분류 손실함수
참고
점프 투 파이썬 Loss Functions
손실함수(loss function), Cross Entropy Loss
주로 딥러닝에서 쓰인다.
분류 클래스가 2개인 로지스틱 함수를 클래스가 n개일 때로 확장한 것이 딥러닝에서 주로 사용하는 softmax function다. 이 함수와 데이터의 확률 분포의 차이가 분류 문제의 손실 함수가 된다.
- softmax function
- 최대값의 soft/smooth한 근사치
- 출력은 0~1 사이의 실수이다.
- 출력을 '확률'로 해석할 수 있다.
- 출력의 총합은 1이다.
분류의 손실함수 종류
- cross-entropy (= log loss) : 다중 분류에 사용
- binary entropy : 이진 분류에 사용
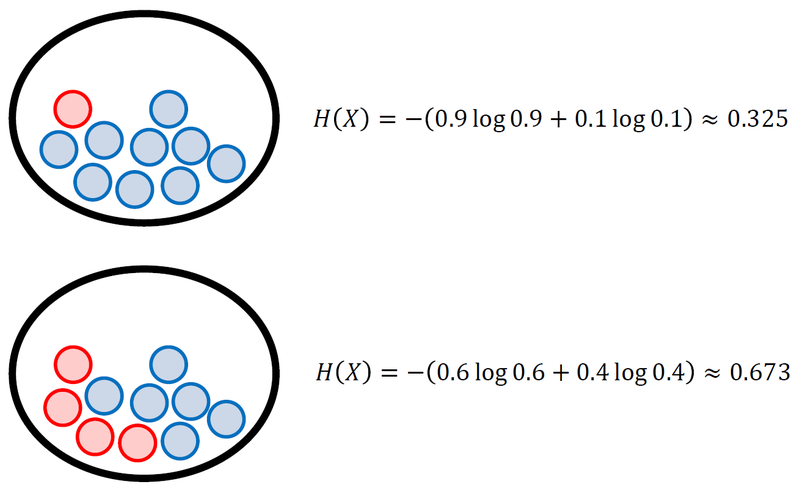
Entropy 란?
- 무질서도
- 열역학 제2법칙이란 항상 전체 계의 엔트로피가 증가하는 방향으로 변화가 일어난다는 법칙
- 엔트로피의 증가량은 항상 0보다 크거나 같다.
- 루트비히 볼츠만의 통계역학적인 정의는 아래와 같다.
Cross-entropy 손실함수
참고
딥러닝에서는 실제 데이터의 확률 분포와, 학습된 모델이 계산한 확률 분포의 차이를 구하는데 사용된다.
원래의 cross entropy는 예측 모형은 실제 분포인 q 를 모르고, 모델링을 하여 q 분포를 예측하고자 하는 것이다. 예측 모델링을 통해 구한 분포를 p(x) 라고 해보자. 실제 분포인 q를 예측하는 p 분포를 만들었을 때, 이 때 cross-entropy 는 아래와 같이 정의된다.
분류 문제에서 데이터의 라벨은 one-hot encoding을 통해 표현된다.
실제 엔트로피 구해보기
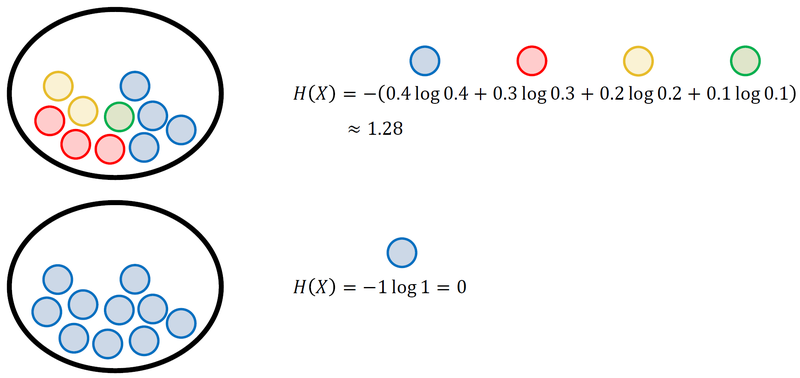
예측값으로 Cross Entropy 를 구한다면
가방에 0.8/0.1/0.1 의 비율로, 빨간/녹색/노랑 공이 들어가 있다고 하고,
예측 결과 0.2/0.2/0.6의 비율로 들어가 있을 것 이라고 예상했다.
이 때, entropy 와 cross-entropy 는 아래와 같이 계산된다.
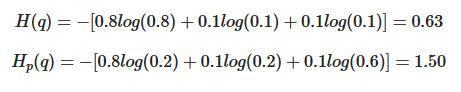
cross-entropy는 실제 entropy 보다 항상 크다.
예측 분포인p 를 실제분포 q에 가깝게 하는 것이, 예측모형이 하고자하는 것다.
즉, entropy 는 고정이기 때문에, cross-entropy 를 최소화 시키는 것이 예측 모형을 최적화 시키는 것이라고 할 수 있다. 이것이 불확실성을 제어하고자하는 예측모형의 실질적인 목적이라고 볼 수 있다.
Sklearn 에서 Cross Entropy
- Pima 인디언 데이터셋으로 확인해보기 with
log_loss
depth 지정 안해서 entropy가 최소가 되도록 했을 때.
# Decision Tree 모델 학습
model = DecisionTreeClassifier(criterion="entropy")
# Train Decision Tree Classifier
model = model.fit(X_train, y_train)
# Predict the response for test dataset
y_pred = model.predict(X_test)
print("Accuracy : ", metrics.accuracy_score(y_test, y_pred))
>>> Accuracy : 0.7662337662337663
from sklearn.tree import plot_tree
plt.figure(figsize=(20,20))
ptree = plot_tree(model,
feature_names = feature_cols, filled=True, fontsize=14, )
plt.show()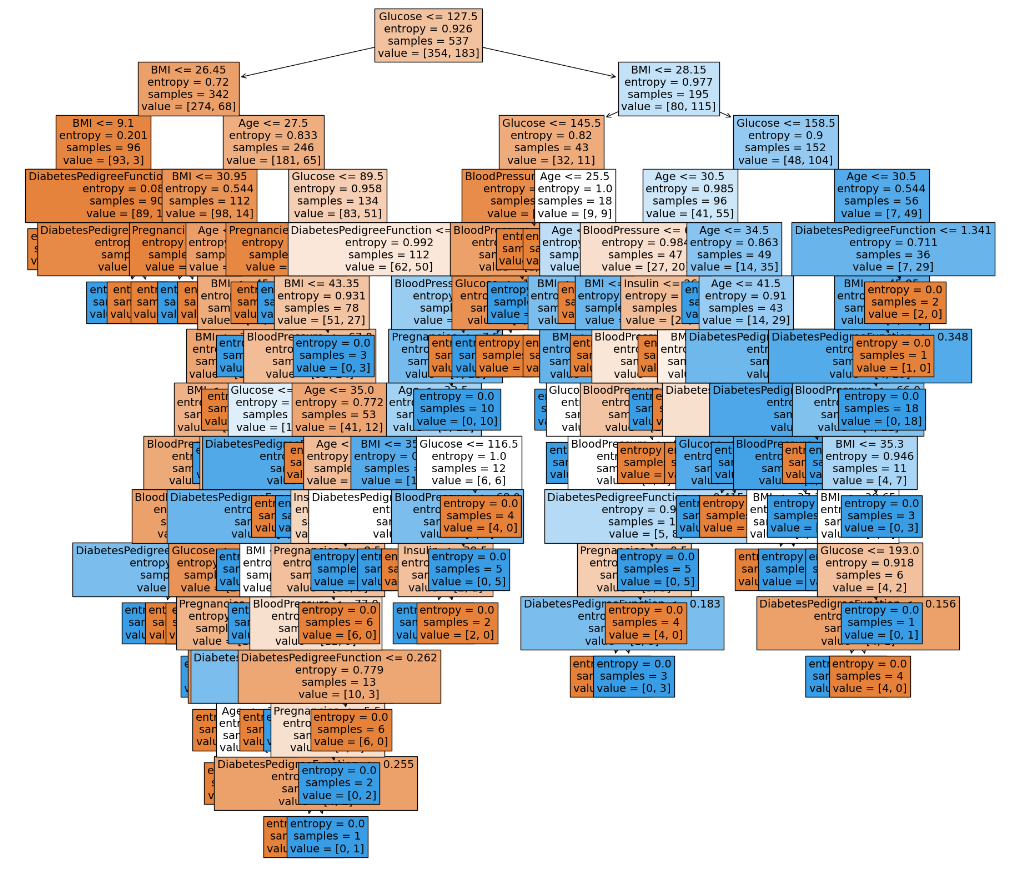
from sklearn.metrics import log_loss
log_loss(y_test, y_pred)
>>> 8.522655596689978depth 지정해서 entropy가 최소가 되지 않고 중간에서 끊기는 경우
clf = DecisionTreeClassifier(criterion = 'entropy', max_depth = 4)
# Train Decision Tree Classifier
clf = clf.fit(X_train, y_train)
# Predict the response for test dataset
y_pred = clf.predict(X_test)
# Model Accuracy, how often is the classifier correct?
print('Accuracy : ', metrics.accuracy_score(y_test, y_pred))
>>> Accuracy : 0.7835497835497836
from sklearn.tree import plot_tree
plt.figure(figsize=(24,20))
ptree = plot_tree(clf,
feature_names = feature_cols, filled=True, fontsize=10, )
plt.show()
from sklearn.metrics import log_loss
log_loss(y_test, y_pred)
>>> 7.475981009975832오히려 최종 cross entropy 는 depth 를 지정해준 쪽이 더 낮다!
