손실함수
회귀와 분류
📍 회귀
주로 MSE - 평균 제곱 오차 사용
📍 분류
주로 Cross Entropy(교차 엔트로피) 사용
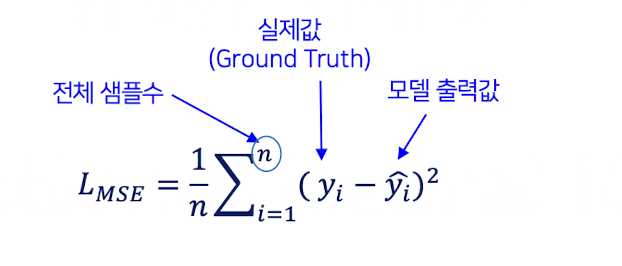
MSE
Mean Squared Error - 평균 제곱 오차
✔️ 회귀용 손실 함수 (숫자를 직접 예측하는 회귀에 사용)
✔️ 모델이 타깃의 평균을 예측하도록 함
✔️ 출력 형태 : 연속적인 실수값
✔️ 오차의 크기를 평가 : 큰 오차에 더 큰 패널티를 부여하여 모델이 오차를 최소화하는 방향으로 학습하도록 함
✔️ 작은 오차에서는 변화량이 작아 학습이 느려질 수 있음
CE
Cross Entropy - 교차 엔트로피
✔️ 확률 기반 분류에 최적화된 손실 함수
✔️ 모델의 예측이 실제 정답과 얼마나 가까운지 평가
✔️ 타깃의 확률분포와 모델의 예측 확률분포의 차이를 나타냄
✔️ 출력 형태 : 확률 분포 (0~1)
✔️ 로그함수가 들어가 있어 정확한 예측일수록 값이 작아짐
✔️ 확률 예측에서 미분값이 크고, 속도가 빠름
✔️ 확률이 0,1과 가까울 때도, 경사가 유지 -> 기울기 소실 문제 적음
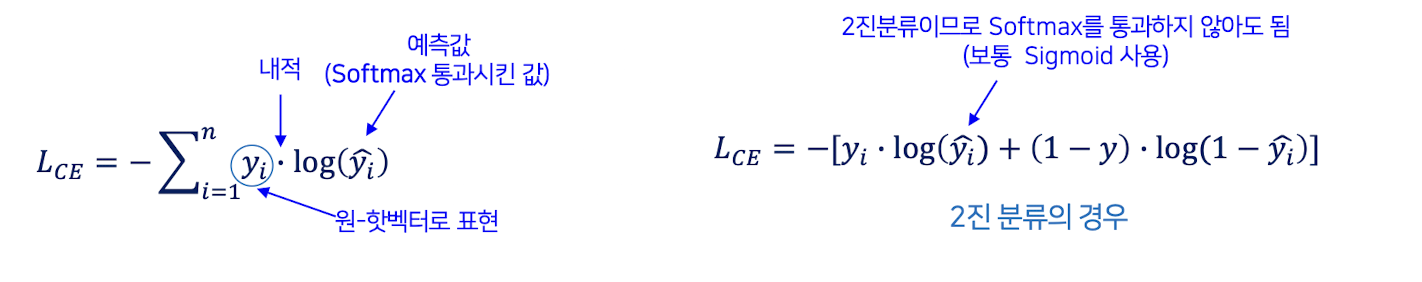
예제1
클래스가 3개인 분류 문제
📍 예측이 정답을 잘 맞춘 경우
✔️ 정답 레이블 : 클래스 2 -> 원-핫 인코딩 : y=[0 , 1 , 0]
✔️ 모델의 예측 확률값(softmax 통과한 값) : y'=[0.2 , 0.7 , 0.1]
✔️ 예측이 어느정도 정답이 근접함 -> 손실값이 낮음
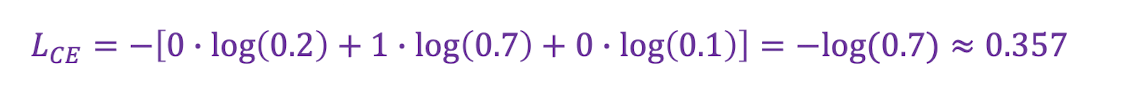
📍 예측값이 엉망인 경우
✔️ 모델의 예측 확률값 : y'=[0.8 , 0.1 , 0.1]
✔️ 정답 클래스에 대해 예측 확률이 낮음 -> 손실값이 커짐
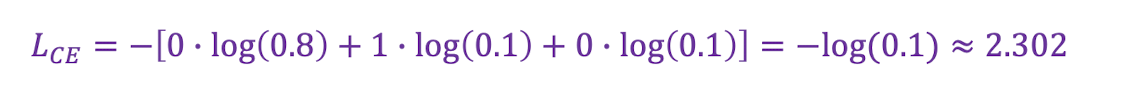
예제2
2진 분류 사례
📍 정답이 1인 경우
✔️ 정답 : y=1
✔️ 모델 예측 : y'=0.9
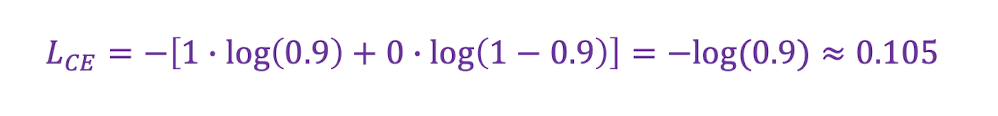
📍 정답이 1인데, 예측이 잘못된 경우
✔️ 정답 : y=1
✔️ 모델 예측 : y'=0.1
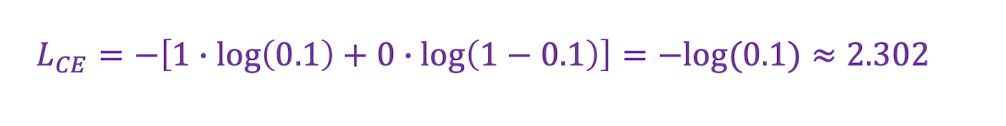
MSE+Sigmoid
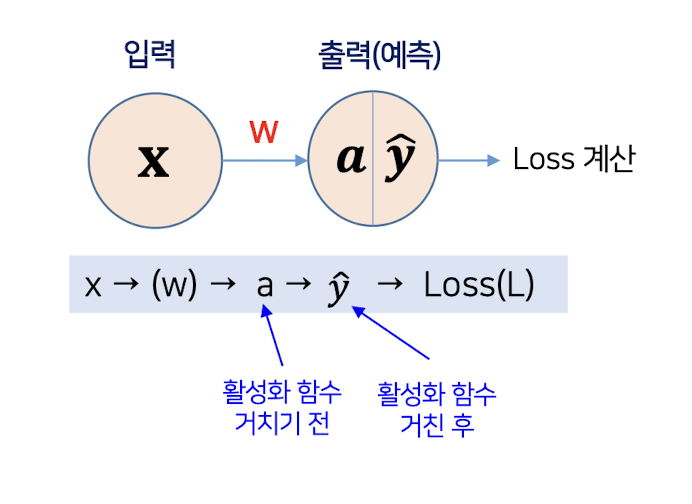
📍 MSE(손실 함수)
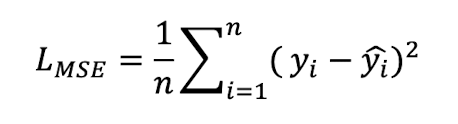
📍 Sigmoid(활성화 함수)
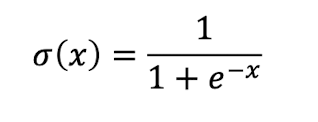
📍 MSE+Sigmoid 미분
✔️ Sigmoid를 포함한 전체 미분

✔️ MSE는 작아진 시그모이드 기울기에 오차도 곱하기 때문에 매우 작은 기울기를 만들어 냄
-> MSE와 Sigmoid를 함께 사용하면 학습이 매우 느려짐
CE+Sigmoid, CE+Softmax
📍 Cross Entropy
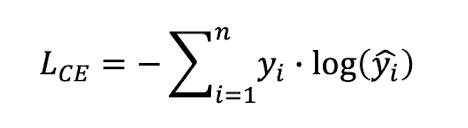
📍 CE+Sigmoid 미분 == CE+Softmax 미분
CE+Sigmoid 미분결과와 CE+Softmax 미분결과는 동일

📍 차이점
✔️ Sigmoid (거의 사용x)
시그모이드: 각 클래스에 대해 독립적인 확률을 부여
확률의 총합이 1이 아니므로 클래스 간 상관관계가 없는 문제에 주로 사용됨
➡️ 다중 레이블 분류
✔️ Softmax
클래스간 경쟁을 유도하여 Softmax와의 결합은 클래스 간 확률 분포를 고려하는 문제에서 주로 사용됨
➡️ 다중 클래스 분류
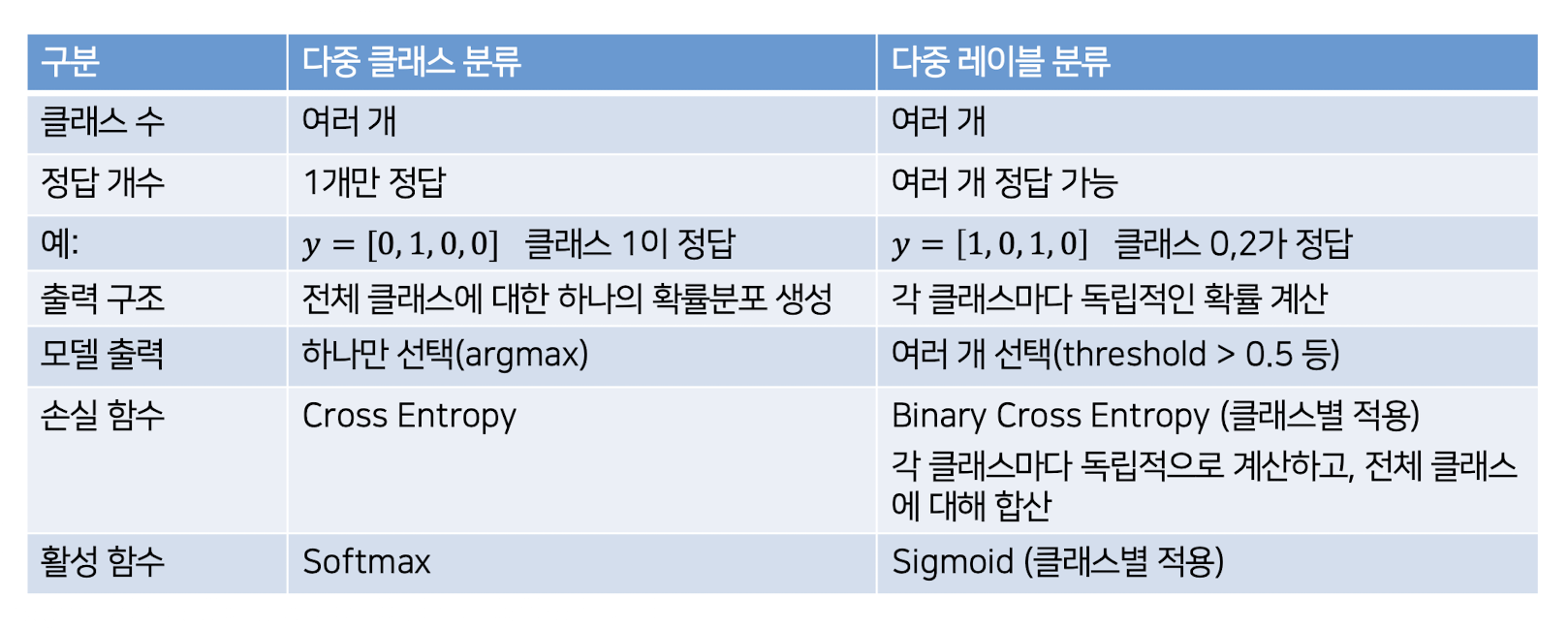
다중 클래스/레이블 분류
다중 클래스 분류
하나의 입력 샘플이 여러 개의 클래스 중 단 하나의 클래스에 속하는 문제
✔️ 특징
클래스들이 서로 배타적이므로ㅡ 하나의 샘플은 오직 하나의 클래스에만 할당
✔️ 정답
단일 클래스
✔️ 출력값
일반적으로 확률 벡터(Softmax)로 나타내며, 가장 높은 확률을 가진 클래스로 예측
✔️ 출력 형태
보통 One-hot encoding or 정수 인덱스로 표현됨
✔️ 손실함수
Categorical Cross-Entropy
✔️ 출력 활성함수
Softmax를 사용하여 가장 확률이 높은 하나의 클래스를 선택
(확률값을 정규화하여 클래스간 비교가 더 명확하게 함)
다중 레이블 분류
클래스들이 서로 독립적이므로, 하나의 샘플이 여러 개의 클래스를 가질 수 있음
✔️ 정답
다중 클래스
✔️ 출력값
클래스별 확률 벡터(시그모이드)로 나타내며, 각 클래스에 대해 독립적으로 예측
✔️ 출력 형태
각 클래스별로 0 or 1로(binary encoding) 표현됨
✔️ 손실함수
Binary Cross-Entropy
✔️ 출력 활성함수
Sigmoid
(각 클래스에 대해 독립적인 확률 부여)