- data set : Pima Indians Dataset 이용
- 인슐린 수치 결측치(0) 채우는 전처리만 진행
이전실습 에서 전처리 코드 확인 가능
GBM
import time # 시간측정을 위해 import
from sklearn.ensemble import GradientBoostingClassifier
# 모델생성
gbm = GradientBoostingClassifier(random_state=42)
start_gbm = time.time() # 시작시간
gbm.fit(X_train, y_train) # training
gbm_predict = gbm.predict(X_test) # 예측
end_gbm = time.time() # 끝낸시간
gbm_accuracy =(y_test == gbm_predict).mean() # 예측결과
print(" GradientBoosting 걸린시간 : ", end_gbm - start_gbm , " 예측점수 : ", gbm_accuracy)
>>> GradientBoosting 걸린시간 : 0.2343740463256836 예측점수 : 0.8766233766233766XGBoost
# 먼저 설치를 해야한다.
!pip install xgboost
from xgboost import XGBClassifier
# 모델 생성
model =XGBClassifier(random_state=42)
start_xgb = time.time() # 시작시간
model.fit(X_train, y_train) #training
y_predict = model.predict(X_test) # 예측
end_xgb = time.time() # 끝낸시간
xgb_accuracy = accuracy_score(y_test, y_predict) # 예측결과
print(" XGB 걸린시간 : ", end_xgb - start_xgb , " 예측점수 : ", xgb_accuracy)
>>> XGB 걸린시간 : 0.18948841094970703 예측점수 : 0.8831168831168831
Simple Voting 분류
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import VotingClassifier
# 사용할 분류기 불러오기
logistic_regression = LogisticRegression(n_jobs=-1)
KNN = KNeighborsClassifier()
# voting_ensemble model
voting_ensemble = VotingClassifier(estimators=[("LogisticRegression", logistic_regression), ("KNN", KNN)],voting = 'soft')
start_voting = time.time() # 시작시간
voting_ensemble.fit(X_train, y_train) # training
y_pred = voting_ensemble.predict(X_test) # 예측
end_voting = time.time() # 끝낸시간
# 정확도 계산
voting_accuracy = accuracy_score(y_test, y_pred)
print(" voting 분류기 걸린시간 : ", end_voting - start_voting , " 예측점수 : ", voting_accuracy)
>>> voting 분류기 걸린시간 : 1.1217186450958252 예측점수 : 0.8506493506493507Simple Voting 회귀
- 회귀는 수치형 데이터를 예측하는 것이므로 전처리와 label_name 을 바꿔줘야 한다.
- 전처리
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
# 데이터셋
df = pd.read_csv("http://bit.ly/data-diabetes-csv")
# labe & feature
label_name = "Insulin"
feature_names = df.columns.tolist()
feature_names.remove(label_name)
# 0인 값 제외
train = df[df[label_name] > 0]
X = train[feature_names]
y = train[label_name]
# 데이터셋 나누기
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42, test_size=0.2)
random forest
from sklearn.ensemble import RandomForestRegressor
random_model = RandomForestRegressor(random_state=42, n_jobs=-1)
random_model.fit(X_train, y_train) # training
raindom_predict = random_model.predict(X_test) # 예측
r2_score(y_test, raindom_predict)
>>> 0.33342888801809334
sns.regplot(x=y_test, y=raindom_predict, color="Green", scatter_kws={"s": 10},)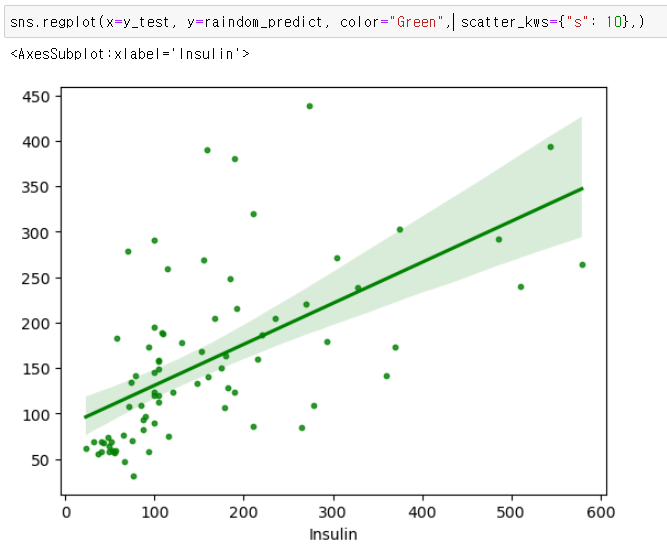

열심히 사는 중