https://arxiv.org/pdf/2005.00247.pdf?
기존에는 Sequential fine-tuning과 multi-task learning 을 사용했다.
그러나 catastrophic forgetting과 새로운 task를 추가하기 어렵다.
Sequential fine-tuning - 여러 task를 순차적으로 학습하는 방식
Multi-Task learning - 학습시마다 모든 task의 data에 접근해 동시에 학습 수행.
새로운 task를 추가하기 어려움catastrophic forgetting - 파괴적 망각 / 단일 과제 (single task) 에 대해서는 뛰어난 성능을 보이지만, 다른 종류의 task를 학습하면 이전에 학습했던 task에 성능 저하. 이전 dataset과 새로운 학습 dataset 사이에 연관성이 있어도 이전 dataset에 대한 정보를 대량 손실.본 논문은 기존의 문제점을 해결한 two stage learning algorithm인 AdapterFusion을 제안한다.
-
지식 추출 단계에서 stage 별 정보를 캡슐화하여 stage 별 parameter를 학습한다.
-> Adapter -
지식 구성 단계에서 adpter를 결합한다.
-> 추출과 구성을 분리함으로써 여러 task를 학습할 수 있다.
기존의 방식들은 pretrain -> finetuning으로 학습을 진행했다.
그래서 특정 task에 finetuning된 모델을 재사용하기 위해서는 parameter 전체를 공유해야 한다.
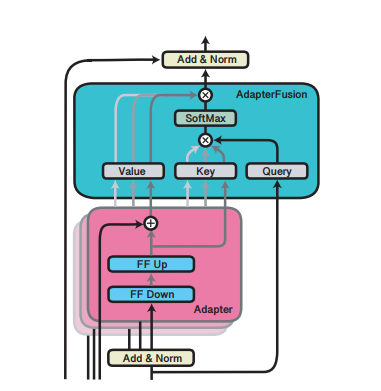
AapterFusion architecture
Adaper는 finetuning 단계에서 전체 parameter를 학습 하지 않는다.
transformer layer 사이에 adapter layer를 일정 layer 개수마다 1개씩 배치하고 finetuning 단계에서 adapter layer만 학습한다.
전체 parameter에 비해 adapter parameter는 적어서 빠르게 학습 가능하며, adapter만 재사용해도 되기에 공유하기 용이하다. 용량 차지도 적다.
기존의 방법과 비교했을때 비슷하거나 소폭 하락한 성능을 보여준다.
-> parameter가 적어졌음에도 성능은 괜찮다.
AdapterFusion은 다수의 task를 공유하기 위해 two-stage learnig algorithm을 도입한 새로운 architecture을 제안한다.
첫 stage에서 학습한 adapter를 adapterfusion을 이용하여 결합해 최종 결과를 출력한다.
adapter는 하나의 task로만 학습된 single-task adapter와 다수의 task를 동시에 학습시킨 multi-task adapter를 모두 사용한다.
parameter
매개변수, 모델 내부에서 결정되는 변수 -> 그 값은 데이타로부터 결정됨
ex) 정규분포를 그리면 평균과 표준편차가 구해진다. 평균과 표준편차가 파라미터임.
hyper parameter
모델링할 때 사용자가 직접 세팅해주는 값