_pred), recall_score(y_test, y_pred)
>>> (0.7525773195876289, 0.7448979591836735)Q. 신용카드 사기에서 사용하는 측정 지표는?
A. recall
precision vs recall
게임에서도 어뷰저가 아닌데 어뷰저로 처리 하는 경우가 있다.
-> 어뷰저라니 기분나빠 게임접자 vs 어뷰저 아니니까 풀어주세요.
-> 어뷰저를 찾지 못한경우가 더 큰 문제 상황일 수 있다.
-> 이런 지표는 어떤게 맞고 틀린가보다, 어떤 평가를 해야지 유리한지 판단이 필요하다.
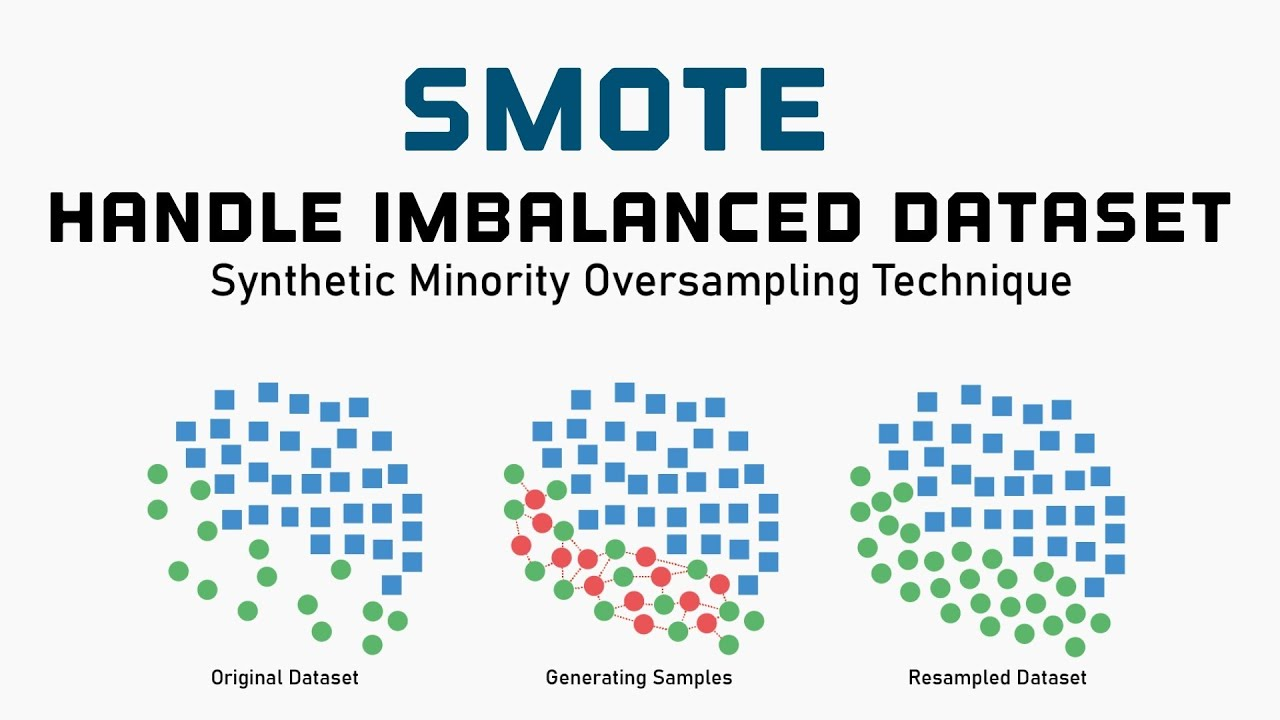
SMOTE
Resampling
현실속 데이터는 불균형한 데이터가 더 많다.
지진이 일어나는 날 vs 안일어나는 날
눈이 오는 날 vs 눈이 오지 않는 날
이런 불균형한 데이터 문제를 해결하기 위해서 전체 데이터에서 특정 방식으로 샘플링 할 수 있다.
이런 샘플링의 목적은, 데이터의 균형을 좀 맞춰주는 것이다.
-
under-sampling : 더 값이 많은 쪽에서 일부만 샘플링하여 비율을 맞춰주는 방법
y.value_counts() >>> 0 284315 1 492 Name: Class, dtype: int64 # 0 에서 랜덤하게 492개 추출 df_0 = df[df["Class"] == 0].sample(492) df_1 = df[df["Class"] == 1] df_0.shape, df_1.shape >>> ((492, 31), (492, 31)) # 하나의 df 로 합쳐주기 df_under = pd.concat([df_0, df_1]) df_under["Class"].value_counts() >>> 0 492 1 492 Name: Class, dtype: int64 -
over-sampling : 더 값이 적은 쪽에서 값을 늘려 비율을 맞춰준 방법
- SMOTE(Synthetic Minority Over-sampling Technique) 방식은 K-근접 이웃을 이용한 over sampling 기법이다.
- K 근접 이웃 알고리즘을 이용해서 데이터를 채워주게 된다. (데이터 뻥튀기!!)
from imblearn.over_sampling import SMOTE
sm = SMOTE(random_state=42)
X_resample, y_resample = sm.fit_resample(X, y)
X.shape, X_resample.shape
>>> ((284807, 30), (568630, 30))
y.shape, y_resample.shape
>>> ((284807,), (568630,))
y.value_counts()
>>>
0 284315
1 492
Name: Class, dtype: int64
y_resample.value_counts()
0 284315
1 284315
Name: Class, dtype: int64- DecisionTree 로 예측해보기
model = DecisionTreeClassifier(random_state=42)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
y_pred[:5]
>>> array([1, 1, 0, 0, 1])
pd.Series(y_pred).value_counts()
>>>
1 56919
0 56807
dtype: int64
accuracy_score(y_test, y_pred)
>>> 0.99847000685859
f1_score(y_test, y_pred)
>>> 0.9984707598741454
# precision - 1종 오류
# recall - 2종 오류
precision_score(y_test, y_pred), recall_score(y_test, y_pred)
>>> (0.9979795850243328, 0.9989624184443311)- SMOTE 학습을 하기 전보다 점수들이 높아진 걸 알 수 있다.
데이터가 불균형하면 학습을 제대로 하기 어렵기 때문에 오버샘플링이나 언더샘플링으로 정답 데이터를 비슷하게 만들어주면 좀 더 나은 성능을 낸다.
