복습하기!
- Kmooc 강의중 2강(파이프라인), 4강, 8강, 10강, 11강 듣기
실습으로 배우는 머신러닝- Benz 필사해보기
803 실습
- 배깅 => 오버피팅
- 부스팅 => 개별 트리의 성능이 중요할 때
사용한다.
그래디언트 부스팅 트리
- 랜덤 포레스트와 다르게 무작위성이 없다.
- 매개변수를 잘 조정해야 하고 훈련 시간이 길다.
- 데이터의 스케일에 구애받지 않는다.
- 고차원의 희소한 데이터에 잘 작동하지 않는다.
부스팅 3대장 : xgboost, lightgbm, catboost
xgboost : 메모리 효율을 고민했다. (병렬 처리)
lightgbm : 비대칭적인 트리 구조 생성하여 예측 오류 손실을 최소화
catboost : 대칭트리, Ordered Boosting
- n_estimator => boosting 모델에서는 트리가 순차적으로 생성되기 때문에 학습횟수를 의미한다.
# 설치하기
conda install -c conda-forge xgboost
conda install -c conda-forge lightgbm
conda install - Python package installation CatBoostxgboost
gboost는 GBT에서 병렬 학습을 지원하여 학습 속도가 빨라진 모델
- boosting 모델은 시각화가 가능하다. (배깅은 서드파티 시각화 도구를 사용해야 했다.)
xgb.plot_tree(model_xgb, num_trees=1)
fig = plt.gcf()
fig.set_size_inches(30, 20)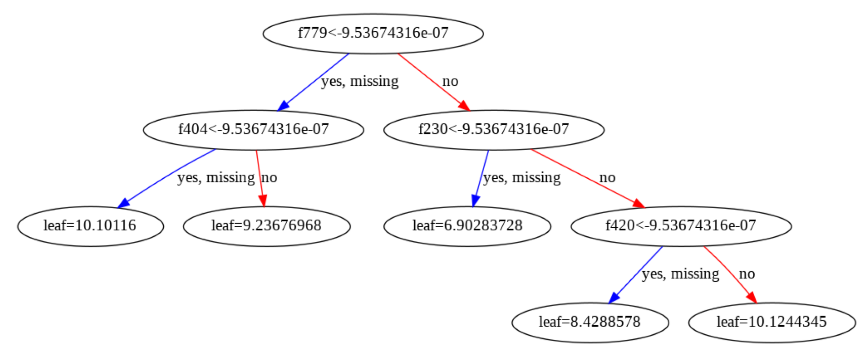
배깅 모델은 시각화가 어려워 3rd party 도구를 따로 설치해야 시각화 가능하다. 그것도 개별 트리를 시각화 하는 것은 어렵다. 그런데 부스팅 모델은 왜 시각화가 가능할까?
-> 배깅은 병렬적으로 여러개의 트리를 만들고, 부스팅은 순차적으로 하나의 트리를 만드는 것이라서 그렇다.
# default parameter
max_depth: int = 3,
learning_rate: float = 0.1,
n_estimators: int = 100,
verbosity: int = 1,
silent: Any | None = None,
objective: str = "reg:linear",
booster: str = 'gbtree',
n_jobs: int = 1,
nthread: Any | None = None,
gamma: int = 0,
min_child_weight: int = 1,
max_delta_step: int = 0,
subsample: int = 1,
colsample_bytree: int = 1,
colsample_bylevel: int = 1,
colsample_bynode: int = 1,
reg_alpha: int = 0,
reg_lambda: int = 1,
scale_pos_weight: int = 1,
base_score: float = 0.5,
random_state: int = 0,
seed: Any | None = None,
missing: Any | None = None,
importance_type: str = "gain",
** kwargs: Any) -> None
Implementation of the scikit-learn API for XGBoost regression.
** kwargs : dict, optional
Keyword arguments for XGBoost Booster object. Full documentation of parameters can be found here: xgboost parameters github link
lightgbm
XGBoost에 비해 성능은 비슷하지만 학습 시간을 단축시킨 모델
import lightgbm as lgbm
model_lgbm = lgbm.LGBMRegressor(random_state=42, n_jobs=-1)
model_lgbm# default parameter
boosting_type: str = 'gbdt',
num_leaves: int = 31,
max_depth: int = -1,
learning_rate: float = 0.1,
n_estimators: int = 100,
subsample_for_bin: int = 200000,
objective: Any | None = None,
class_weight: Any | None = None,
min_split_gain: float = 0,
min_child_weight: float = 0.001,
min_child_samples: int = 20,
subsample: float = 1,
subsample_freq: int = 0,
colsample_bytree: float = 1,
reg_alpha: float = 0,
reg_lambda: float = 0,
random_state: Any | None = None,
n_jobs: int = -1,
silent: bool = True,
importance_type: str = 'split',
** kwargs: Any) -> None
Construct a gradient boosting model.
lightgbm 시각화
lgbm.plot_tree(model_lgbm, figsize=(20, 20), tree_index=0,
show_info=['split_gain', 'internal_value', 'internal_count', 'leaf_count'])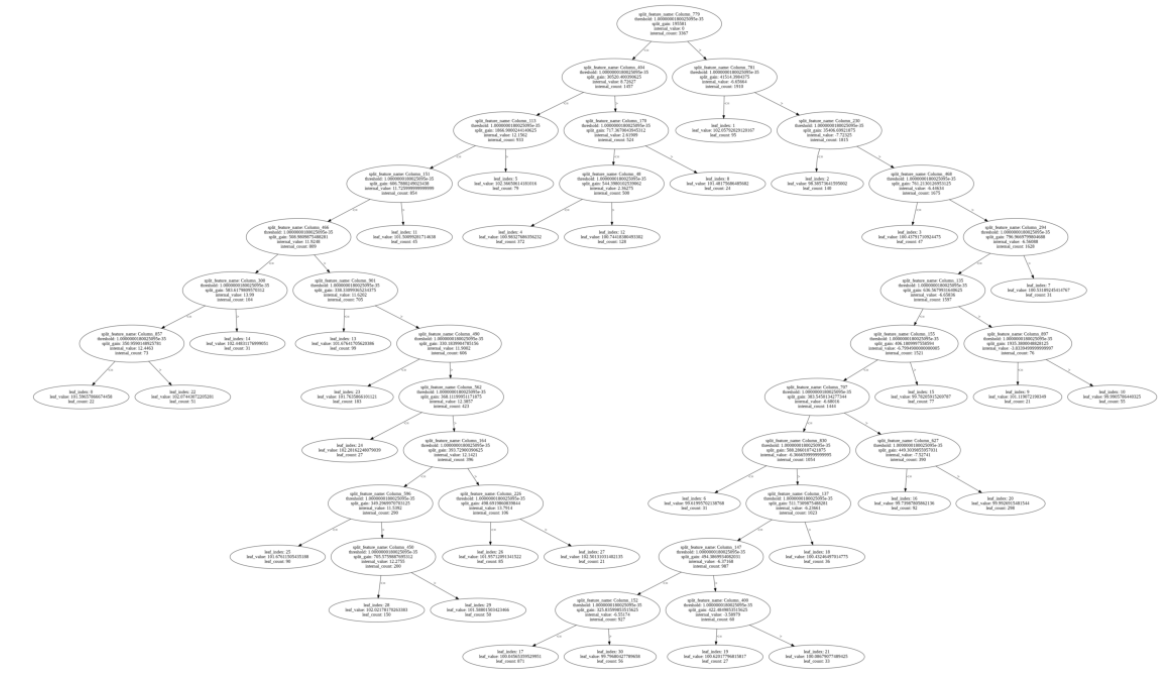
Parameters
booster : Booster or LGBMModel
Booster or LGBMModel instance to be plotted.
ax : matplotlib.axes.Axes or None, optional (default=None)
Target axes instance. If None, new figure and axes will be created.
tree_index : int, optional (default=0)
The index of a target tree to plot.
figsize : tuple of 2 elements or None, optional (default=None) Figure size.
show_info : list of strings or None, optional (default=None) What information should be shown in nodes.
Possible values of list items:
**'split_gain', 'internal_value', 'internal_count', 'leaf_count'.**
precision : int or None, optional (default=None)
Used to restrict the display of floating point values to a certain precision.
**kwargs
Other parameters passed to Digraph constructor.catboost
catboost는 기존 GBT의 느린 학습 속도와 과대적합 문제를 개선한 모델
주요 파라메터
cat_features : 범주형 변수 인덱스 값
loss_function : 손실 함수를 지정
eval_metric : 평가 메트릭
iterations : 머신러닝 중 만들어질 수 있는 트리의 최대 갯수
learning_rate : 부스팅 과정 중 학습률
subsample : 배깅을 위한 서브샘플 비율
max_leaves : 최종 트리의 최대 리프 개수왜 learning_rate가 낮을때 n_estimator 값을 높여야 과적합이 방지될까?
n_estimator 값이 또, 너무 높다면 과적합이 될 수도 있다.
=>
과대적합( == 과적합 == 오버피팅)은 학습하지 말아야 할 것까지 너무 자세히 학습하다 보면 일반화 하기 어렵기 때문에 과대적합이 된다.
learning_rate를 줄인다면 가중치 갱신의 변동폭이 감소해서, 여러 학습기들의 결정 경계(decision boundary) 차이가 줄어들게 된다.
n_estimators 를 늘린다면 생성하는 약한 모델(weak learner)가 늘어나게 되고, 약한 모델이 많아진만큼 결정 경계(decision boundary)가 많아지면서 모델이 복잡해지게 된다.
즉, 부스팅알고리즘에서 n_estimators와 learning_rate는 trade-off 관계이다.
n_estimators(또는 learning_rate)를 늘리고, learning_rate(또는 n_estimators)을 줄인다면 서로 효과가 상쇄된다.
부스팅 모델은 왜 오버피팅에 민감할까?
=> 이전 트리(이전 학습)가 다음 트리(다음 학습)에 영향을 주기 때문이다.
알아볼개념
- learning_rate
- 결정 경계(decision boundary)
- lightgbm 의 histogram
