Dense 가 1인 경우 회귀 모델이라는 것을 모델이 어떻게 알 수 있을까?
A. loss 함수로 알 수 있다.
분류에서 units이 2개라면 softmax 로 반환받는게 맞다. 이 때는 둘 중에 확률 값이 높은 값을 선택해서 사용한다. 멀티클래스 예측값이 나왔을 때 가장 큰 인덱스를 반환하는 넘파이 메서드는 무엇일까?
A. np.argmax() 를 통해 가장 큰 값의 인덱스를 반환받아 해당 클래스의 답으로 사용한다.
softmax 와 sigmoid 의 차이는 무엇일까?
A. softmax 는 n개의 확률값을 반환하고 전체의 합은 1이 된다. 2개 중에 하나를 예측할 때는 softmax 를 사용할 수도 있기는 하지만 보통 sigmoid 를 사용한다. sigmoid는 이진분류에 사용되며, 0과 1 사이의 확률 값을 반환하여 임계값을 기준으로 분류한다.
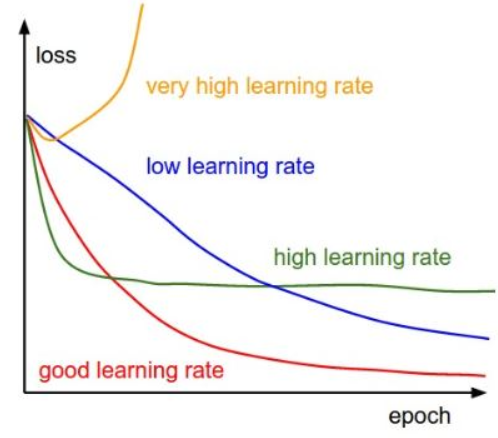
learning rate 는 무엇인가?
A. 학습률을 의미하며 경사하강법에서 한 발자국 이동하기 위한 step size 를 의미한다. 학습률이 클수록 손실함수의 최솟값을 빨리 찾을 수 있으나 발산의 우려가 있고 너무 작으면 학습이 지나치게 오래 걸리는 단점이 있어서 적당하게 설정해주는게 좋다.
learning rate (η)
- Learning Rate라고 하며 한 번 학습할 때 얼마만큼 학습해야 하는지 학습 양을 의미하며 한 번의 학습량으로 학습한 이후에 가중치 매개변수가 갱신한다.
- Mahcine learning에서 training 되는 양 또는 단계를 의미한다.
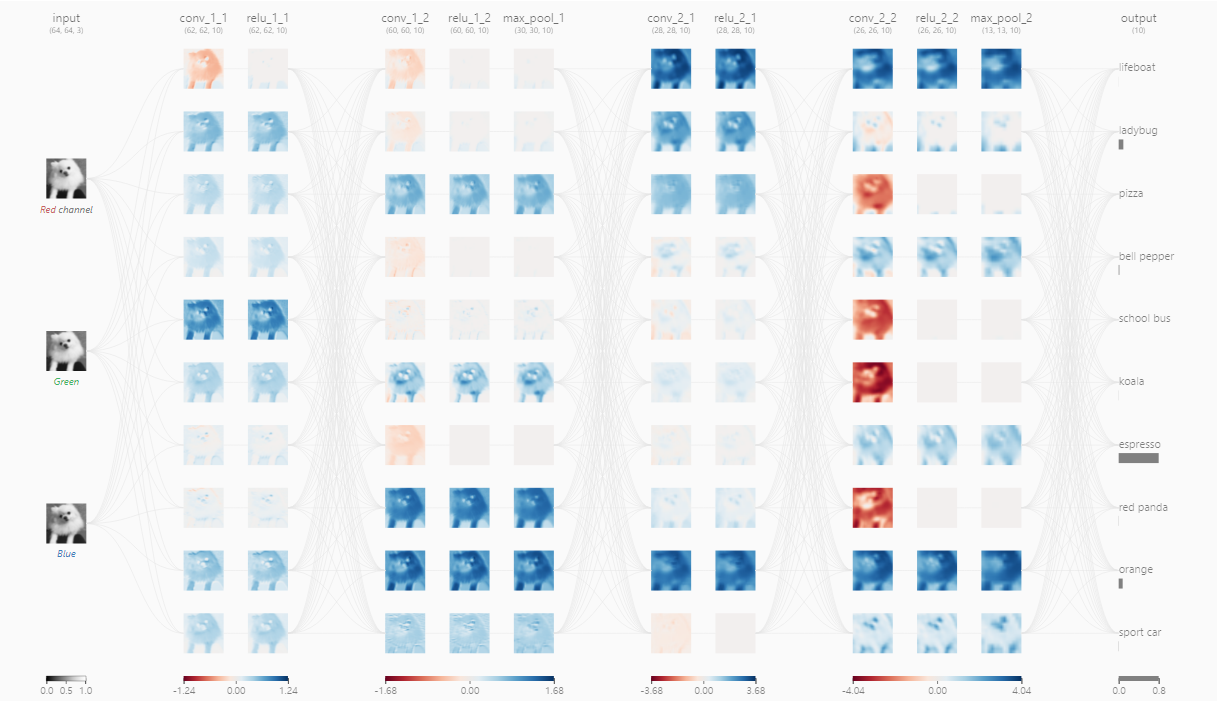
합성곱 신경망 (CNN)
TensorFlow 합성곱 신경망
CNN Explainer

-
오늘의 주요 학습 : 합성곱층 만들기!!
-
mnist 는 흑백이라 컬러채널이 1 이었는데, cifar 데이터는 컬러라서(RGB) 컬러채널이 3이 됐다.
합성곱 신경망의 별명 => 피처 자동 추출기
그러면 어떻게 피처를 자동으로 추출할까?
=> 필터(filters)를 랜덤하게 여러 장 만든다. 각 필터의 사이즈는 kernel_size 로 정한다.
=> 필터를 이미지에 통과시켜서 합성곱 연산을 하여 결과가 나오면 그 결과로 특징을 추출한다.
=> 필터에는 랜덤하게 만들다 보면 1자 모양도 있을 수 있고 / 모양도 있을 수 있고 O, ㅁ 이런 여러 패턴을 랜덤하게 만들 수있다. 그리고 그 패턴을 통과시켜서 그 패턴이 얼마나 있는지 확인해 볼 수 있다. 이런 패턴을 여러 장 만든다
=> filters
=> 각 필터의 사이즈 kernel_size라 부른다.
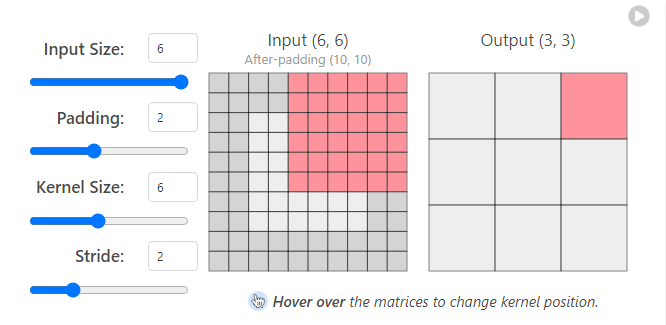
패딩을 어떤 특징이 있을까? 왜 패딩을 사용할까?
A. 이미지가 줄어드는 것을 방지하기 위해 사용하기도 하지만 가장자리 모서리 부분의 특징을 좀 더 학습할 수 있기 때문에 패딩을 사용한다.
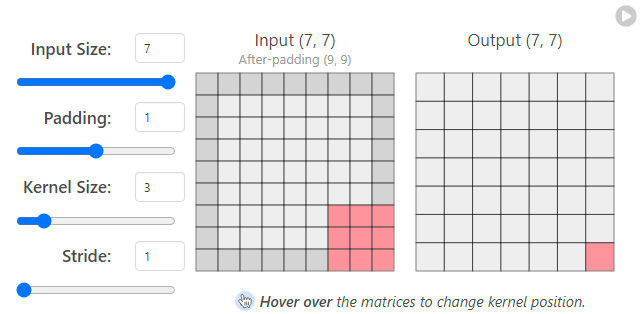
- 패딩을 1로 커널사이즈를 3x3 으로 사용하면 입력과 출력값이 같아지게 되서 많이 사용한다.
Q. 컨볼루션 레이어를 통과한 결과 10개의 피처를 무엇이라고 부를까?
A. 피처맵

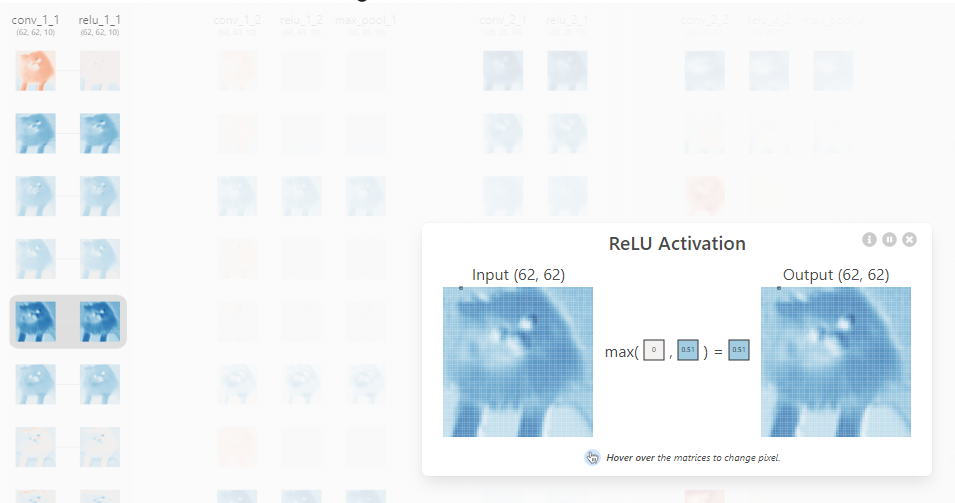
Q. 피처맵이 relu 활성화 함수를 통과한 것을 무엇이라고 부를까?
A. 액티베이션맵
max pooling

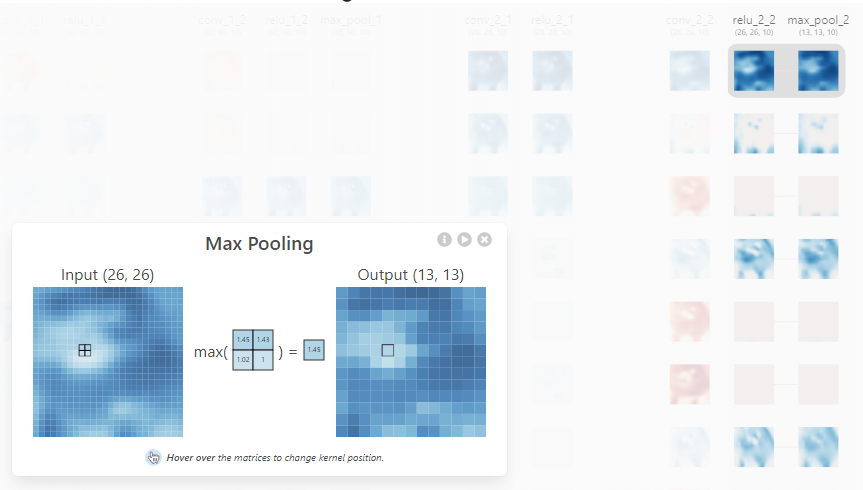
Q. MaxPooling 을 적용하면 어떤 효과가 있을까?
- 너무 자세한 부분까지 학습하게 하지 않는게 목적이다.
- 데이터의 사이즈를 주려주고, 노이즈를 상쇄시킨다.
- 폴링방식 : Max Pooling, Average Pooling, Min Pooling
- 컬러이미지에서는 MaxPooling 을 가장 많이 사용하는 편이고, 흑백이미지에서는 MinPooling 을 사용하기도 한다.
- 이미지를 추상화 해주기 때문에 너무 자세히 학습하지 않도록해서 오버피팅이 방지되기도 한다.
CNN 과정 정리
-
Convolution 연산을 하면 필터(filters, kernel_size에 해당하는 filters 개수만큼)를 통과시켜서 filters 개수만큼 피처맵을 생성한다.
- CNN 의 별명이 피처자동추출기 이기도 하다.
비정형 이미지를 입력했을 때 이미지를 전처리 하지 않고 그대로 넣어주게 되면 알아서 피처맵을 생성한다.
피처맵은 피처가 어떤 특징을 갖고 있는지를 나타낸다.
선이 있는지, ), O, 1, , 다양한 모양을 랜덤하게 생성해서 통과 시키면 해당 특징이 있는지를 학습하게 하는게 Convolution 연산이다.
- CNN 의 별명이 피처자동추출기 이기도 하다.
-
피처맵 Output에 Activation Function (활성화함수)을 통과시켜서 액티베이션맵을 생성한다.
- relu 등을 사용하게 되면 출력값에 활성화 함수를 적용한 액티베이션맵을 반환한다.
-
Pooling 에는 Max, Average, Min 등 여러 방법이 있는데, 보통 MaxPooling 을 주로 사용한다.
-
흑백이미지에서는 MinPooling 을 사용하기도 합니다.
MaxPooling 은 가장 큰 값을 반환,
AveragePooling 은 평균 값 반환,
MinPooling 은 최솟값 반환 -
이미지 크기를 줄여 계산을 효율적으로 한다.
-
이미지를 추상화 해주기 때문에 너무 자세히 학습하지 않도록해서 오버피팅이 방지되게 됩니다.
-
-
CNN 관련 논문을 보면 이 층을 얼마나 깊게 쌓는지에 대한 논문이 있다.
- VGG16, VGG19 등은 층을 16개, 19개 만큼 깊게 만든 것을 의미한다.
- 30~50층까지 쌓기도 하고 100층 정도 쌓기도 한다.
층의 수를 모델의 이름에 붙이기도 합니다. - 과거에 비해 GPU 등의 연산을 더 많이 지원하기 때문에 연산이 빨라진 덕분이기도 하다.
-
TF API 는 다음의 방법으로 사용합니다.
model.add(layers.Conv2D(filters=64, kernel_size=(3, 3), activation='relu'))
model.add(layers.MaxPooling2D(pool_size=(2, 2)))- Padding, Stride 등을 사용해서 입력과 출력사이즈를 조정한다든지, Stride는 필터의 이동 보폭을 조정하기도 한다.
Q. DNN을 이미지 데이터에 사용했을 때 어떤 단점이 있을까?
- flatten() 으로 1차원 벡터 형태로 주입을 해야 하기 때문에 인접 공간에 대한 정보를 잃어버리게 된다.
- 1차원 형태로 주입을 해주게 되면 입력값이 커서 계산이 오래 걸린다.
DNN 의 단점을 보완한 CNN의 특징
- Conv과 Pooling 연산을 하게 되면 데이터의 공간적인 특징을 학습하여 어떤 패턴이 있는지를 알게 된다.
- Pooling 을 통해 데이터를 압축하면 데이터의 용량이 줄어들며, 추상화를 하기 때문에 너무 자세히 학습하지 않게 되서 오버피팅을 방지해 준다.
CNN, DNN의 가장 큰 차이는 바로 1차원으로 flatten 해서 넣어주는게 아니라 Conv, Pooling 연산을 통해 특징을 학습하고 압축한 결과를 flatten 해서 DNN 에 넣어 준다는 것이다.
