
1. 분류와 회귀의 차이
1.1 이산적 변량과 연속적 변량
수학에서 '이산'이란, 서로 떨어져 있는 값들을 의미한다. (이산가족)
이산적 변량은 수량이 이산적으로 변하는 경우
연속적 변량은 수량이 연속적으로 변하는 경우
이산적 변량은 계단처럼 뚝뚝 끊어지며
연속적 변량은 부드럽게 이어진다.

1.2 분류, 이산적 변량의 세계
카테고리가 n개로 분류되고, 그 중에서 반드시 하나를 선택해야 하므로 분류 문제는 이산적 변량의 세계
1.3 회귀, 연속적 변량의 세계
분류에서는 학생의 키를 (작은 편/큰 편) 등 이산적으로 예측할 수 밖에 없다.
회귀에서는 학생의 키를 (165.4cm) 등 수치로 바로 예측할 수 있다.
회귀는 예측 결과가 어떤 카테고리로 딱딱 분류되는 것이 아닌, 구체적인 수치를 예측하도록 학습시키는 방법
2. 체격만 보고 체중 추론하기
2.1 프로젝트 소개
사람의 덩치를 보면 대략적인 몸무게를 추측할 수 있다.
키가 같다면 허리둘레가 두꺼운 사람이 체중이 더 무거울 것으로 추측할 수 있다.
딥러닝으로 체중을 예측하는 인공지능을 만들어 본다.
2.2 데이터 살펴보기
대한민국 국방부에서 공개한 병무청 신체검사 데이터를 활용한다.
가슴 둘레, 소매 길이, 신장, 허리 둘레, 샅높이(바닥에서 가랑이까지 높이), 머리 둘레, 발 길이 총 7개의 피쳐를 X값으로 사용
몸무게는 Y값으로 사용
각각의 피쳐와 Y값은 최댓값으로 나눠 0부터 1사이의 소수로 노멀라이즈하여 사용.
데이터의 80%는 트레이닝, 20%는 테스트로 사용
2.3 어떤 인공지능을 만드나
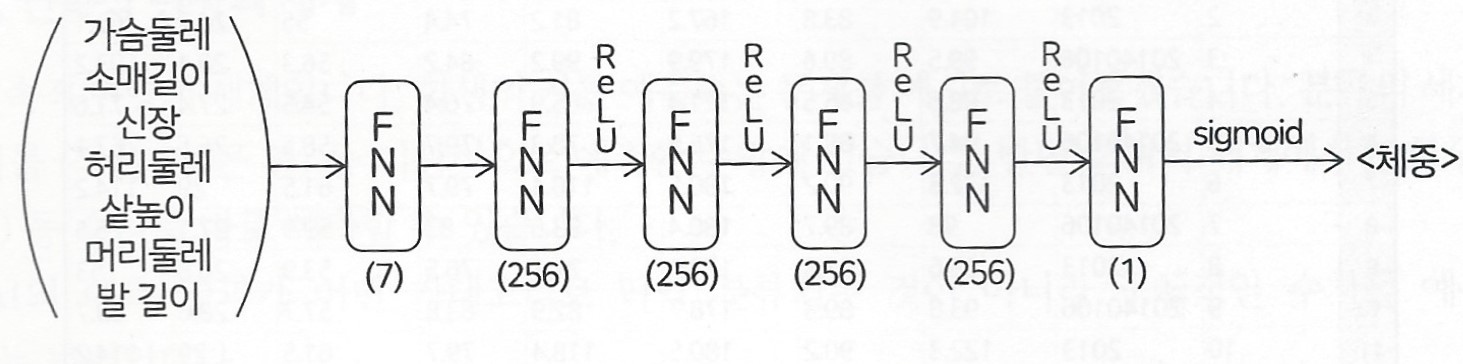
(1) 신경망의 구조

총 7개의 피쳐를 입력받기 위해 입력층의 크기는 7
최종적으로 체중 값 1개만을 예측하므로 출력층의 크기는 1
앞서 노멀라이즈를 통해 체중값을 0부터 1 사이의 값으로 변환하였기에,
출력층의 출력값 또한 0부터 1 사이의 숫자가 되도록 sigmoid 함수를 활성화 함수로 적용
2~5층 신경망은 크기를 256으로 통일
2.4 딥러닝 모델 코딩
(1) 라이브러리 불러오기
from tensorflow import keras
import data_reader(2) 에포크(Epoch) 결정하기
# 몇 에포크 만큼 학습을 시킬 것인지 결정합니다.
EPOCHS = 50 # 예제 기본값은 50입니다.(3) 데이터 읽어오기
# 데이터를 읽어옵니다.
dr = data_reader.DataReader()(4) 인공신경망 제작하기
# 인공신경망을 제작합니다.
model = keras.Sequential([
keras.layers.Dense(7),
keras.layers.Dense(256, activation="relu"),
keras.layers.Dense(256, activation="relu"),
keras.layers.Dense(256, activation="relu"),
keras.layers.Dense(256, activation="relu"),
keras.layers.Dense(1, activation='sigmoid')
])이번에는 인공신경망을 총 6층으로 쌓아 올려본다.
(5) 인공신경망 컴파일하기
# 인공신경망을 컴파일합니다.
model.compile(optimizer="adam", loss="mse", metrics=['mae'])optimizer는 adam,
loss는 mae,
metrics는 mae
실제 체중에서 인공지능이 예측한 체중을 뺀 수치를 오차(error)라고 부른다.
경우에 따라 오차가 음수일 수도 있다.
음수 오차가 포함된 값을 평균을 내버리면 실제보다 오차가 적은 것으로 결과가 왜곡될 수도 있다.
mse, mae는 이런 문제를 방지하기 위해 도입된 계산법
음수는 제곱하면 양수가 되므로,
오차의 크기를 모두 양수 범위로 만들기 위해 오차를 제곱한 것을 제곱 오차(squared error)라고 부른다.
제곱 오차를 여러 개 구한 다음 평균을 구한 값을 평균 제곱 오차(mean squared error, mse)라고 부른다.
mse는 인공지능이 예측한 대량의 결과물을 손쉽게 하나의 점수로 수량화할 수 있다는 장점이 있다.
분류 문제에서 크로스 엔트로피를 주로 사용하듯,
회귀 문제에서는 mse를 주로 사용한다.
1.5 인공지능 학습
(1) 인공신경망 학습
# 인공신경망을 학습시킵니다.
print("\n\n************ TRAINING START ************ ")
early_stop = keras.callbacks.EarlyStopping(monitor='val_loss', patience=10)
history = model.fit(dr.train_X, dr.train_Y, epochs=EPOCHS,
validation_data=(dr.test_X, dr.test_Y),
callbacks=[early_stop])val_loss를 대상으로 콜백,
fit() 함수를 실행하여 학습 진행
(2) 학습 결과 출력
# 학습 결과를 그래프로 출력합니다.
data_reader.draw_graph(model(dr.test_X), dr.test_Y, history)history 변수에 저장된 학습 과정을 그래프로 출력한다.
model(dr.test_X) 명령은 인공지능에 test_X를 입력하여 출력 결과를 뽑아내도록 한다.
AI의 추론값과 dr.test_Y를 비교하여 회귀학습의 결과를 한눈에 볼 수 있는 그래프를 그린다.
(3) 전체 코드
from tensorflow import keras
import data_reader
# 몇 에포크 만큼 학습을 시킬 것인지 결정합니다.
EPOCHS = 50 # 예제 기본값은 50입니다.
# 데이터를 읽어옵니다.
dr = data_reader.DataReader()
# 인공신경망을 제작합니다.
model = keras.Sequential([
keras.layers.Dense(7),
keras.layers.Dense(256, activation="relu"),
keras.layers.Dense(256, activation="relu"),
keras.layers.Dense(256, activation="relu"),
keras.layers.Dense(256, activation="relu"),
keras.layers.Dense(1, activation='sigmoid')
])
# 인공신경망을 컴파일합니다.
model.compile(optimizer="adam", loss="mse", metrics=['mae'])
# 인공신경망을 학습시킵니다.
print("\n\n************ TRAINING START ************ ")
early_stop = keras.callbacks.EarlyStopping(monitor='val_loss', patience=10)
history = model.fit(dr.train_X, dr.train_Y, epochs=EPOCHS,
validation_data=(dr.test_X, dr.test_Y),
callbacks=[early_stop])
# 학습 결과를 그래프로 출력합니다.
data_reader.draw_graph(model(dr.test_X), dr.test_Y, history)1.6 인공지능 학습 결과 확인하기
(1) 인공지능의 성능 확인하기

콜백이 작동하여 43에포크에서 학습이 멈췄다.
val_mae가 AI의 최종 성능
이 AI의 성능은 mae 기준 0.0257
AI가 대략 97% 이상의 정확도로 값을 예측할 수 있다는 이야기
(2) 학습 기록 확인하기

Loss History에서 빨간선이 트레이닝, 파란선이 테스트
전반적으로 트레이닝에 비해 테스트가 성능이 더 뛰어남
오비피팅과는 반대되는 현상
학습이 잘 된 것으로 판단된다.
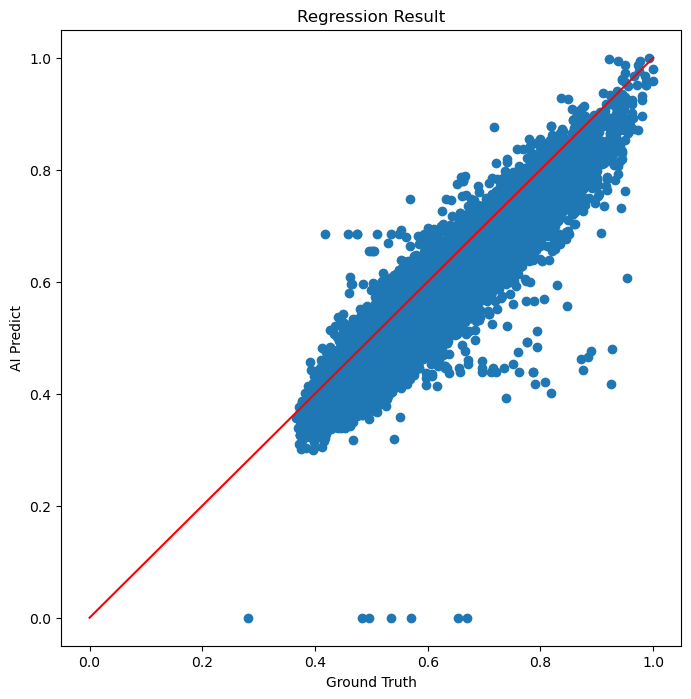
Regression Result는 회귀 결과를 통계적으로 표현한 그래프
화면의 중앙을 직선이 지나고 있다.
점들은 예측한 값과 실제 데이터 사이의 비율
점이 직선 주위에 모여 있을수록 회귀 성능이 뛰어난다.
점이 직선보다 아래쪽에 있으면 예측값이 실제값보다 낮은 것이고,
점이 직선보다 위쪽에 있으면 예측값이 실제값보다 높은 것
여기선 대부분의 점이 선에 밀착하여 분포하고 있다.
학습이 잘 된 것으로 판단된다.
AI가 예측한 체중은 실제값보다 약간 작은 편
1.7 외삽(extrapolation)과 내삽(interpolation)
회귀에는 외삽과 내삽이 있다.
X로 표시된 지점은 데이터가 확보된 지점
머신러닝을 통해 ?로 표시된 지점의 Y축 값을 예측하려는 상황
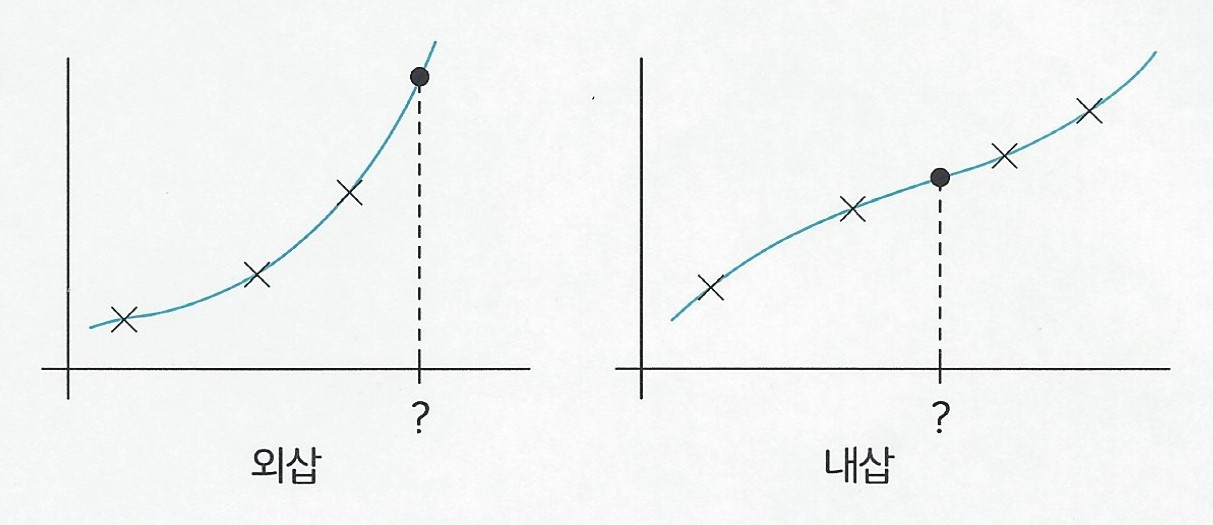
외삽은 학습에 사용한 데이터의 바깥 범위를 예측하기 위한 기법
과거와 현재 데이터를 분석해 미래를 예측하려는 시도
ex) 미래 출산율 예측, 금융사의 주가 등락 예측
내삽은 학습에 사용된 데이터의 내부 범위를 예측하기 위한 기법
주변 데이터의 도움을 받아 값을 추론
소실된 정보를 복원하기 위해 사용하며, 신호를 일부 생략하여 전송한 다음 수신자가 내삽을 통해 원본 신호를 복원하여 데이터 전송량을 압축하는 데 사용하기도 한다.
