http://proceedings.mlr.press/v119/chen20v/chen20v.pdf
Graph convolutional networks(GCNs)
최근 대부분의 GCN 모델들은 over-smoothing 문제가 있다.
over-smoothing
지나친 획일화 / 그래프 신경망의 층의 수가 증가하면서 정점의 임베딩이 서로 유사해지는 현상이다. 전반적인 그래프를 보게되어 정점들이 비슷한 임베딩을 얻게 되어 분류 성능이 떠어진다. 본 논문에서는 GCNII을 제시한다.
Initial residual and Identity mapping.
이 두 가지 기술과 함께 vanilla GCN 모델을 확장했다.
semi - 혹은 full-supervised tasks 에서 최첨단 성능을 보여준다.
일단 GCNs은 CNNs의
2-layer GCN, GAR는 좋은 성능을 보여준다.
그러나 고차원으로 갈수록 over-smoothing 문제가 일어난다.
ResNet은 비슷한 문제를 컴퓨터 비전에서 해결했다 residual connection으로
하지만 GCN에 넣으면 느려진다.
결론적으로 over-smoothing 문제를 핼결을 하고 GCN 모델을 설계하는 것은 아직도 미해결 문제이다.
본 논문이세넌 vanilla GCN에서 두 가지를 수정한다.
Graph Convolutional Network via Initial residual and Identity mapping(GCNII)
각 레이어에 initial residual는 input layer에서 skip connection을 구성하며 ID mapping은 가중치 행렬에 ID행렬을 추가한다.
vanilla GCN은 k개의 layer을 쌓아 미리 결정된 계수를 갖는 다항식 필터의 k번째 차수를 시뮬레이션하는 것이다.
반면 본 논문에서는 k-layer GCNII 모델은 임의의 계수로 차수 k의 다항식 스펙트럼 필터를 표현할 수 있음을 증명한다.
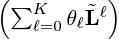
k-layer를 쌓으면서
차수행렬, 인접행렬
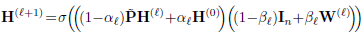
l-th layer GCNII
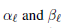
초 매개 변수
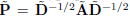
the graph convolution matrix with the renormalization trick
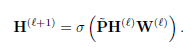
vanilla GCN 과 비교하여
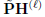
smoothed representation PH를 첫 번째 층 H(0)에 initial residual과 결합한다.
l번째 가중치 행렬 W(l)에 identity mapping In을 추가한다.
We propose that, instead of using a residual connection to carry the information from the previous layer, we construct a connection to the initial representation H(0).
Initial residual만으로는 아직 문제라서
ResNet의 identity mapping을 빌린다.
identity mapping은 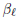
를 충분히 작게 설정함으로, deep한 GCNII는 가중치 행렬 W(l)를 무시하고 본질적으로 APPNP를 시뮬레이션한다.
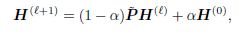
feature matrix의 서로 다른 차원 간의 빈번한 상호 작용은 semi-supervised 작업에서 모델의 성능을 저하시킨다는 것을 발견해서 PH를 직접 출력에 mapping하면 상호 작용이 감소한다.
identity mapping은 semi-supervised 작업에서 특히 유용하다.
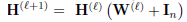
위의 식과 같은 형태의 선형 ResNet은 다음 특성을 만족한다.
1) 최적의 가중치 행렬 W(l)은 작은 norms 갖는다.
-과적합을 피하기 위해 W^l에 강룍한 정규화를 적용할 수 있다.
2) 유일한 임계점은 global minimum이다.
-훈련 데이터가 제한된 semi-supervised 작업에 바람직하다
이론적으로 k-layer GCN의 노드 기능이 subspace로 수렴되어 정보 손실을 발생한다.
특히 수렴 속도는 s^K에 따라 달라지는데, 여기서 s는 가중치 행렬 W(l)의 최대 특이치다. l=0,......,K-1.
W(l)을
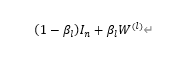
위와 같이 대체하고 W(l)에 정규화를 해서 norm을 작게 한다.
결과적으로, 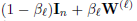
1과 가까울 것이다.
최대 특이치도 1에 가까워 s^K가 크고 정보 손실이 완화된 것을 의미한다.
이것의 원리는 가중치 행렬의 붕괴가 더 많은 층을 쌓을수록 적응적으로 증가한다는 것이다.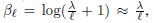
이와 같이 설정하고
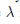
하이퍼 파라미터다.
GCNII와 APPNP/GDC의 차이점은 1) 우리 모델의 계수 벡터 세타가 입력 기능과 레이블에서 학습되고, 2) 각 계층에 ReLU 연산을 부과한다는 것이다
그래프 클러스터링을 기반으로 미니배치
