다양한 Optimizer
Optimizer
머신러닝 및 딥러닝 모델의 학습 과정에서 손실함수의 값을 최소화하여 모델이 최적의 파라미터를 찾도록 하는 알고리즘
➡️ 모델이 더 좋은 성능을 내도록 가중치 조정
종류
- 경사 하강법(Gradient Descent)
- Momentum
- AdaGrad
- RMSprop
- Adam
- AdamW
- ...
경사 하강법
경사 하강법
손실함수의 기울기(Gradient)를 계산한 후, 가중치를 기울기 방향으로 조금씩 조정하면서 손실의 최적점을 찾아가는 방식
✔️ 생성 배경
손실함수의 곡면에서 경사가 가장 가파른 곳으로 내려가다 보면 언젠가 가장 낮은 지점에 도달한다는 가정하에 만들어 짐
✔️ 한계
다양한 상황에 잘 대처하지 못하고, 학습 속도도 느림
📍 Batch Gradient Descent(BGD)
전체 데이터셋을 사용해 한 번에 업데이트하므로, 안정적이지만 계산량이 많음
📍 Stochastic Gradient Descent(SGD)
하나의 샘플(데이터 포인트)씩 업데이트
하나의 데이터는 무작위로 선택되며 기울기를 계산하고 파라미터를 업데이트하고 난 후에는 다른 데이터에서 다시 무작위로 선택
-> 지역 최저점 문제 완화 가능
계산량이 적지만, 기울기 방향이 급격하게 변하는 지역에서는 업데이트가 계속 왔다갔다 하면서 효과적으로 내려가지 못하고 진동할 가능성이 있음
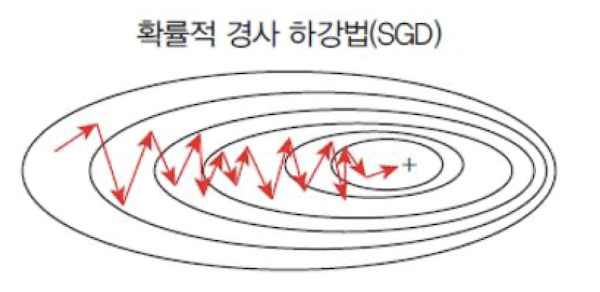
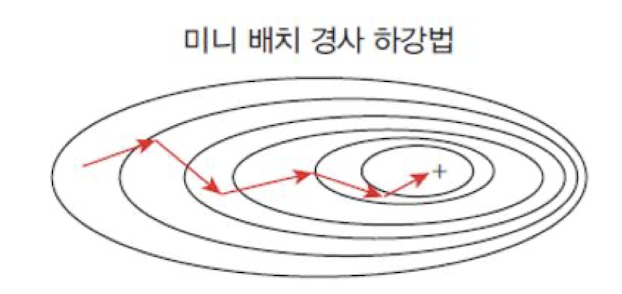
📍 Mini Batch Gradient Descent(MBGD)
여러개의 샘플을 묶어(batch) 업데이트하는 방식
BGD와 SGD의 장점을 적적히 활용
SGD+Momentum
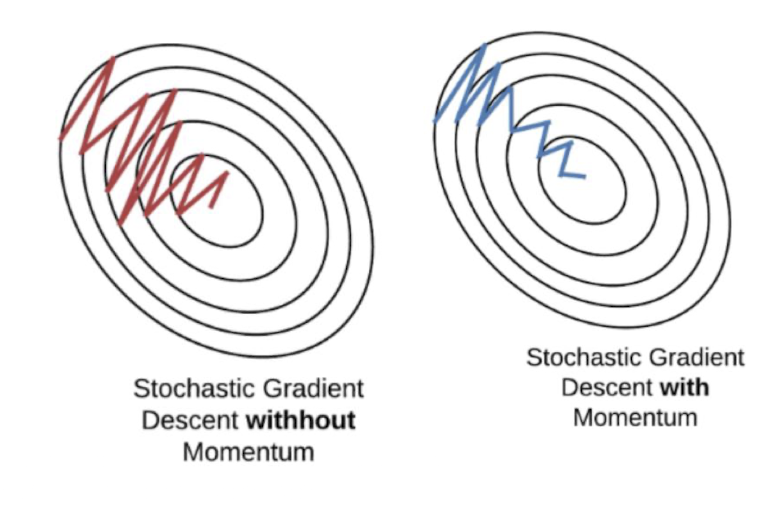
모멘텀을 사용한 SGD
모멘텀: 이전 업데이트 방향을 기억하고 그 방향으로 계속 움직이도록 함. 이전에 이동한 방향과 속도를 활용하여 진동을 줄이고, 수렴 속도를 높힘.
지금 기울기 + 이전 기울기 2가지를 모두 고려하여 방향을 결정
➡️ 가중치 변경 이력이 현재 가중치에 영향을 미침
➡️ 이전 기울기를 고려하기 때문에 지역 최저점에서 빠져나갈 수 있음
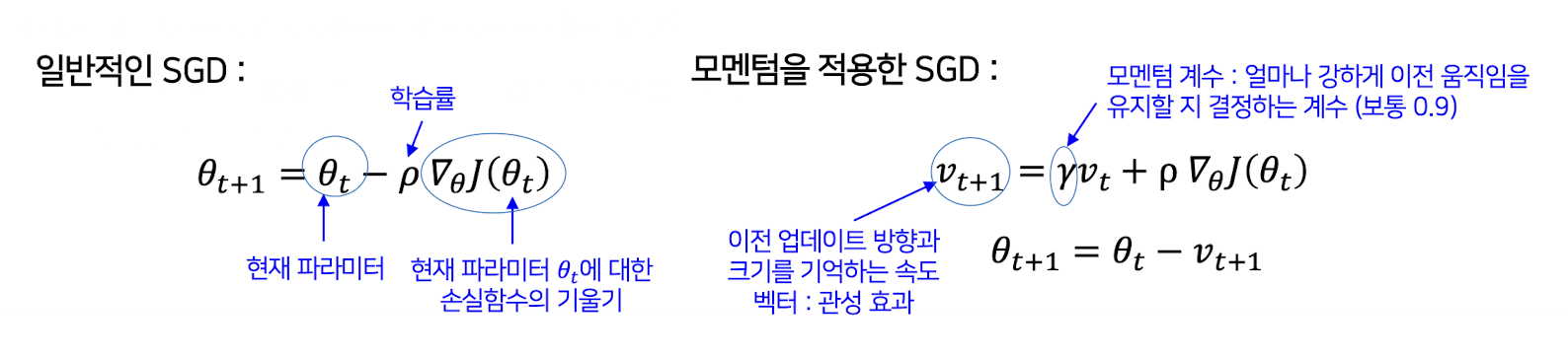
예제1
학습률 ρ=0.1, 모멘텀 𝛾=0.9, 초기 속도 𝑣0= 0

이전 이동 방향을 기억해 관성(모멘텀)을 부여하여 최적점을 향한 움직임을 안정적이고 부드럽게 만듦
같은 방향으로 지속적으로 움직이면 가속되어 빠르게 학습
방향이 급격히 바뀌는 경우 속도를 줄이며 진동 방지
AdaGrad
Adaptive Gradient
AdaGrad
학습률을 파라미터마다 동적으로 조절하여 학습 속도 개선
➡️ 자주 업데이트된 가중치의 학습률을 작게(조금씩 업데이트), 거의 업데이트되지 않는 가중치의 학습률은 크게(더 크게 업데이트)
➡️ 희소 데이터(sparse data-대부분 입력값이 0이고, 일부 위치에만 의미 있는 값이 존재하는 데이터)에 효과적
ex) NLP(Word2Vec, GloVe)
📍 핵심 과정
모든 파라미터(가중치)에 대해 각 파라미터에 대한 기울기의 제곱값을 누적하여 기록
➡️ 누적된 값을 이용하여, 모든 파라미터에 대해 개별적인 학습률을 조정, 학습률의 과거의 기울기 크기에 반비례하도록 조정
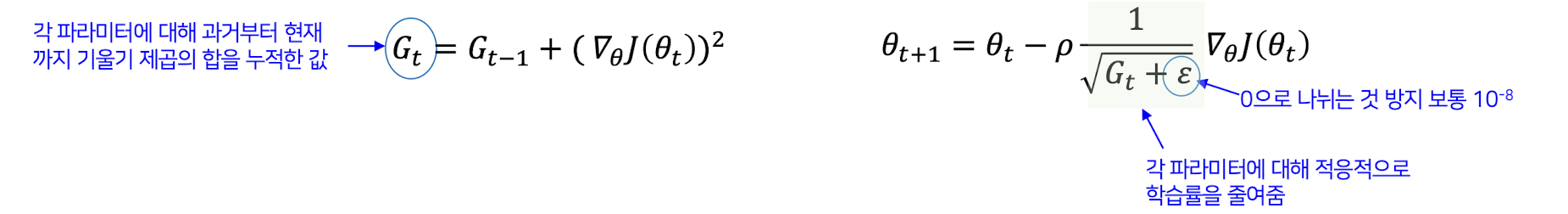
Gt가 큰 파라미터(자주 업데이트 된 파라미터)는 학습률이 점점 작아짐.
Gt가 작은 파라미터(업데이트가 자주 안되는 파라미터)는 상대적으로 학습률이 크게 유지됨.
📍 단점
제곱합을 계속 누적하므로, 시간이 지날수록 분모가 계속 커지고 학습률이 매우 작아져서 학습이 초기에 멈추는 현상(조기 정체)이 발생할 수 있음
➡️ 그래서 RMSprop이 등장하게 됨
예제1
학습률 𝜌=0.4, 초기 𝐺0= 0

많이 업데이트된 파라미터의 학습률은 낮추고, 적게 업데이트된 파라미터의 학습률은 높게 유지하여 균형 잡힌 학습 수행
한계점: 시간이 지날수록 학습률이 점점 작아져 나중에는 거의 움직이지 않게 되는 문제 발생(학습 후반부 수렴 속도 저하)
RMSprop
Root Mean Square Propagation
RMSprop
AdaGrad의 단점을 보완하기 위해 제안된 Optimizer
✔️ AdaGrad는 과거의 모든 기울기의 제곱합을 무한정 누적
➡️ 학습률이 급격히 작아져 학습이 느려지는 문제가 발생
✔️ RMSprop는 과거의 기울기를 모두 누적하지 않고, 최근의 기울기만 중점적으로 반영

예제1
𝐺0=0, 학습률 𝜌=0.1, 초기 𝛽=0.9
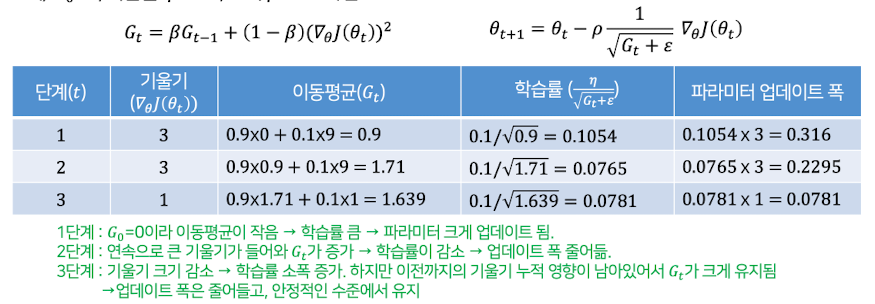
AdaGrad보다 훨씬 더 안정적인 학습 가능(학습률이 너무 작아지는 문제 방지)
여전히 학습률(초기 p) 설정에 민감한 편
Adam
Adam
Momentum과 RMSprop을 결합한 옵티마이저
Momentum처럼 기울기 방향을 기억하고, RMSprop처럼 최근 기울기 크기를 기준으로 학습률을 조정
Momentum의 장점 : 이전의 기울기 방향을 기억해서 부드럽게 이동
RMSprop의 장점: 최근 기울기 크기에 따라 적응적으로 학습률을 조정
📍 핵심 개념
✔️ 기울기의 1차 모멘트(이동평균)와 2차 모멘트(제곱 이동평균)를 계산

✔️ 모멘텀 보정 및 파라미터 업데이트

예제1
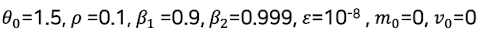
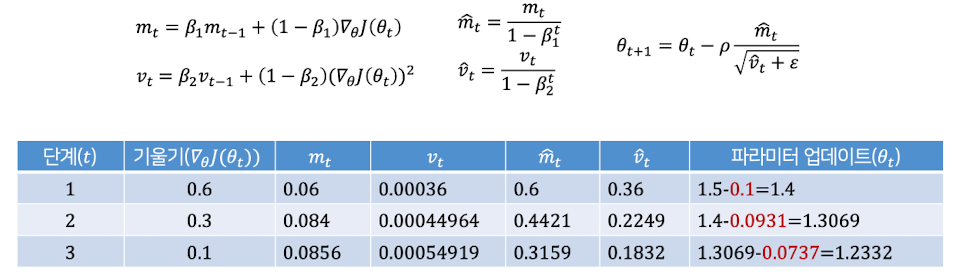
초기에는 기울기 크기에 민감하게 반응하지만, 시간이 지나며 과거 정보를 더 많이 반영하고 폭이 지나치게 크거나 작아지는 걸 막아줌
AdamW
AdamW
Adam + 명시적 Weight Decay
Adam의 최적화 과정에, 별도로 명시적인 가중치 감소(weight decay)를 추가해서 더 강력한 정규화 효과
✔️ 기존의 Adam에서는 손실함수에 정규화 항을 더하고, 그걸 기울기와 함께 합쳐 업데이트에 넣는 방식
➡️ 정규화항이 1차 모멘텀과 2차 모멘텀에 포함되어 정규화 항의 효과가 기울기 보정(m,v) 과정에 의해 왜곡됨
✔️ AdamW는 이런 문제를 해결하기 위해 decay항을 gradient 처리에서 완전 분리
일반적으로 Adam보다 더 나은 일반화 성능을 가짐
특히 대규모 모델(BERT, GPT 등)에서 추천
현재 대부분의 최신 딥러닝 연구에서 AdamW를 기본 옵티마이저로 활용

예제1
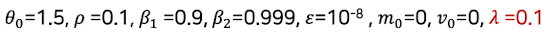
Weight Decay, L2 Regularization
과적합을 방지하고 일반화 성능을 높이기 위해 사용하는 대표적인 정규화 기법
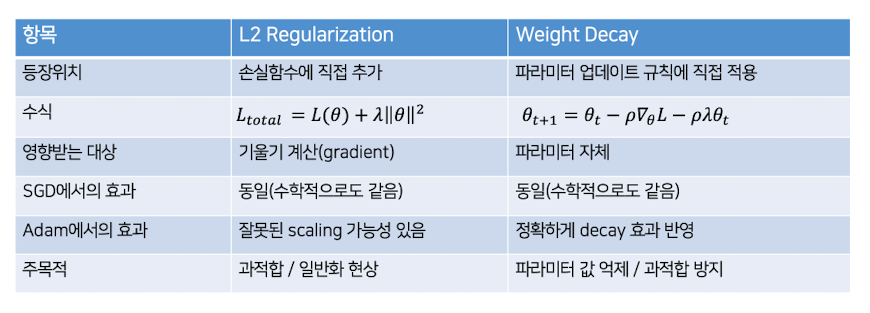
L2 Regularization
L2 정규화(Ridge 정규화)와 본질적으로 동일
손실함수에 정규화항 𝜆||𝜃||²을 추가하는 방식
➡️ 기울기 자체를 증가시켜서 파라미터를 더 많이 깎는 방식

Weight Decay
손실함수에 추가하지 않고, 업데이트 시점에 파라미터를 일정 비율만큼 직접 감소시키는 방식
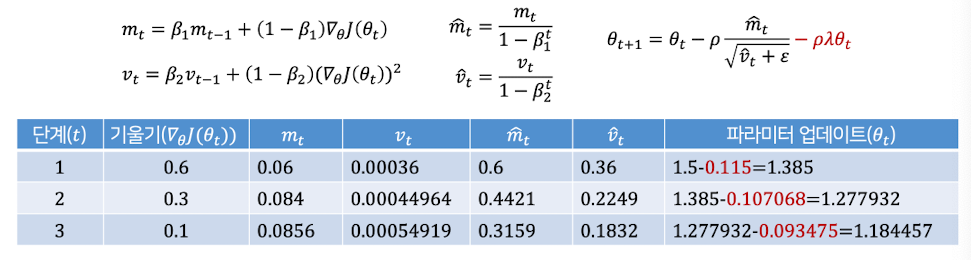
업데이트 공식에 −𝜌𝜆𝜃 항을 직접 추가
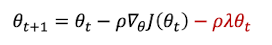
➡️ 파라미터를 직접 깎는 방식 : 기울기에 영향을 주지 않고 파라미터 자체만 줄임
(정규화 효과가 기울기 연산과 독립적으로 작용)
비교
Learning Rate Scheduling
학습률 스케줄링
사용자가 학습률 변화를 사전에 정의하는 방식
고정 학습률을 사용하는 대신 스케줄링을 사용
➡️ 초반에는 큰 학습률로 빠르게 최적화, 후반에는 작은 학습률로 미세 조정
➡️ 과적합 방지 + 더 높은 최종 성능
특정 시점에 학습률을 낮춰 최적의 성능을 찾을 수 있지만, 적절한 스케줄을 찾는 것이 어려울 수 있음
📍 Step Decay: 단계적 감소
일정한 epoch마다 학습률을 감소시키는 방식
안정적인 학습이 가능함
📍 Expoential Dacay: 지수적 감소
학습률을 지수함수처럼 감소시키는 방식
ex) 매 epoch마다 학습률을 95%로 줄이기
📍 Cosine Annealing: 코사인 감소
코사인 함수처럼 점점 줄이다가 다시 크게 조정하는 방식
주로 SGD+Momentum과 함께 사용
실제로 Adam계열 사용시에는 학습률 스케줄링이 덜 필요하지만, SGD 사용시 필수적
대형 SGD를 사용하는 CNN 모델을 사용하는 경우 좋음
📍 ReduceLROnPlateau: 손실 정체 시 감소
학습이 정체되면 학습률을 자동으로 줄이는 방식
ex) 검증 손실이 줄어들지 않으면 학습률 감소
손실이 정체되면 학습률을 줄이고 싶을 때 사용
📍 OneCycleLR: 1주기 학습률 조정
초반에는 LR을 증가시키고, 이후에는 줄여서 빠르게 학습하면서 최적화
ResNet, EffieientNet 등에서 자주 사용
빠르게 수렴하고 싶을 때 사용
Optimizer 선택 기준
데이터와 모델에 따라 최적의 옵티마이저가 다를 수 있으니, 여러 옵티마이저를 실험하면서 가장 좋은 성능을 내는 걸 선택하는 것이 중요
컴퓨터 비전에서는 문제의 복잡도, 데이터의 크기, 모델 아키텍처의 특성, 그리고 학습 단계(초기 수렴vs미세 조정)에 따라 옵티마이저 선택 기준이 달라짐
초기 학습: Adam이나 RMSprop과 같이 빠른 수렴을 보이는 옵티마이저 사용
후반 학습 및 일반화: SGD+Momentum 및 적절한 학습률 스케줄링 활용
하이퍼파라미터 튜닝: 실험을 통해 데이터와 모델에 맞는 최적의 설정을 찾아내는 것이 핵심
데이터셋 크기
📍 작은 데이터셋
ex) MNIST, CIFAR-10
일반적으로 SGD+Momentum이 좋은 성능을 보임
Adam이나 RMSprop을 사용하면 빠르게 수렴하지만, 과적합 위험이 커질 수 있음
📍 대형 데이터셋
ex) ImageNet, COCO
Adam, RMSprop이 빠르게 학습 가능
최신 연구에서는 SGD+Momentum+Cosine Annealing이 더 나은 성능 내는 경우도 있음
모델 구조
📍 단순한 모델: 얕은 네트워크
기본적으로 SGD+Momentum
Adam이나 RMSprop도 사용하지만 성능이 크게 다르지 않음
📍 복잡한 모델: 깊은 네트워크
ex) RestNet, EfficientNet, VIT
AdamW or SGD+Momentum+학습률 스케줄링이 효과적
Adam은 빠르게 수렴가능하지만, 일반화 성능이 낮을 수 있으므로 AdamW(Adam+Weight Decay)를 많이 사용함
📍 트랜스포머 기반 모델
ex) VIT, Swin Transformer
AdamW가 표준적인 Optimizer로 사용됨
특히, Vision Transformer(VIT)는 SGD보다 Adam계열이 훨씬 좋은 성능을 냄

학습 속도
📍 빠른 수렴이 중요할 때
Adam, RMSprop 사용 ➡️ 초반 학습 속도가 빠름
하지만 일반화 성능이 낮아질 가능성이 있음
📍 일반화 성능이 중요할 때
SGD+Momentum ➡️ 느리지만 최종 성능이 더 좋을 가능성이 큼
Cosine Annealing과 같은 학습률 스케줄링 기법과 함께 사용하면 효과적
HW 성능
GPU 성능
📍 Adam계열
Adam, AdamW, RMSprop
계산량이 많아서 GPU 메모리 사용량이 큼
작은 GPU에서는 batch size를 줄여야할 수 있음
📍 SGD Momentum
상대적으로 메모리 사용량이 적고 효율적
대형 모델을 학습할 때 선호됨
