Segmentation
Recptive Field를 확장시킨 모델들
1. DeepLab v2
1) DeepLab v2?
- Backbone을 ResNet-101을 사용해 성능 향상
- Atrous Spatial Pyramid Pooling(ASPP) 적용해 다양한 크기의 Receptive field를 가진 정보 사용
2) Atrous Spatial Pyramid Pooling (ASPP)
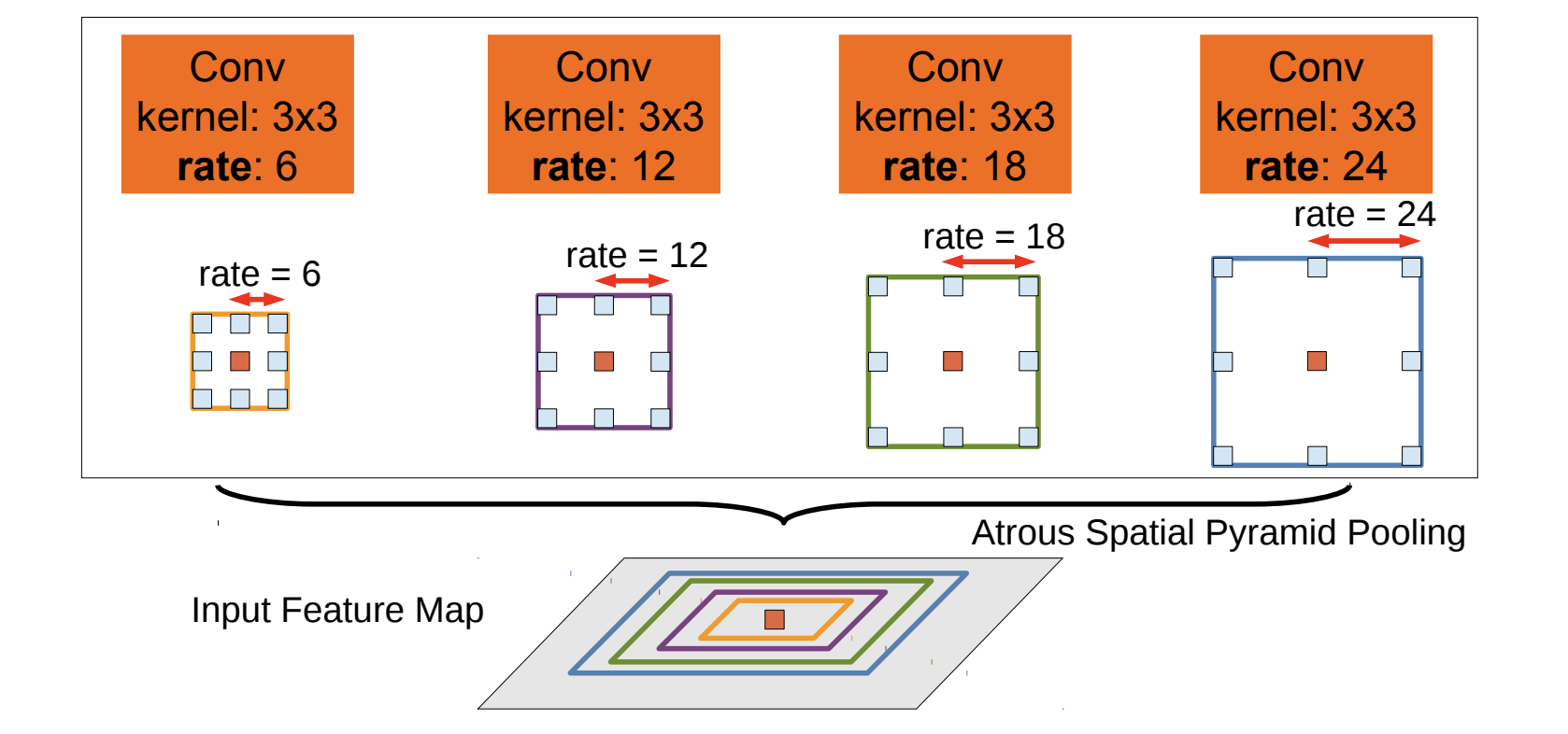
- Dilate rate의 크기를 여러개를 주어 다양한 Receptive Field를 확보해 특징을 추출
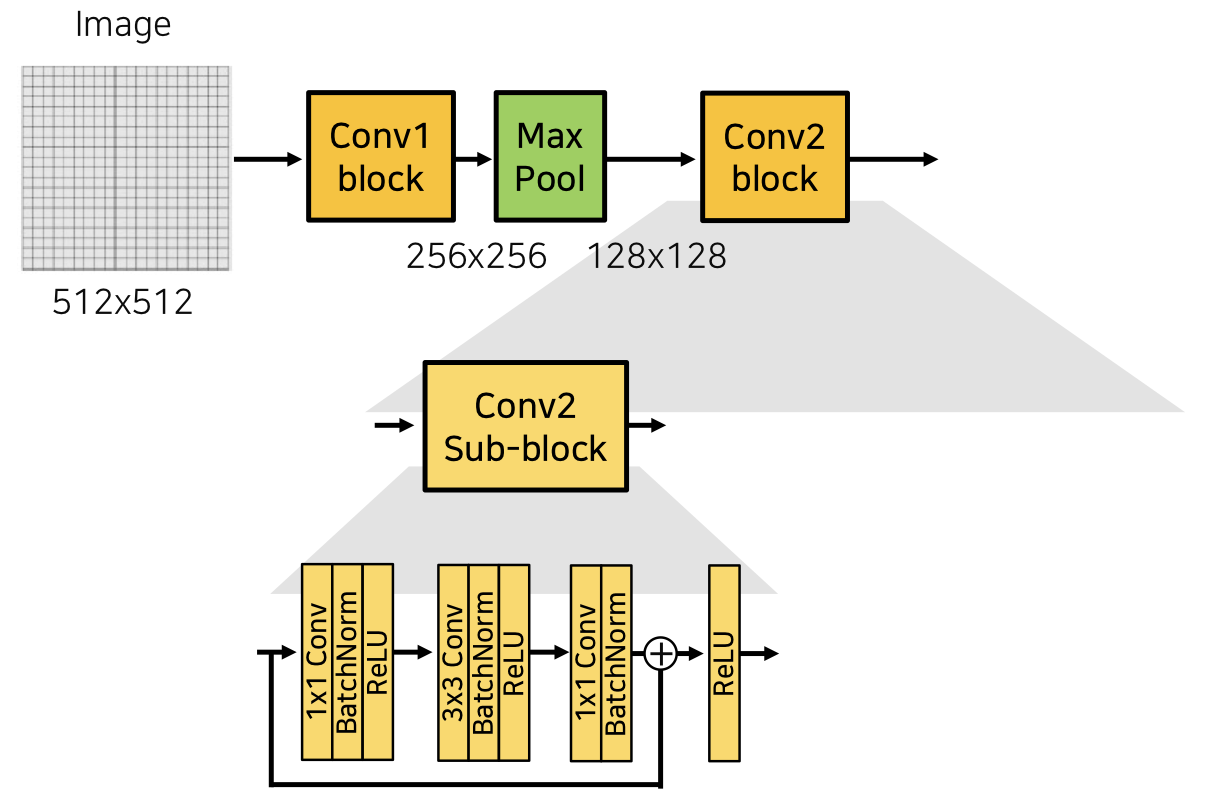
3) Architecture
- Back bone 에서 ResNet 구조를 사용 (Residual Block, Skip Connection)
conv1_block = nn.Sequential(
nn.Conv2d(3, 64, 7, 2, 3),
nn.BatchNorm2d(64),
nn.ReLU()
)
conv2_sub_block = nn.Sequential(
nn.Conv2d(64, 64, 1, 1, 0),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.Conv2d(64, 64, 3, 1, 1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.Conv2d(64, 256, 1, 1, 0),
nn.BatchNorm2d(256)
) # conv2_sub_block을 3회 반복
identity_block = nn.Sequential(
nn.Conv2d(64, 256, 1, 1, 0),
nn.BatchNorm2d(256)
)- 먼저 Conv1 block을 통과하면서 512 x 512 크기 이미지 feature map이 256 x 256 크기로 감소
- MaxPooling에 의해 128 x 128 크기로 feature map 크기 감소
- Conv2 block에는 Conv2-sub-block이 3개 반복
- Block에 입력으로 들어온 input과 Block을 통과한 결과를 sum (이 과정에서 채널이 맞지 않아 1x1 conv사용해 채널 맞춤)

2. PSPNet
1) PSPNet?
-
Mismatched Relationship: 주변 특징을 고려해서 예측 ex) 호수 주변 boat를 car로 예측하는 경우가 있음
-
Confusion Categories: Category간의 관계를 사용해서 혼돈 예측을 방지(Global contextual information 사용)
-
Inconspicuous Classes: 작은 객체들도 Global contextual information을 사용해서 더 잘 예측하도록 함
2) Pyramid Pooling Module
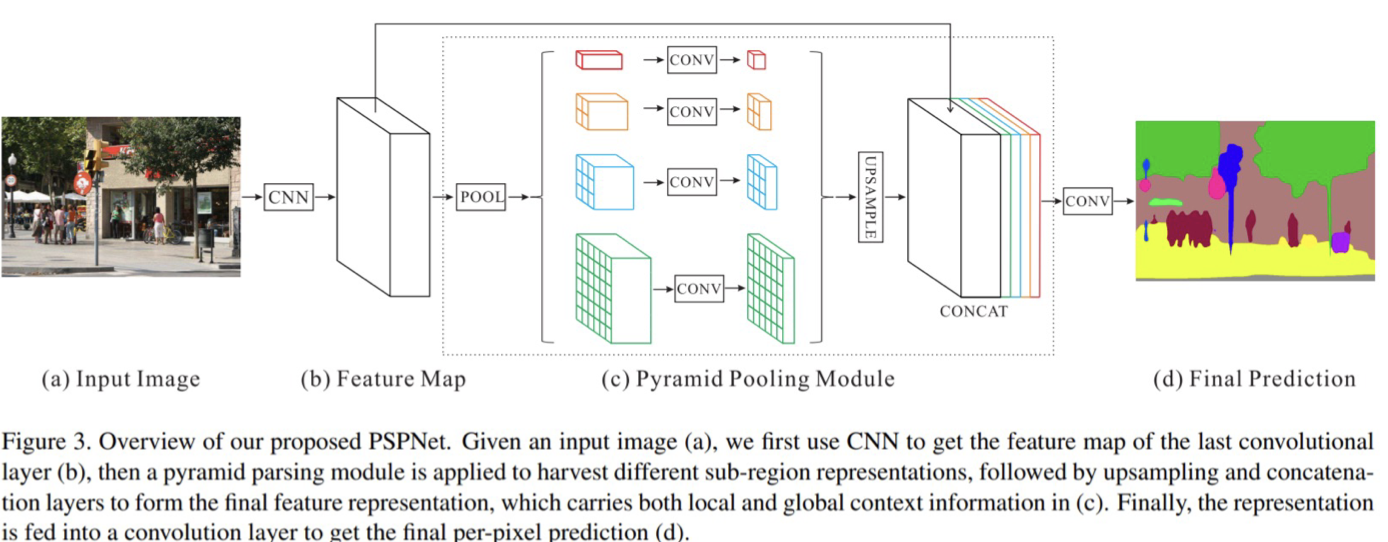
- 1x1, 2x2, 3x3, 6x6 Average Pooling을 적용해서 sub-region을 생성
- sub-region에 conv을 적용해서 채널이 1인 feature map을 생성 (크기를 맞춰 concat하기 위해)
- Feature map과 Pyramid Pooling Module의 결과를 concat해 사용함
- 주변 정보(문맥)을 파악해 객체를 예측하는데 사용
3. DeepLab v3
1) DeepLab v3?
- 다양한 크기의 Receptive field를 확보하기 위해 Atrous Spatial Pytamid Pooling 사용
2) Architecture
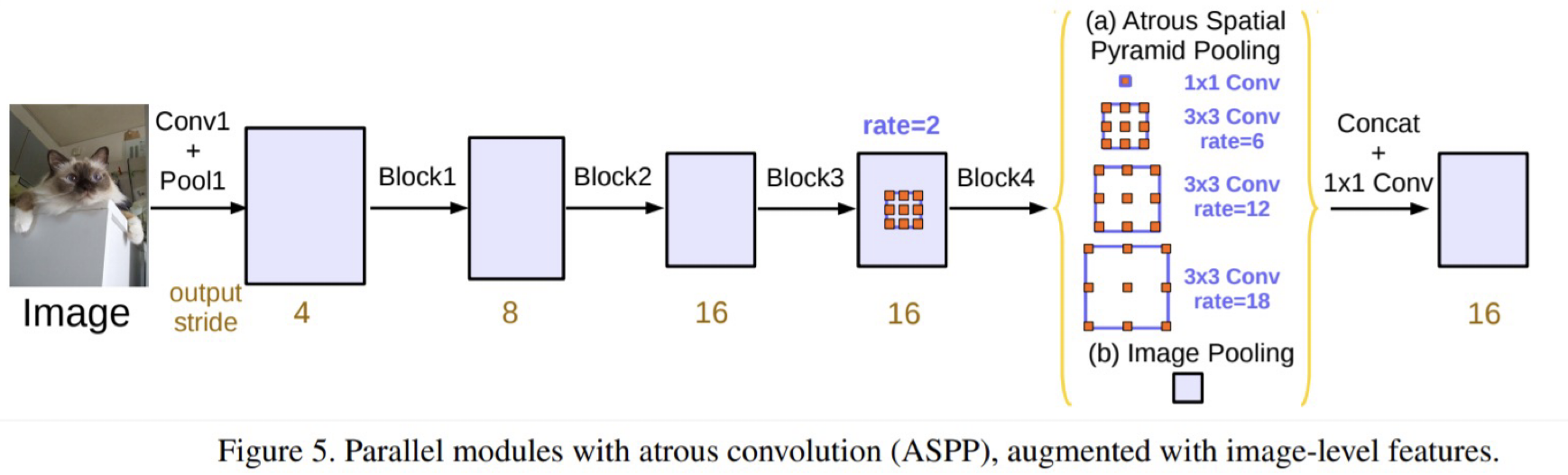
- 기존 DeepLab v2에서 사용한 ASPP에서 3x3(rate=24)를 제거하고 Global Average Pooling을 적용한 Image Pooling을 추가
- 1x1 크기 Image Pooling을 Bilinear interpolation을 적용해 upscaling
4. DeepLab v3+
1) DeepLab v3+?
- Encoder-Decoder 구조
- Encoder에서 축소로 인해 손실된 정보를 Decoder에서 복원
- DeepLab v3에서 ASPP를 적용한 구조 사용
- Xception을 Backbone으로 사용
2) Architecture
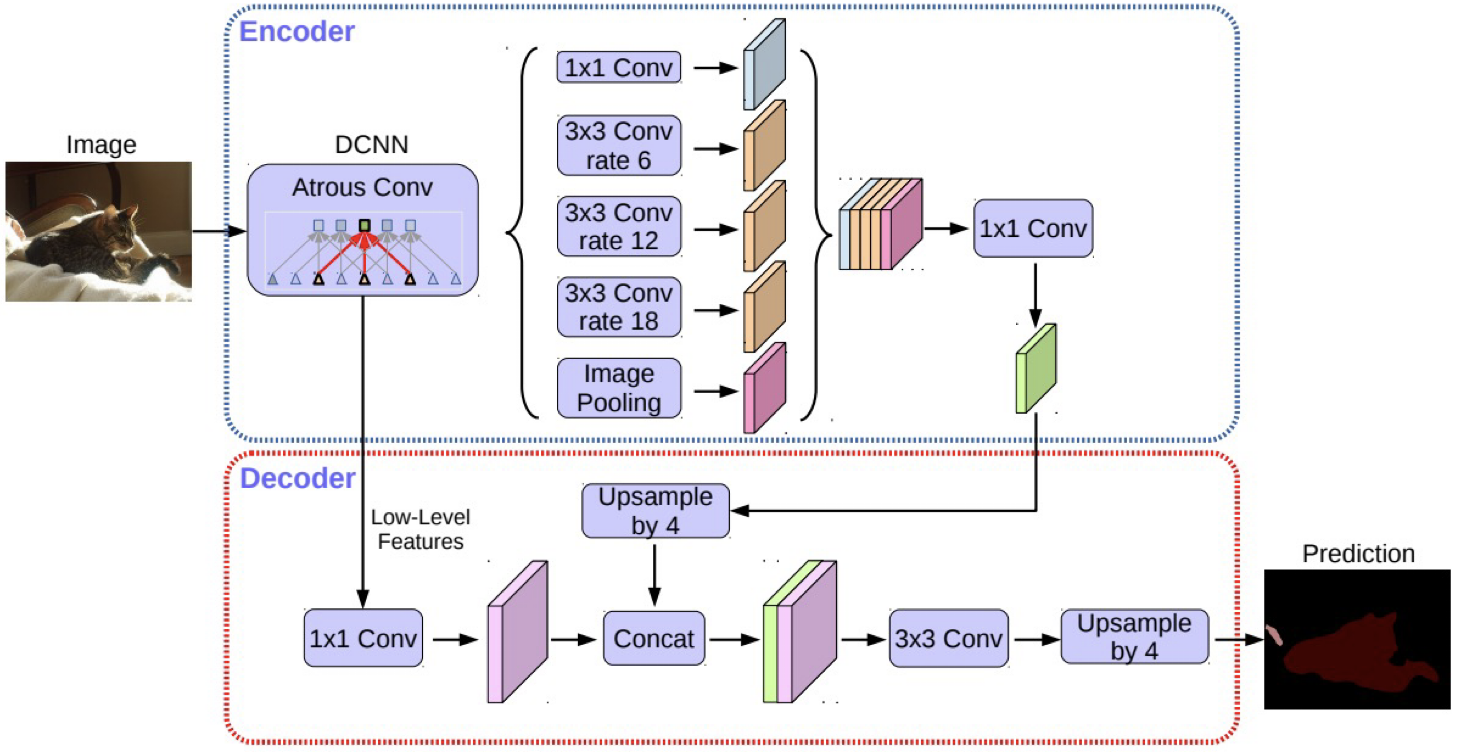
Encoder
- Encoder에서는 modified Xception을 backbone으로 사용
- ASPP 모듈 사용해 receptive field 확장
- Backbone의 low-level feature와 ASPP 출력을 Deocder에 전달
Decoder
- ASPP 모듈 출력을 bilinear(up-sampling)해 low-level feature와 결합
- 결합된 정보를 convolution, up-sampling해 최종 output 도출
- 단순한 up-sampling(bilinear interpolation) 연산을 개선해 detail 유지
3) Xception
- Depthwise Separable Convolution을 사용 (각 채널마다 다른 filter를 사용해 convolution 연산 후 결합)
- Depthwise + Pointwise = Depthwise Separable Convolution
- 두가지로 분리해 작헙하면 효율적인 연산이 가능함

nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, stride=1, groups=128)
# in_channels와 groups를 같게 (Depthwise Convolution)

nn.Conv2d(in_channels=256, out_channels=256, kernel_size=1, stride=1
# kernel_size가 1, (Pointwise Convolution)5. Implementation
6. Reference

Boostcamper!