지금은 처음이라 생소하지만, 앞으로 보다보면 익숙해지겠지!
라고 생각해보자.
누구에게나 처음은 어렵다.
딥러닝은 데이터 전처리 과정을 포함한다.
즉, 딥러닝은 비정형 데이터로도 학습이 가능하다.
층을 깊게 쌓을 수 있기 때문에 Deep Neural Network 라 부릅니다.
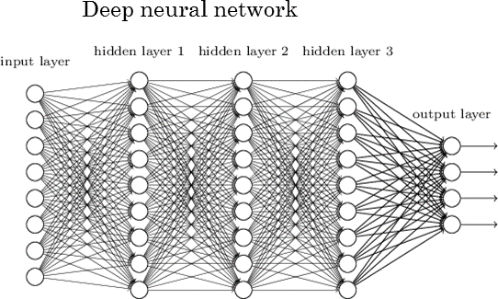
Q. Fully Connected Network 에는 1차원형태로 네트워크에 데이터를 주입해야 하는데 어떻게 비정형 데이터를 잘 다룰까?
=> 전처리 레이어에서 이미지, 음성, 텍스트 등을 전처리 하는 기능을 따로 제공한다.
Q. 28x28 이미지를 입력받을 때 784로 입력 받는 이유는?
A. 1차원으로 받기위해서. (28x28 = 784)
Fully Connected Network 에는 1차원형태로만 주입이 가능하기 때문 네트워크에 데이터를 주입하기 위해서
CNN, RNN 에서는 데이터 전처리를 어떻게 해줄지를 전처리 기능을 제공하고 마지막에는 Fully Connected Network 를 통과하게 된다.
x : input 데이터
w : weight, 가중치
b : bias, 편향
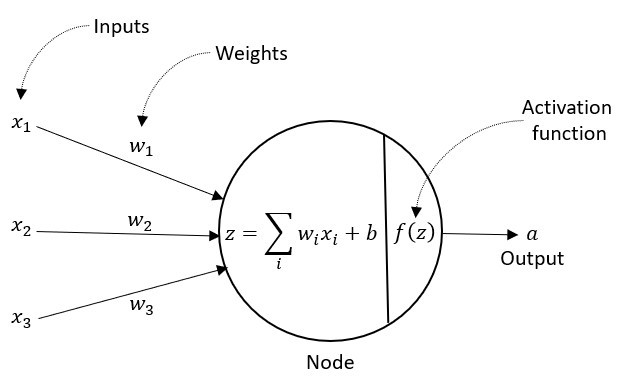
output = activation(dot(input, kernel) + bias)
출력 = 활성화함수(행렬곱(input, kernel) + 편향)
Q. 활성함수 시그모이드의 단점은?
A. 역전파 할 때, 기울기소실문제가 발생+ sigmoid[0, 1]와 비슷하게 tanh[-1, 1] 로 범위가 좀더 넓습니다. 기울기 소실문제는 있지만 좀더 빠르다.
Q. dropout 은 무엇일까?
A. 일부 노드를 제거하고 사용하는 것
Q. 그럼 왜 dropout을 사용할까?
A. 학습속도와는 별 상관없이 과대적합을 방지하기 위해 일부 노드를 제거하고 사용하는 것이다.
텐서플로 2.0 시작하기
# ndim : 차원의 수
x_train.ndim, x_test.ndim
>>> (3, 3)
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
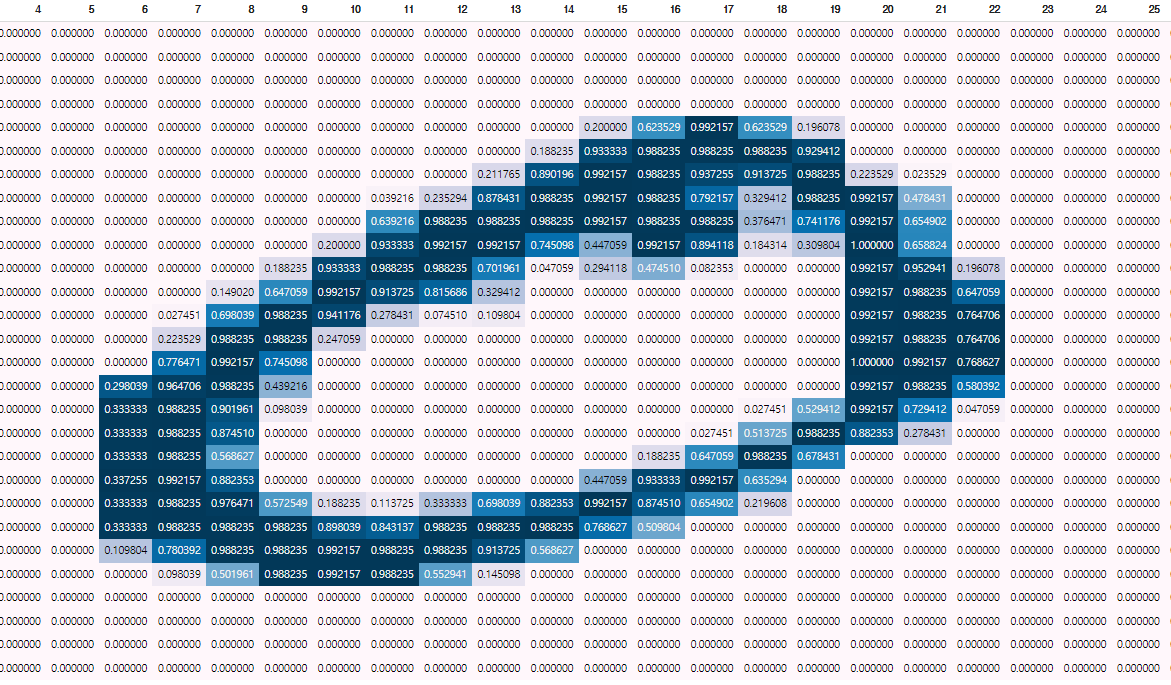
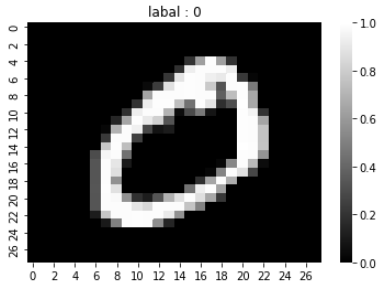
### 1번 index 에 들어있는 이미지 확인하기
idx = 1
display(pd.DataFrame(x_train[idx]).style.background_gradient())
sns.heatmap(x_train[idx], cmap="gray")
plt.title(f"labal : {y_train[idx]}")
- 모델 빌드하기
model = tf.keras.models.Sequential([ # 순차적으로 층을 차례대로 쌓아서 사용한다.
tf.keras.layers.Flatten(input_shape=(28, 28)), # 알아서 1차원 형태로 바꿔준다. 여기가 입력층!
tf.keras.layers.Dense(128, activation='relu'), # 128 은 unit 개수이다. node 수. 활성함수는 relu
tf.keras.layers.Dropout(0.2), # 20% 는 제외하고 쓰겠다.
tf.keras.layers.Dense(10, activation='softmax') # 출력이 10개이다.
])
model.compile(optimizer='adam', # 오차가 최소가 되는 지점을 찾는 방법
loss='sparse_categorical_crossentropy',
metrics=['accuracy']) # 평가지표- 예측
predictions = model(x_train[:1]).numpy()
predictions, np.argmax(predictions)
>>>
(array([[0.15902019, 0.09774707, 0.11245464, 0.09800518, 0.16755828,
0.05885176, 0.06000367, 0.08476438, 0.10475035, 0.05684449]],
dtype=float32), 4)
>>> 정답은 4
pd.Series(predictions[0]).plot.barh().set_title("predictions")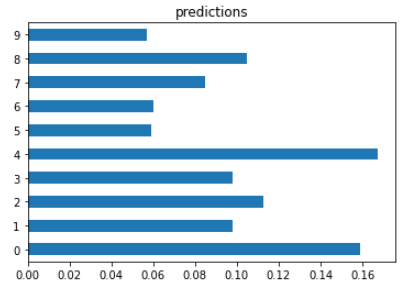
- softmax 함수는 이러한 로짓을 각 클래스에 대한 확률로 변환한다.
smax = tf.nn.softmax(predictions).numpy()
smax, np.sum(smax), f"정답클래스 : {np.argmax(smax)}"
>>>
(array([[0.10600692, 0.09970654, 0.10118382, 0.09973227, 0.10691589,
0.09590288, 0.09601341, 0.09842045, 0.10040726, 0.09571057]],
dtype=float32), 0.99999994, '정답클래스 : 4')
pd.Series(smax[0]).plot.barh().set_title("softmax")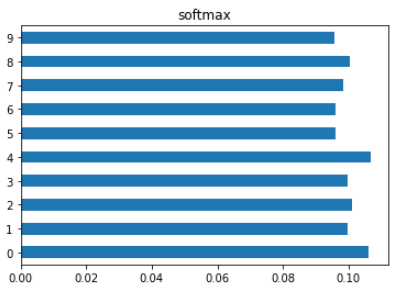
- loss 함수 재정의 하기
loss_fn = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
loss_fn(y_train[:1], predictions).numpy()
>>> 2.3444192
# 훈련되지 않은 모델은 무작위에 가까운 확률(각 클래스에 대해 1/10)을 제공하기 때문에
# -tf.math.log(1/10) ~= 2.3에 근접 한다.
# 모델 생성
model.compile(optimizer='adam',
loss=loss_fn,
metrics=['accuracy'])
# 모델 훈련
model.fit(x_train, y_train, epochs=5)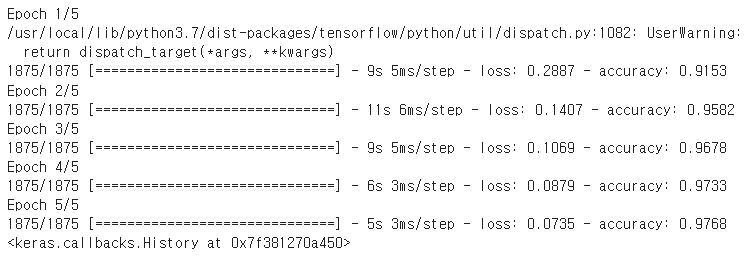
- 모델 훈련및 평가
# 훈련
model.fit(x_train, y_train, epochs=5)
# 평가
model.evaluate(x_test, y_test, verbose=2)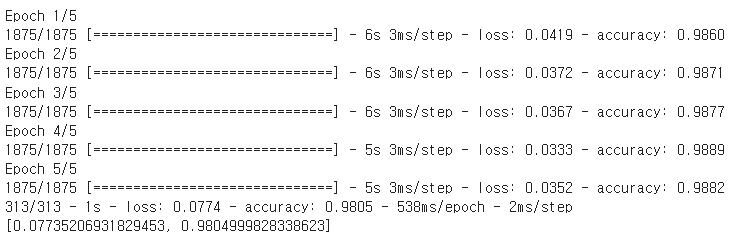
- 98%의 정확도를 보이는걸 확인 할 수 있다.
# 5개만 예측해보자
model_pred = model(x_test[:5])
model_pred[0]
>>>
<tf.Tensor: shape=(10,), dtype=float32, numpy=
array([5.1271959e-13, 5.7649506e-12, 4.2884991e-11, 2.6043745e-06,
2.6056556e-14, 3.2930457e-11, 1.5542682e-21, 9.9999452e-01,
7.9000773e-10, 2.8134286e-06], dtype=float32)>
# 정답보기!
print(np.argmax(model_pred[2]))
sns.heatmap(x_test[2], cmap="gray")
기본분류 실습
Q. 옵티마이저를 사용하는 이유?
A. 옵티마이저는 모델이 인식하는 데이터와 해당 손실 함수를 기반으로 모델이 업데이트되는 방식이다. 즉, 손실함수의 최솟값을 찾기 위해 사용한다.
옵티마이저는 경사하강법 외 여러가지를 지정할 수도 있지만 adam에 비해 대부분 속도가 느린 편이다. 대체적으로 adam 을 사용하면 속도도 빠르고 학습도 잘 하는 편이다.
- Summary
1) 다른 데이터에 적용한다면 층 구성을 어떻게 할것인가? 입력-은닉-출력층으로 구성된다.
2) 예측하고자 하는 값이 분류(이진, 멀티클래스), 회귀인지에 따라 출력층 구성, loss 설정이 달라진다.
(예제를 몇 개 연습해 보면서 익히는 것을 추천)
3) 분류, 회귀에 따라 측정 지표 정하기
4) 활성화함수는 relu 를 사용, optimizer 로는 adam 을 사용하면 baseline 정도의 스코어가 나온다.
5) fit 을 할 때 epoch 를 통해 여러 번 학습을 진행하는데 이 때, epoch 수가 많을 수록 대체적으로 좋은 성능을 내지만 과대적합(오버피팅)이 될 수도 있다.
6) epoch 수가 너무 적다면 과소적합(언더피팅)이 될 수도 있다.
정형데이터로 딥러닝 실습
901
# 공식 문서의 멀티클래스 분류 층 구성
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])- 소프트맥스 일 때 : N개의 노드의 소프트맥스(softmax) 층이다. 이 층은 N개의 확률을 반환하고 반환된 값의 전체 합은 1이다.
각 노드는 현재 이미지가 N개 클래스 중 하나에 속할 확률을 출력한다. - 시그모이드 일 때 : 둘 중 하나를 예측할 때 1개의 출력값을 출력한다. 확률을 받아 임계값 기준으로 True, False로 나눈다.
출력층 : - 예측 값이 n개 일 때 : tf.keras.layers.Dense(n, activation='softmax')
- 예측 값이 둘 중 하나일 때 : tf.keras.layers.Dense(1, activation='sigmoid')
