강의내용
2-Stage Detectors
인공지능으로 객체를 인식하는 방법은 사람이 인지하는 방식과 비슷한 방식으로 설계되어 있다. 먼저 객체의 위치를 찾고 배경과 구분하여 물체를 맞추는 방식으로 객체를 인식하는데 인공지능도 마찬가지로 객체의 위치를 찾아내고 위치 안에 객체가 있다면 분류하는 방식으로 접근 할 수 있다.
R-CNN
객체의 위치를 찾기 위한 방법은 Region Proposal을 추출한다고 한다. R-CNN에서는 미리 지정된 크기의 window(직사각형 box)를 입력 이미지 위에서 sliding 하여 Region Proposal을 추출한다. 하지만 이러한 방식은 너무 많은 box를 생성하기 때문에 Selective Search 알고리즘을 사용해 이미지의 색깔, 질감 등으로 후보 영역(RoI; Region of Interest)을 추출하는 방식을 사용한다. 중요한 것은 Selective Search로 RoI를 추출하는 방식은 CPU에서 연산이 되기 때문에 R-CNN의 end-to-end에 대한 한계점으로 볼 수 있다.
R-CNN 구조
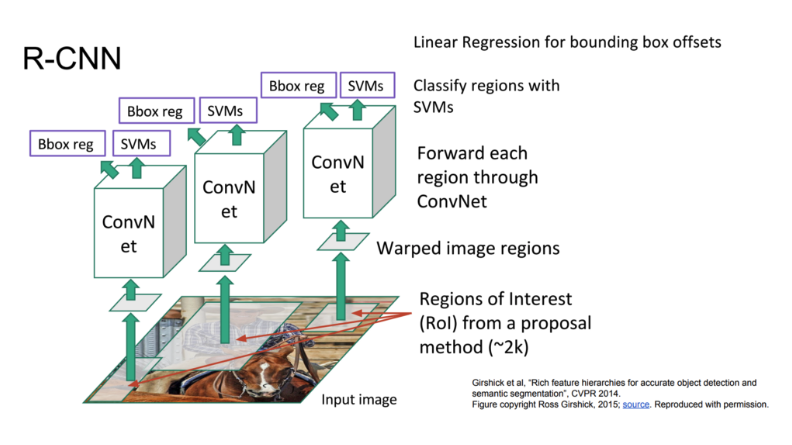
- Selective Search를 통해 RoI를 약 2000개 추출한다.
- 다양한 크기를 가진 RoI를 Convolution 연산으로 모두 동일한 사이즈로 변형한다 (Wraping) 동일하게 변형 시키는 이유는 마지막 FC layer의 입력사이즈를 변경할 수 없기 때문이다.
- 변형된 RoI를 AlexNet을 활용하여 통과시킨다.
- CNNs을 통해 나온 feature를 SVM에 넣어 분류한다.
- Output은 클래수의 개수 + 1(배경) + Confidence scores가 된다.
- Selective search 결과인 Bouding box의 위치를 보정할 필요가 있는데 Regression을 통해 bounding box를 예측한다.
R-CNN의 한계점
- 2000개의 RoI가 각각 CNN을 통과하게 되는데 이는 연산이 매우 많아 속도가 느린 한계가 있다.
- RoI의 크기를 모두 동일하게 해주기 위해 Warping하는 방법은 객체 정보가 손실되어 성능 하락으로 이어진다.
- CNN, Classifier, Bounding box Regressor 들을 각각 따로 학습한다.
- Selective search는 CPU에서 수행하는 연산으로 최종적인 end-to-end 모델이 아니다.
SPPNet
R-CNN에서 추출된 모든 RoI를 warping하고 각각 CNN을 통과시키는 한계를 극복한 모델이다. 아이디어는 input image를 먼저 conv layers를 통과시켜 고정된 feature를 얻고 RoI를 feature map으로 부터 얻은 다음 Spatial Pyramid Pooling Layer(SPP)를 통과시켜 warping 없이 고정된 크기를 획득하는 방법이다.
SPPNet 구조
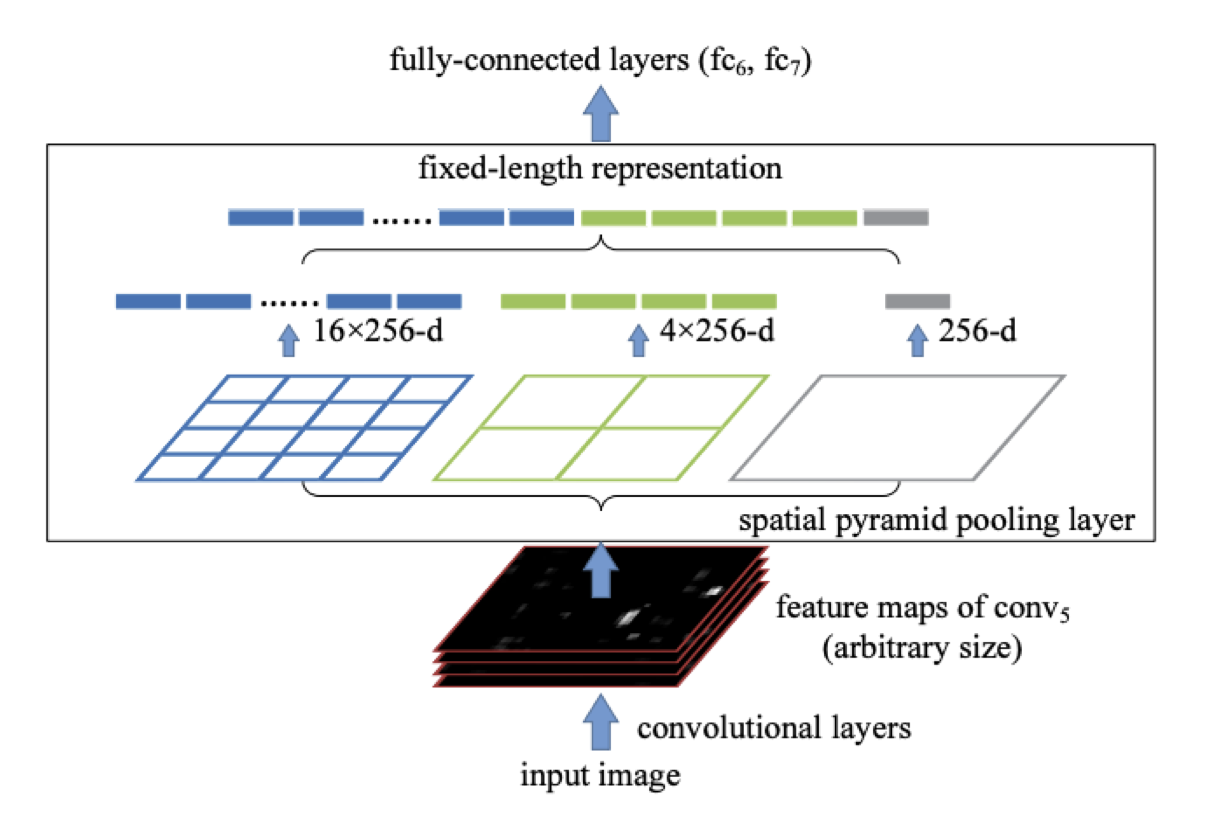
- input image를 conv layers를 통과시킨다.
- SPP layer를 통과시켜 고정된 크기의 flatten vector를 획득한다.
- SPP Layer에서는 서로 다르게 입력된 input을 target 크기로 맞추기 위해 bin을 사용한다. - FC layer를 통과시켜 나온 결과를 R-CNN과 마찬가지로 SVM, Box Regressor에 통과시킨다.
SPPNet의 한계점
- R-CNN에서 RoI를 각각 CNN을 통과시키지 않고 1번만 통과시켜 속도 향상이 되었고 SPP layer를 사용해 warping 하지 않아 정보 손실 없이 고정된 크기의 vector를 얻을 수 있지만 나머지 한계점이 여전히 존재한다.
Fast R-CNN
SPPNet의 Spatial Pyramid Pooling layer를 활용해 R-CNN의 한계를 극복한다. RoI pooling layer를 사용해 warping 하지 않고 고정된 크기의 vector를 얻는다.
Fast R-CNN 구조
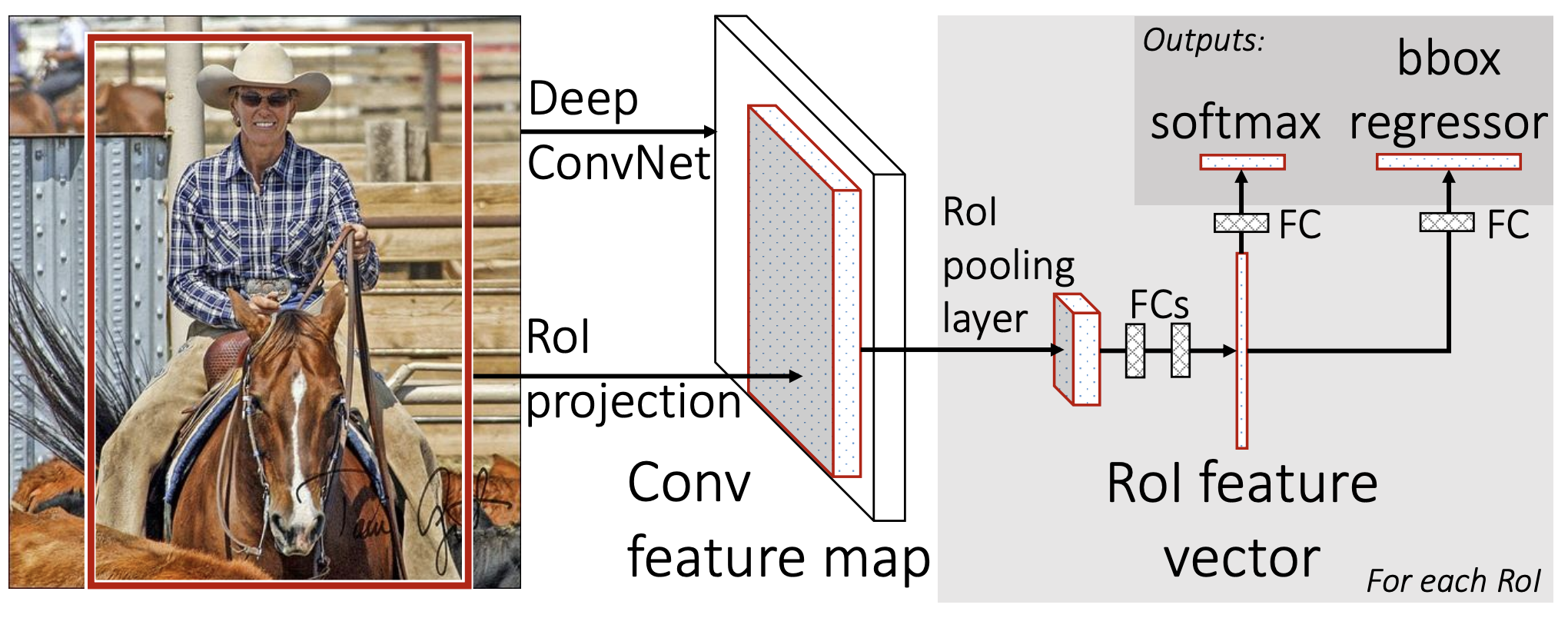
- 먼저 input image를 CNN 네트워크를 통과시킨다. 논문에서는 VGG-16 구조를 활용했다.
- 생성된 RoI를 추출된 feature map에 projection하고 RoI pooling layer를 통과시켜 warping하지 않고 고정된 크기의 vector를 얻는다
- FC Layer 이후 Softmax Classifier와 Bounding Box Regressor에 전달한다. (Classifier, BBox Regressor 학습 가능)
Fast R-CNN 한계점
- RoI 각각 CNN을 통과하는 구조 극복
- 강제 Warping으로 인한 성능 손실 극복
- CNN, Classifier, Bounding Box Regressor 각각 따로 학습해야하는 구조 극복
- 하지만 여전히 Selective Search는 CPU상에서 연산되기 때문에 학습이 불가능해 End-to-End 구조라고 할 수 없다.
Faster R-CNN
RoI를 생성하는 네트워크를 (RPN) 추가해 학습 가능하게 설계해 End-to-End를 완성하였다. 기존의 Selective Search를 대체하기 위해 Anchor box 개념을 사용하고 RPN을 통해 RoI를 계산한다.
Anchor box
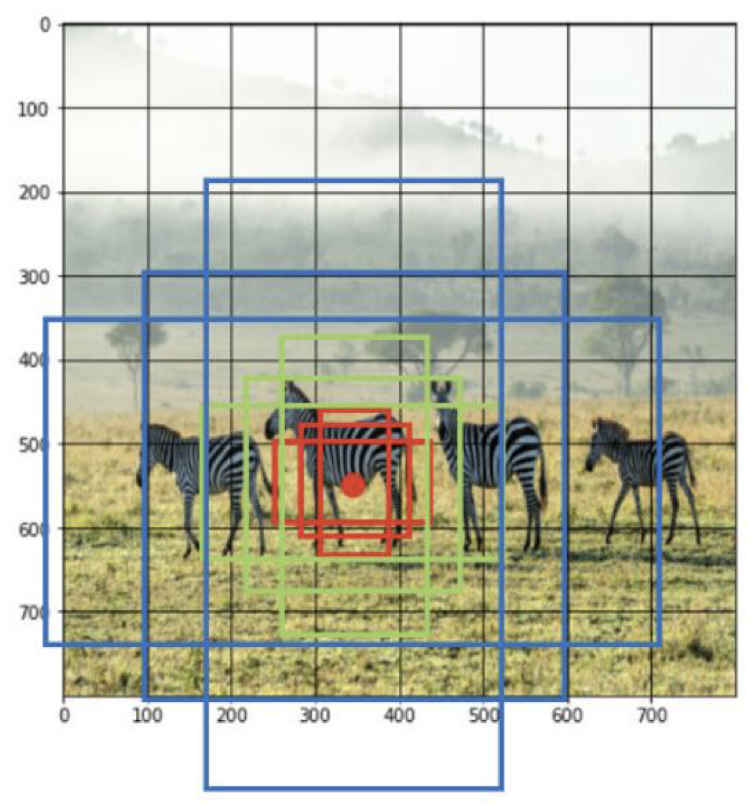
- CNN feature map을 cell 단위로 분할한다. 이때 다양한 크기로 설정한다.
- N개의 Anchor box를 미리 지정한다. (다양한 크기의 객체에 대응하기 위해)
- feature map의 각 cell 마다 N개의 anchor box 존재한다.
ex) 9개 anchor box, 64x64 cell => about 3,2000 anchor box
Anchor box를 이렇게 생성하면 오히려 R-CNN에서 사용한 2,000개의 RoI보다 많이 생성되는데 이를 선별하는 작업을 해야한다.
Anchor box가 객체를 포함하고 있는지 알아내고 좌표를 미세 조정해야한다.
RPN
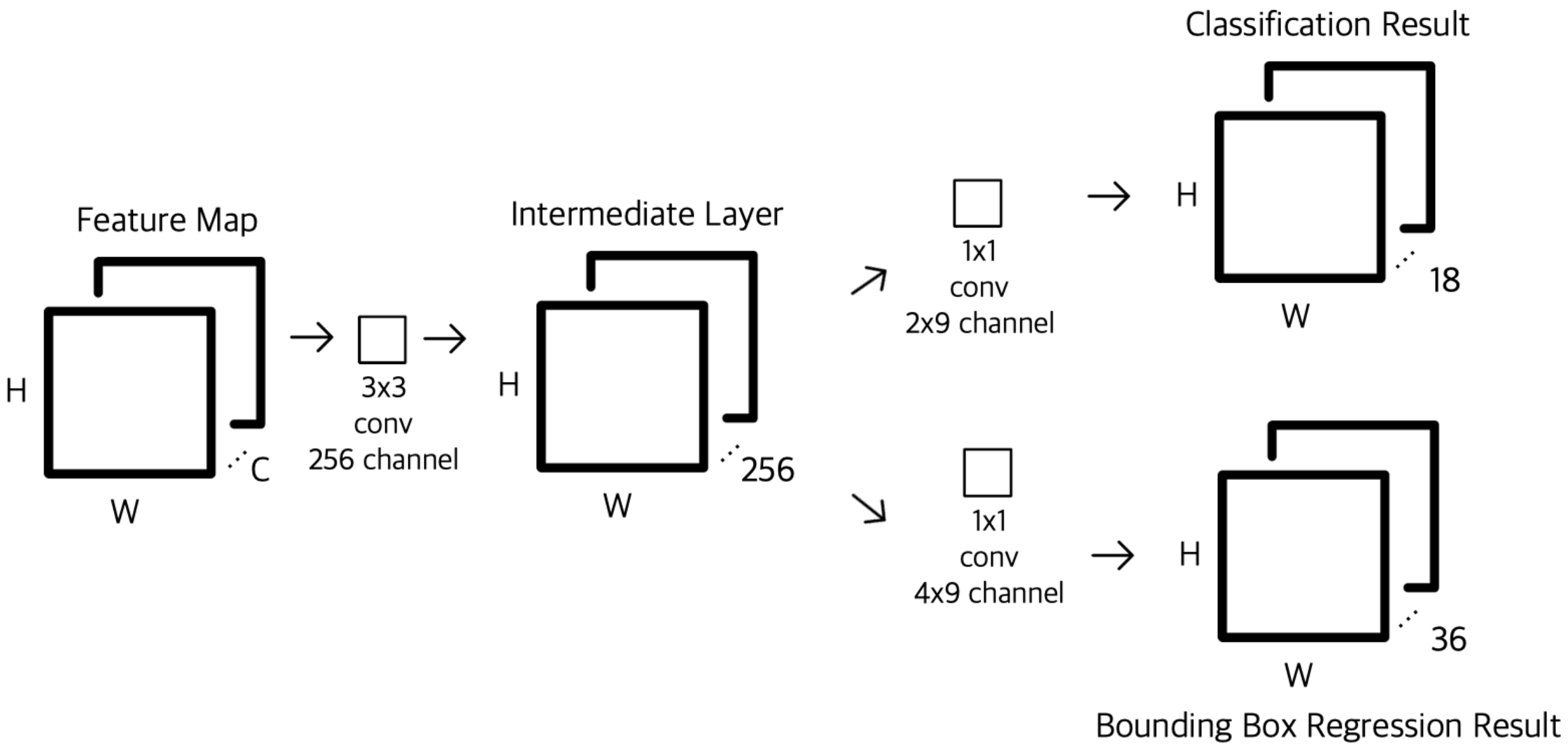
- CNN을 통과한 Feature Map을 고정된 channel로 맞춰주기 위해 Conv 연산을한다.
- 1x1 conv 2x9는 객체가 있는지 여부 (0, 1) x 미리 설정한 anchor box 개수(9)에 대한 정보를 갖고 있도록 한다.
- 1x1 conv 2x4는 box의 좌표 x,y와 box의 크기 widt, heigth x anchor box 개수(9)에 대한 정보를 갖고 있도록 한다.
NMS
- 유사한 RPN Proposals 제거하기 위해 사용한다.
- Class score를 기준으로 정렬한 뒤 IoU가 0.7 이상인 영역들은 중복된 영역으로 판단한 뒤 제거한다.
- 중복된 영역을 제거하여 RoI 수를 줄인다.
1-Stage Detectors
YOLO
Efficient Det
결과물
피어세션
학습내용
- 강의에서 배운 2-stage, 1-stage 모델들의 내용중에서 이해가 안되는 부분을 서로 공유하고 해결되지 않은 내용은 멘토님께 질문
- baseline 코드를 이해하기 위해 코드 리뷰
알고리즘
- 알고리즘 스터디를 위해서 책을 선정하고 과제를 선정해 github 팀 repo에 공유하고 주말에 코드리뷰 진행
- 이해되지 않는 알고리즘이나 문제 해결방법 등을 자유롭게 readme 파일에 작성하고 스터디 시간에 공유
리더보드
- 팀에서 가장 높은 점수를 달성한 모델을 공유하고 커스텀할 부분들을 논의
- 팀원들이 하고싶은 방향대로 커스텀하여 실험을 진행하고 ensemble 목표
학습회고
