해당 튜토리얼은 꽃 5가지 이미지를 학습하고 분류하는 예제다.
['daisy', 'dandelion', 'roses', 'sunflowers', 'tulips'] 5가지 꽃을 분류해 본다.
Q. 이미지 사이즈가 다 다르면 계산을 할 수 없기 때문에 사이즈도 맞춰줄 필요가 있다. 이 때 어떤 사이즈로 만들어주는게 좋을까?
A. 계산편의를 위해 보통 정사각형 형태로 만들어준다.
Q. 이미지 사이즈를 작게 만들면 어떤 결과가 나올까?
A. 원래 이미지가 왜곡이 될 수 있다. 이건 크게 만들어도 마찬가지 문제가 발생하기도 한다. 작은 사이즈를 늘리면 픽셀이 깨져보일 수도 있겠죠. 장점은 사이즈를 작게 하면 계산이 빠릅니다.
Q. 반대로 사이즈를 크게 하면 어떻게 될까
A. 계산시간은 오래 걸리지만 분류모델이라면 정확도가 더 높아진다.
- PIL, OpenCV 등을 내부에서 사용하고 있는데 우리가 포토샵에서 이미지 사이즈 줄이는 것 처럼 이미지 사이즈를 조정해 준다.
num_classes = len(class_names)
model = Sequential([
layers.Rescaling(1./255, input_shape=(img_height, img_width, 3)),
layers.Conv2D(filters=16, kernel_size=3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(filters=32, kernel_size=3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(filters=64, kernel_size=3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Flatten(),
layers.Dense(units=128, activation='relu'),
layers.Dense(num_classes)
])filters : 컨볼루션 필터의 수 == 특징맵 수
kernel_size : 컨볼루션 커널의 (행, 열) => 필터 사이즈
- kernel_size 는 주로 3을 사용한다.
padding : 경계 처리 방법
- ‘valid’ : 유효한 영역만 출력이 된다. 따라서 출력 이미지 사이즈는 입력 사이즈보다 작다.
- ‘same’ : 출력 이미지 사이즈가 입력 이미지 사이즈와 동일
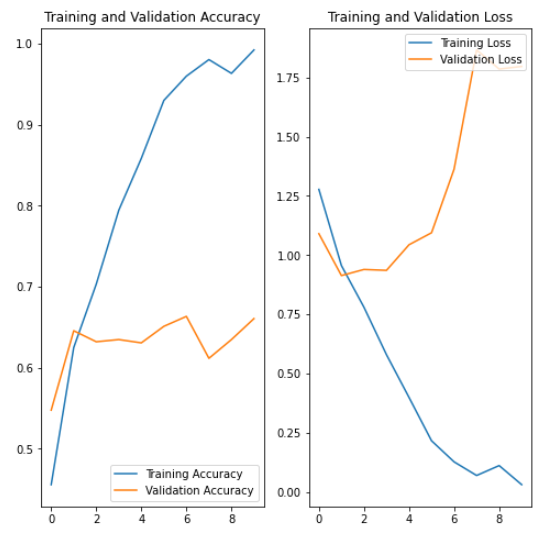
- 결과가 과대적합이 나왔다.
- 이미지 전처리가 되어있지 않기 때문일 가능성이 높다.
- 결국 어떤 데이터를 넣어주는지가 중요하다.

과대적합!
훈련 예제가 적을 때 모델은 훈련 예제의 노이즈나 원치 않는 세부까지 학습한다.
이는 모델이 새 데이터세트에서 일반화하는 데 어려움이 있음을 의미한다.
전처리
- 데이터 증강 : 기존 예제에서 추가 훈련 데이터를 생성
- 이미지 증강 : 믿을 수 있는 이미지를 생성하는 임의 변환을 사용하는 방법으로 기존 예제에서 추가 훈련 데이터를 생성한다.
# 이미지 증강 방법
tf.keras.layers.RandomFlip # 접고
tf.keras.layers.RandomRotation # 돌리고
tf.keras.layers.RandomZoom #땡기고접고 돌리고 땡기고
# 이미지 증강 코드
data_augmentation = keras.Sequential(
[
layers.RandomFlip("horizontal",
input_shape=(img_height,
img_width,
3)),
layers.RandomRotation(0.1),
layers.RandomZoom(0.1),
]
)- 증강 적용한 것 시각화
plt.figure(figsize=(10, 10))
for images, _ in train_ds.take(1):
for i in range(9):
augmented_images = data_augmentation(images)
ax = plt.subplot(3, 3, i + 1)
plt.imshow(augmented_images[0].numpy().astype("uint8"))
plt.axis("off")
model = Sequential([
data_augmentation, # 이미지 증강 적용
layers.Rescaling(1./255),
layers.Conv2D(16, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(32, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(64, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Dropout(0.2), # 과대적합 방지를 위한 dropout
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dense(num_classes, name="outputs")
])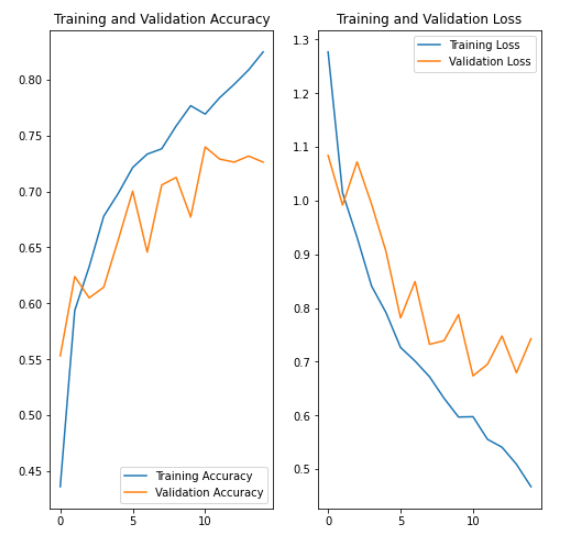
-> 데이터 증강기법을 통해 오버피팅이 줄어든것을 확인해 볼 수 있다.
MNIST(손글씨 이미지로 0~9 숫자), FMNIST(의류 10가지 이미지) 는 전처리가 잘 되어있기 때문에 기본 모델로 만들어도 99% 까지의 Accuracy가 나왔니다.
지금 진행한 꽃 이미지에는 노이즈가 많기 때문에 Accuracy 가 데이터 증강, Dropout을 했을 때 0.6대에서 0.7정도로 정확도가 높아졌다.
이미지 증강을 할 때 주의해야 할 사항이 있다면?
- 노이즈를 확대하거나 크롭하면 문제가 된다.
- 6을 180도 돌리면 완전히 다른 의미인 9가 되기 때문에 이런 숫자 이미지는 돌리지 않는다.
- 색상이 중요한 역할을 하는 이미지일 경우에 색상 반전 혹은 변경을 하면 안된다.
- 신호등, 옐로카드 레드카드
- 증강할 때 train 에만 해준다. test에는 해주지 않는다. 왜냐하면 현실세계 문제를 푼다고 가정했을 때 현실세계 이미지가 들어왔을 때 증강해주지는 않고 들어온 이미지로 판단하기 때문에 train에만 사용한다.
말라리아 실습
말라리아 원충의 진단, 감별진단, 치료와 예방 : 네이버 블로그
이미지를 로드하는 방법에는 여러가지가 있다.
- matplotlib.pyplot imread()를 사용하는 방법
- PIL(Pillow) 로 불러오는 방법
PIL 로 접고돌리고땡기고가 다 가능하다.
TF 내부에서도 PIL 이나 OpenCV를 사용해서 접고돌리고땡기고를 한다.
=> 이미지 편집기를 만들 수도 있다.- OpenCV로 불러오는 방법(Computer Vision)에 주로 사용하는 도구로 동영상처리 등에 주로 사용한다.
이미지 데이터 불러오기
wget 을 사용하면 온라인 URK 에 있는 이미지를 불러올 수 있다.
!wget https://data.lhncbc.nlm.nih.gov/public/Malaria/cell_images.zip이미지 보기
plt.imread vs cv2(OpenCV) 의 imread
로 시각화 한 이미지 비교
# (M, N, 3) for RGB images.
my_image = plt.imread("bom.jpg")
plt.imshow(my_image)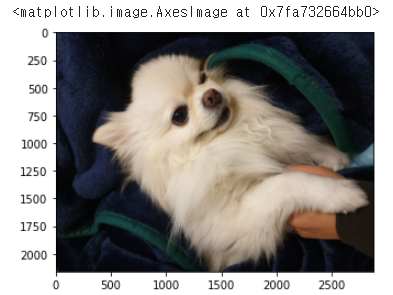
import cv2
bom = cv2.imread("bom.jpg")
plt.imshow(bom)
# In the case of color images, the decoded images will have the channels stored in **B G R** order.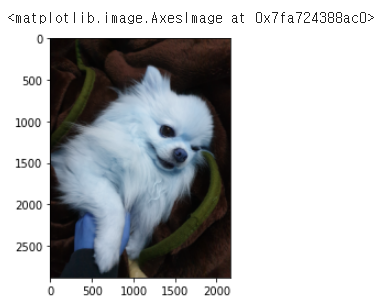
ImageDataGenerator
tensorflow.keras 의 이미지 전처리 기능
# 예시
# ImageDataGenerator 를 통해 이미지를 로드하고 전처리 합니다.
from tensorflow.keras.preprocessing.image import ImageDataGenerator
# validation_split 값을 통해 학습:검증 비율을 8:2 로 나눕니다.
datagen = ImageDataGenerator(rescale=1/255.0, validation_split=0.2)ImageDataGenerator는 다음과 같은 이미지 변환 유형을 지원한다.
-
공간 레벨 변형
- Flip : 상하, 좌우 반전
- Rotation : 회전
- Shift : 이동
- Zoom : 확대, 축소
- Shear : 눕히기
-
픽셀 레벨 변형
- Bright : 밝기 조정
- Channel Shift : RGB 값 변경
- ZCA Whitening : Whitening 효과
이미지 사이즈는 어떻게 해야할까?
원본 이미지는 100~200 내외인 상황이다.
이미지가 너무 작으면 왜곡이 되거나 특징을 잃어버릴 수도 있다. 하지만 계산량이 줄어들어 학습 속도가 빠르다.
이미지가 크면 흐려지거나 왜곡이 될 수도 있지만 좀더 자세히 학습한다. 단 계산량이 많아서 학습속도가 오래 걸린다.
-> 학습이 너무 오래 걸리지 않도록 32 정도로 설정하자
이미지 불러오기
flow_from_directory를 통해 이미지를 불러온다.
trainDatagen = datagen.flow_from_directory(directory = 'cell_images/',
target_size = (height, width),
class_mode = 'binary',
batch_size = 64,
subset='training')
# class_mode: One of "categorical", "binary", "sparse","input", or None. Default: "categorical".
# subset: Subset of data ("training" or "validation")
def flow_from_directory(directory,
target_size=(256, 256),
color_mode='rgb',
classes=None,
class_mode='categorical',
batch_size=32,
shuffle=True,
seed=None,
save_to_dir=None,
save_prefix='',
save_format='png',
follow_links=False,
subset=None,
interpolation='nearest', keep_aspect_ratio=False)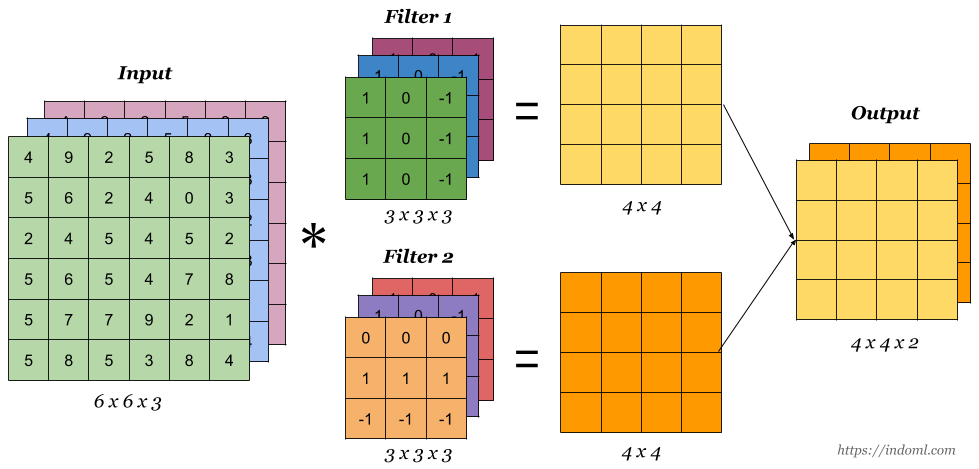
- filter 2개
- 피쳐맵은 2개
- kernal-size(=필터사이즈) = 3x3
