Segmentation
- FCN의 한계와 Skip-Connection을 적용해 극복한 모델들
- Recptive Field를 확장시킨 모델들
1. FCN의 한계
1) 객체의 크기가 크거나 작은 경우 예측을 잘 못함

- 큰 객체의 경우 지역적인 정보만으로 예측해 전체적인 모습을 예측하지 못함
- 같은 객체여도 다르게 labeling
- 작은 Object가 무시되는 경우가 있음
2) 디테일한 모습이 사라지는 문제
- Deconvolution의 절차가 너무 간단해 경계를 학습하기에는 무리가 있음 (ex FCN-32s, 16s, 8s도 여전히 단순)
2. FC DenseNet, Unet
1) Skip Connection?
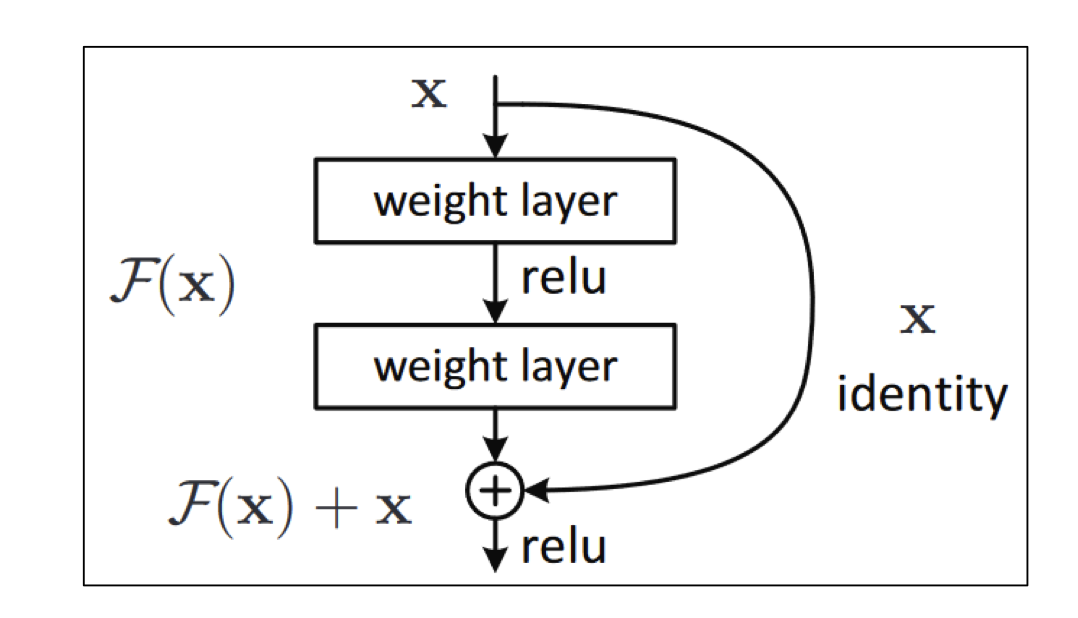
- ResNet에서 소개된 아이디어로 이전 layer의 output을 layer를 건너 뛴 후 layer에게 입력으로 제공
- layer간 gradient흐름을 원활하게해 깊은 네트워크 구성 가능
2) FC DenseNet?
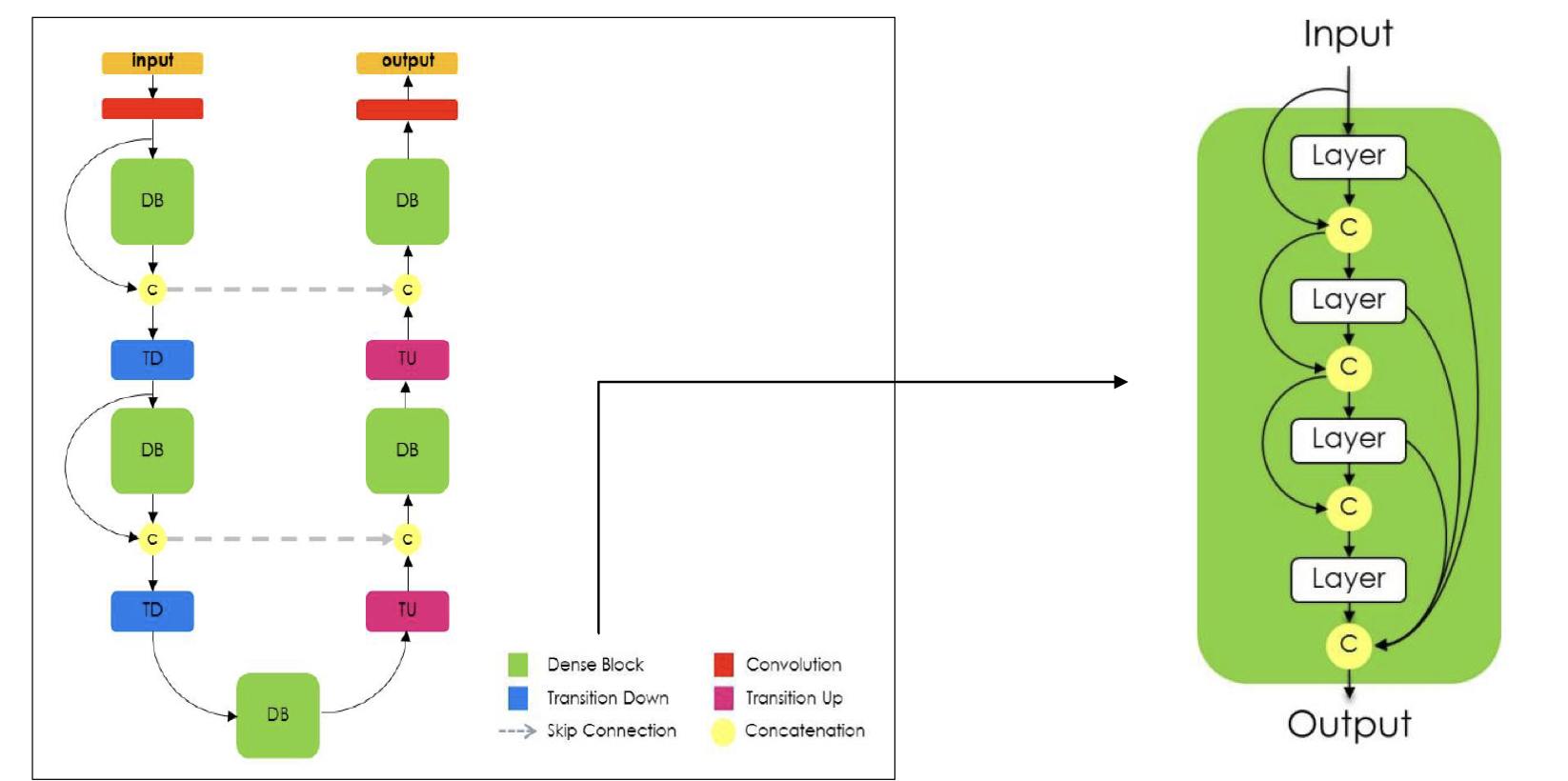
- Encoder에서 Decoder로 Skip connection
- Dense Block에서도 Skip connection 적용
3) Unet?

- FC DenseNet과 마찬가지로 Encoder 부분에서 Decoder 부분으로 Skip connection
- 대칭적으로 각 계층마다 Skip connection 적용
3. DeepLab v1, DilatedNet
Receptive field를 넓혀 성능을 향상 시킨 모델들
1) Receptive field?
- Receptive field는 뉴런이 바라보고 있는 정보의 범위
- 더 넓은 범위의 정보를 포함하고 있는 Receptive field가 예측 확률이 더 높음
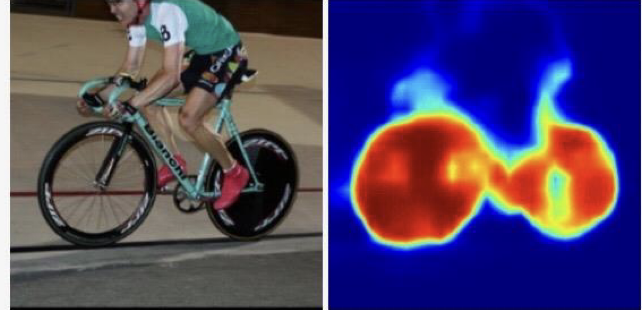
- 이미지 대부분 영역이 버스이지만 Receptive field가 작은 모델은 버스의 일부만 보고서 예측해야함
- 버스에 대한 정보를 다 포함하지 못하고 창문에 비친 자전거나 다른 객체로 인식
- Segmentation task의 예측 정확도를 높이기 위해서는 receptive field를 증가시켜야함
Receptive field를 높이는 방법1
- Convolution, Max Pooling을 반복적으로 사용하면 receptive field를 넓힐 수 있음
-> Resolution 측면에서 low feature resolution을 가지는 문제점이 발생

Recpetive field를 높이는 방법2
- 이미지 크기는 많이 줄이지 않고, 파라미터 수도 변함 없이, Receptive Field만 넓히는 방법 (Dilated Convolution)


- filter가 input 데이터 위에서 연산할 때 dilation rate를 주어 더 넓은 범위를 연산할 수 있도록함
- 결과적으로 high feature resolution
- 파라미터는 기존 3x3 convolution과 똑같고 Receptive Field만 넓어짐
2) DeepLab v1?
- Dilation rate를 설정한 Convolution Layer를 통해 Receptive Field를 넓힌 모델
3) Architecture(DeepLab-LargeFOV)

- Conv는 Conv2d와 ReLU로 이루어짐
def conv_relu(in_channels, out_channels, kernel_size=3, rate=1):
return nn.Sequential(nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=rate, dilation=rate) # padding과 dilation을 같게- conv1
self.features1 = nn.Sequential(
conv_relu(3, 64, 3, 1),
conv_relu(64, 64, 3, 1),
nn.PaxPool2d(3, streide=2, padding=1) # 2x2 -> 3x3으로 변경, 입력이미지 1/2
)- conv2
self.features2 = nn.Sequential(
conv_relu(64, 128, 3, 1),
conv_relu(128, 128, 3, 1),
nn.PaxPool2d(3, streide=2, padding=1) # 입력이미지 1/4
)- conv3
self.features3 = nn.Sequential(
conv_relu(128, 256, 3, 1),
conv_relu(256, 256, 3, 1),
conv_relu(256, 256, 3, 1),
nn.PaxPool2d(3, streide=2, padding=1) # 입력이미지 1/8
)- conv4
self.features4 = nn.Sequential(
conv_relu(256, 512, 3, 1),
conv_relu(512, 512, 3, 1),
conv_relu(512, 512, 3, 1),
nn.PaxPool2d(3, streide=1, padding=1) # 이미지 사이즈 고정
)- conv5
self.features5 = nn.Sequential(
conv_relu(512, 512, 3, rate=2),
conv_relu(512, 512, 3, rate=2),
conv_relu(512, 512, 3, rate=2),
nn.PaxPool2d(3, streide=1, padding=1),
nn.AvgPool2d(3, stride=1, padding=1) # 마지막 두 layer 크기 고정
)- FC6 ~ Score
self.classifier = nn.Sequential(
conv_relu(512, 1024, 3, rate=12),
nn.Dropout2d(0.5),
conv_relu(1204, 1024, 1, 1),
nn.Dropout2d(0.5),
nn.Conv2d(1024, num_classes, 1)
)- Up Sampling
Bi-linear Interpolation으로 크기 복원
class DeepLabV1(nn.Module):
def __init__(self, backbone, classifier, upsampling=8):
super(DeepLabV1, self).__init__()
self.bacbone = backbone
self.classifier = classifier
self.upsampling = upsampling
def forward(self, x):
x = self.backbone(x) # conv1~conv5
_, _, feature_map_h, feature_map_w = x.size()
x = self.classifier(x)
x= torch.nn.F.interpolate(x, size=(feature_map_h * self.upsampling, feature_map_w * self.upsampling), mode="bilinear")4) Bilinear Interpolation?
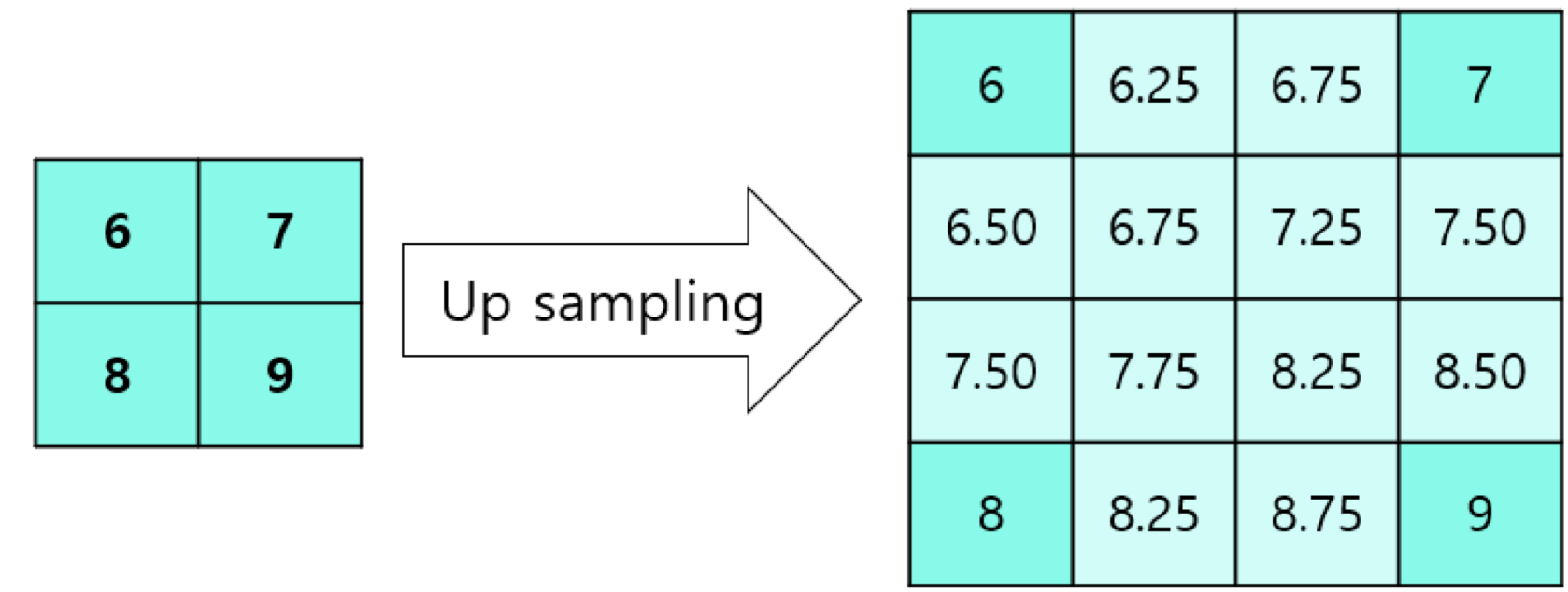
- 내분을 적용해 Up Sampling 하는 방법
- align_corners 옵션에 따라 결과가 달라질 수 있음
- Bilinear Interpolation은 픽셀 단위의 정교한 Segmentation 불가능
5) Dense CRF(Conditional Random Field)
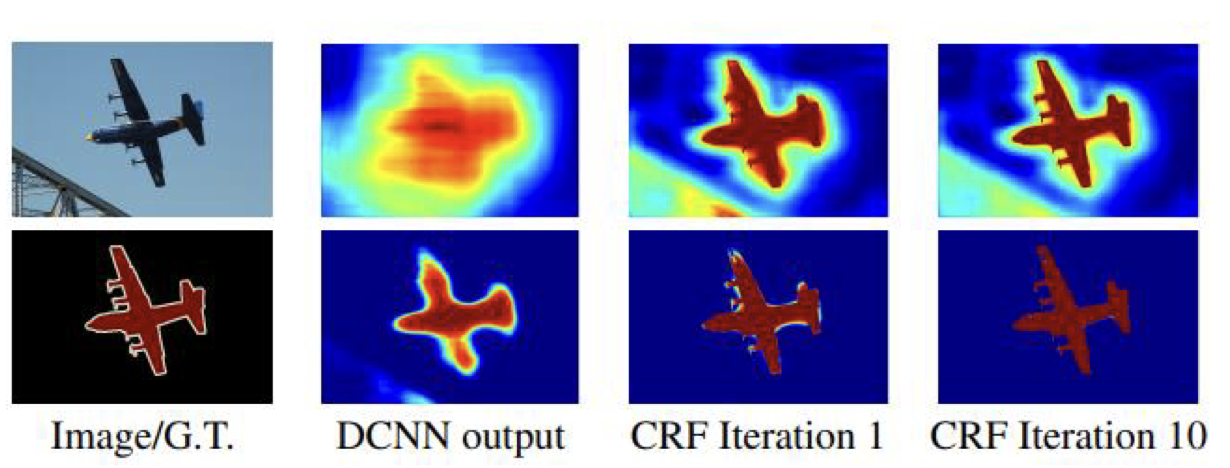
- Bilinear Interpolation으로는 픽셀 단위의 정교한 Segmentation이 불가능하기 때문에 적용하는 후처리 기법
- Segmentation을 수행한 뒤 계산될 확률 및 이미지를 CRF에 입력
색상이 유사한 픽셀이 가까이 위치하면 같은 범주
색상이 유사해도 픽셀의 거리가 멀다면 같은 범주에 속하지 않음 - 여러 번 반복해서 적용
- 각 픽셀 별 가장 높은 확률을 갖는 카테고리만 선택해 최종 결과 도출
6) DelatedNet?

-
conv4와 conv5의 MaxPool, AvgPool 제거
-
Bilinear Interpolation으로 Up Sampling 하지 않고 Deconvolution으로 원본 사이즈 복원
-
conv4
self.features4 = nn.Sequential(
conv_relu(256, 512, 3, 1),
conv_relu(512, 512, 3, 1),
conv_relu(512, 512, 3, 1),
)- conv5
self.features5 = nn.Sequential(
conv_relu(512, 512, 3, rate=2),
conv_relu(512, 512, 3, rate=2),
conv_relu(512, 512, 3, rate=2),
)- Up Sampling(Deconv)
class DilatedNetFron(nn.Module):
def __init__(self, backbone, classifier):
super(DilatedNetFront, self).__init__()
self.backbone = backbone
self.classifier = classifier
# deconv
self.deconv = nn.ConvTranspose2d(in_channels=11,
out_channels=11,
kernel_size=16,
stride=8,
padding=4)
def forward(self, x):
x = self.backbone(x)
x = self.classifier(x)
out = self.deconv(x)
return out7) DilatedNet(Front + Basic Context module)

- Up Sampling 전에 dilation을 다양하게 적용한 convolution Layer를 통과
- 다양한 크기의 Receptive Field로 정보 확보
class BasicContextModule(nn.Module):
def __init__(self, num_classes):
super(BasicContextModule, self).__init__()
self.layer1 = nn.Sequential(conv_relu(num_classes, num_classes, 3, 1))
self.layer2 = nn.Sequential(conv_relu(num_classes, num_classes, 3, 1))
self.layer3 = nn.Sequential(conv_relu(num_classes, num_classes, 3, 2))
self.layer4 = nn.Sequential(conv_relu(num_classes, num_classes, 3, 4))
self.layer5 = nn.Sequential(conv_relu(num_classes, num_classes, 3, 8))
self.layer6 = nn.Sequential(conv_relu(num_classes, num_classes, 3, 16))
self.layer7 = nn.Sequential(conv_relu(num_classes, num_classes, 3, 1))
self.layer8 = nn.Sequential(conv_relu(num_classes, num_classes, 3, 1))4. Implementation
5. Reference
https://arxiv.org/abs/1505.04366 ("Learning Deconvolution Network for Semantic Segmentation")
https://arxiv.org/abs/1611.09326 ("The One Hundred Layers Tiramisu: Fully Convolutional DenseNets for Semantic Segmentation")
https://arxiv.org/abs/1505.04597 ("U-Net: Convolutional Networks for Biomedical Image Segmentation")
https://arxiv.org/abs/1606.00915 ("DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs")

Boostcamper!