
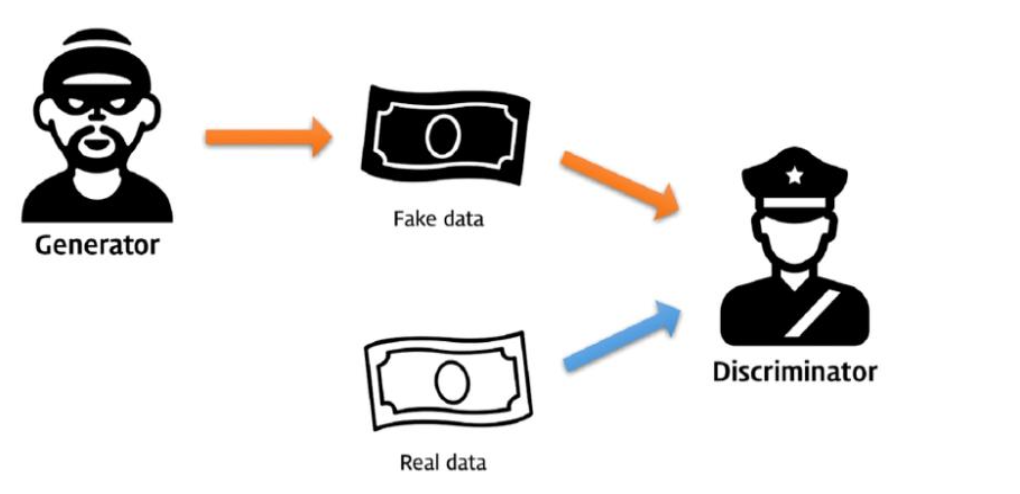
What is Gan?
- 적대적 생성 신경망(Generative Adversarial Networks)
- 두개의신경망모델이서로경쟁 => 더나은결과를만듦
- Generator(생성자) : 거짓 데이터 생성하는 모델
- Discriminator(감별자) : 실제 데이터와 거짓 데이터 구분하는 모델
- 경쟁으로인한두모델의성능↑
- How to train?
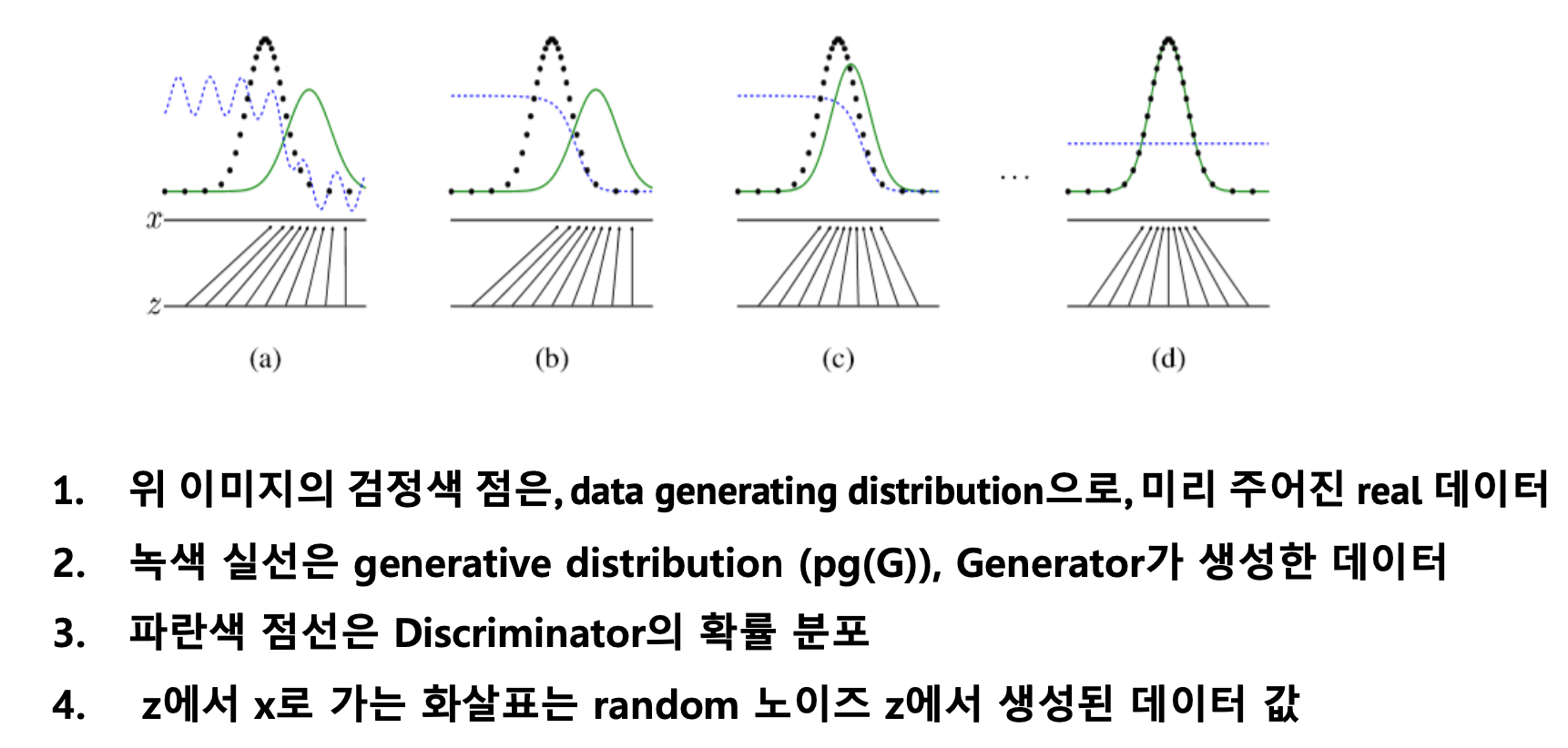
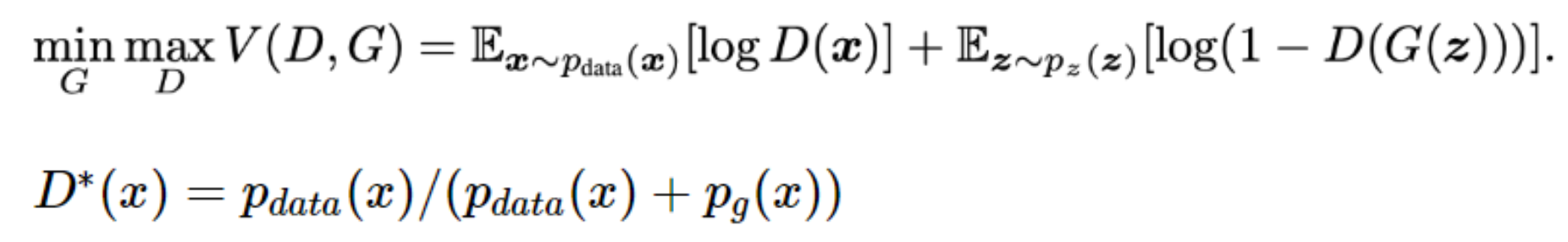
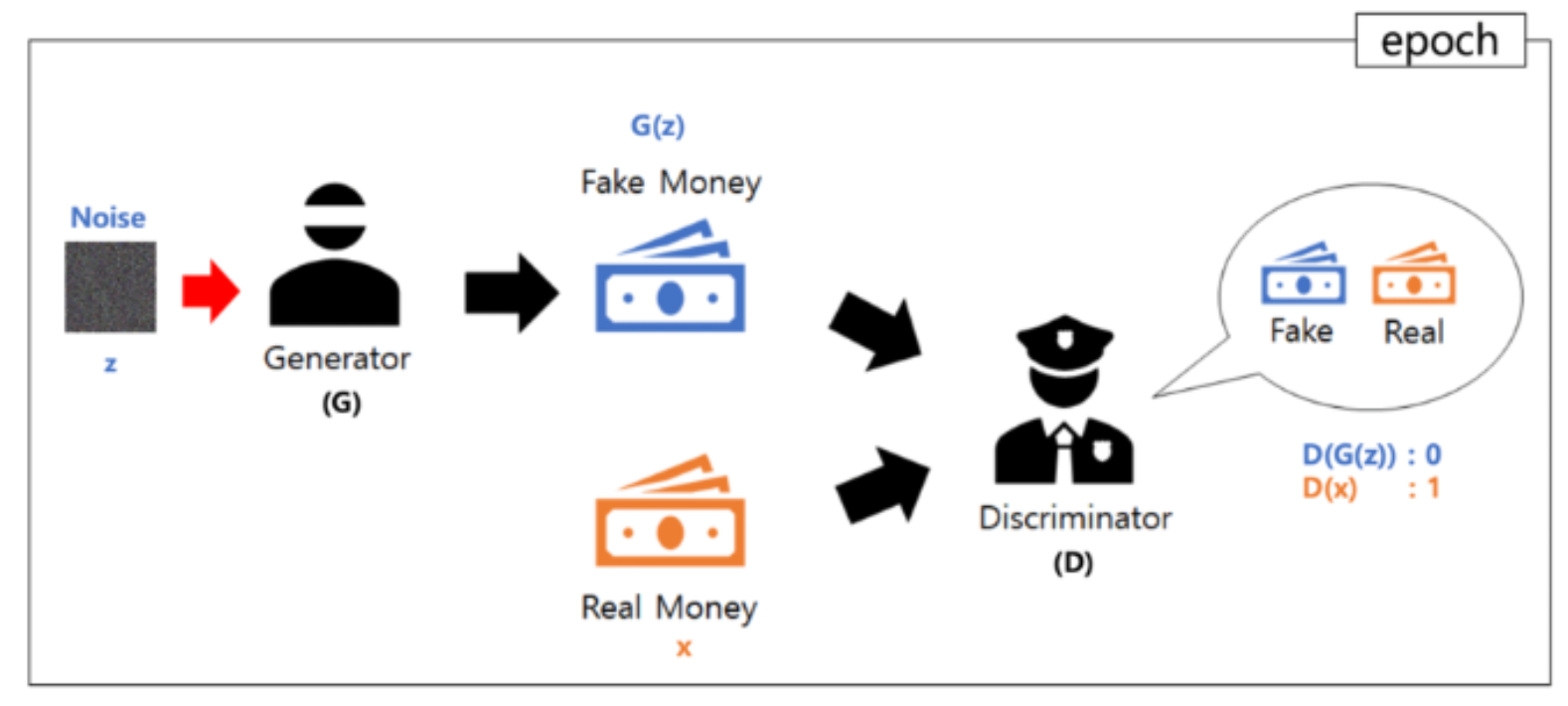
 ➡️ 모델이 생성한 확률분포가 실제 데이터의 분포와 동일해졌음 D(X) = 1/2 => 확률 50%(찍기)
➡️ 모델이 생성한 확률분포가 실제 데이터의 분포와 동일해졌음 D(X) = 1/2 => 확률 50%(찍기)
What is DCGAN?
- Deep Convolutional Generative Adversarial Network
- 기존 GAN에 컨볼루전망을 적용
Generator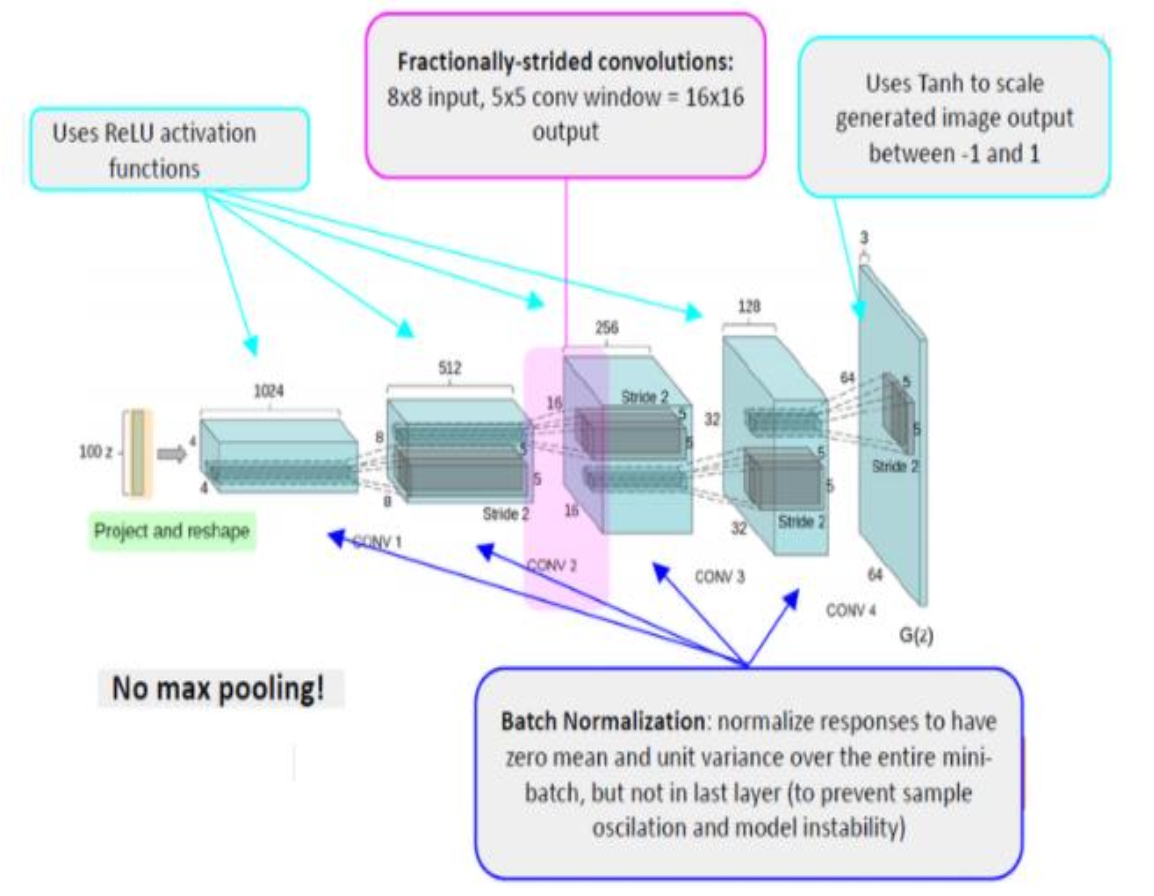
- Pooling layer 사용 x
- Unpooling 할 때, blocky한 이미지가 생성되기 때문
- Deconvolution 사용
- Stride 2이상을 사용해 feature map을 키움
- Batch normalization을 사용해서 학습의 안정성을 키움
- 마지막 출력에서 tanh 사용 -> 출력값을 [-1,1]로 조정하기 위함
Discriminator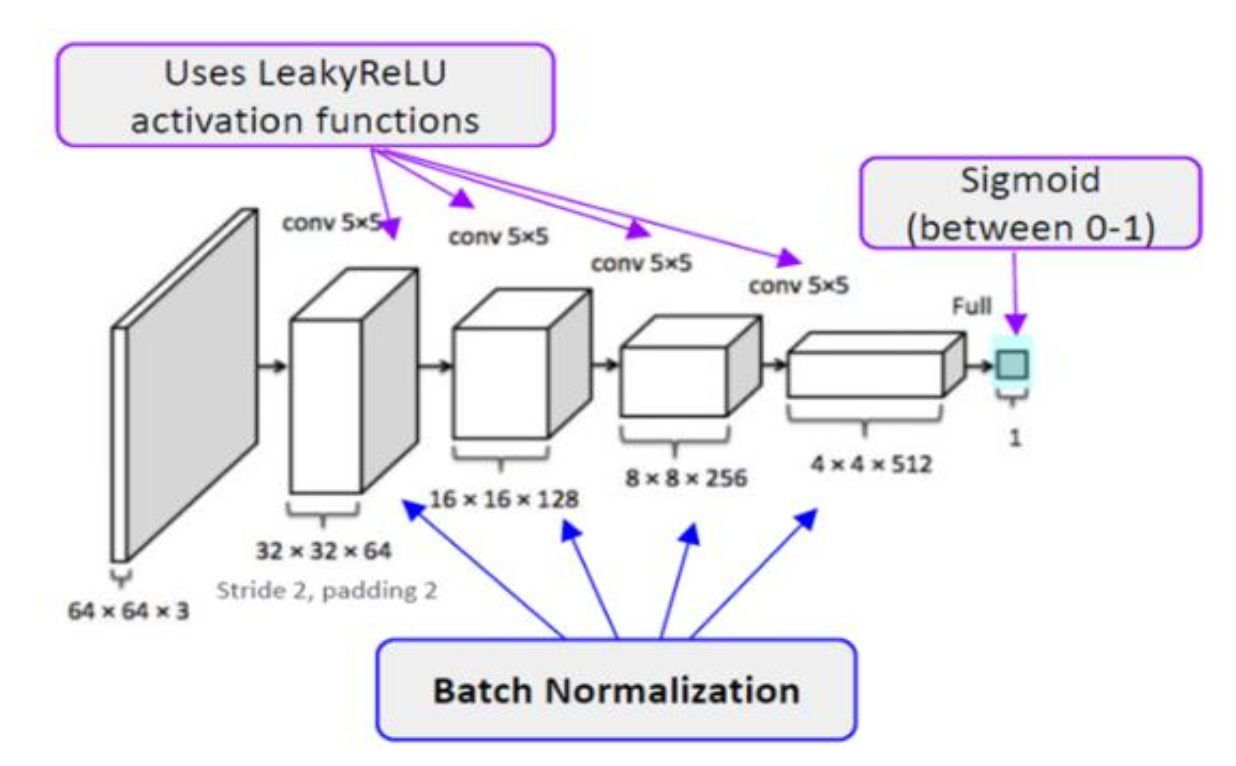
- 64x64x3 이미지입력
- Conv2D, BatchNorm2D, and LeakyRelu 통해 데이터 가공
- 마지막에 sigmoid함수를 이용해 0~1 사이의 확률값으로 조정
- Stride2 쓰는 이유 : 신경망내에서 스스로 풀링 함수를 학습하기 때문에, 데이터를 처리하는 과정에서 직접적으로 풀링 계층 (MaxPool, AvgPooling)사용하는 것보다 유리하다고 한다.
Code
Data
# 우리가 설정한 대로 이미지 데이터셋을 불러와 봅시다
# 먼저 데이터셋을 만듭니다
dataset = dset.ImageFolder(root=dataroot,
transform=transforms.Compose([
transforms.Resize(image_size),
transforms.CenterCrop(image_size),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
]))
# dataloader를 정의해봅시다
dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size,
shuffle=True, num_workers=workers)
# GPU 사용여부를 결정해 줍니다
device = torch.device("cuda:0" if (torch.cuda.is_available() and ngpu > 0) else "cpu")
# 학습 데이터들 중 몇가지 이미지들을 화면에 띄워봅시다
real_batch = next(iter(dataloader))
plt.figure(figsize=(8,8))
plt.axis("off")
plt.title("Training Images")
plt.imshow(np.transpose(vutils.make_grid(real_batch[0].to(device)[:64], padding=2, normalize=True).cpu(),(1,2,0)))
가중치 초기화
# ``netG`` 와 ``netD`` 에 적용시킬 커스텀 가중치 초기화 함수
def weights_init(m):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
nn.init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find('BatchNorm') != -1:
nn.init.normal_(m.weight.data, 1.0, 0.02)
nn.init.constant_(m.bias.data, 0)평균이 0이고 분산이 0.02인 정규분포를 사용해서 G와 D를 모두 무작위 초기화를 진행하는 것이 좋다
위 함수는 매개변수로 모델을 입력받아 가중치들을 모두 초기화 함. 모델이 만들어지자 마자 이 함수를 call 해서 적용을 시킴.
Generator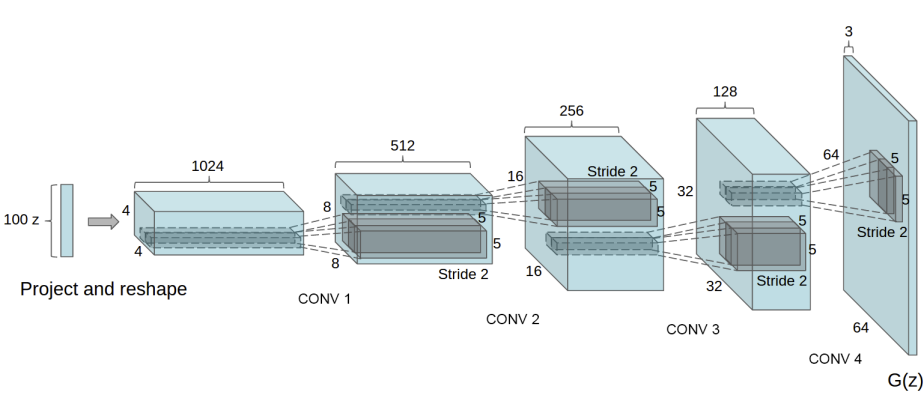
class Generator(nn.Module):
def __init__(self, ngpu):
super(Generator, self).__init__()
self.ngpu = ngpu
self.main = nn.Sequential(
# 입력데이터 Z가 가장 처음 통과하는 전치 합성곱 계층입니다.
nn.ConvTranspose2d( nz, ngf * 8, 4, 1, 0, bias=False),
nn.BatchNorm2d(ngf * 8),
nn.ReLU(True),
# 위의 계층을 통과한 데이터의 크기. ``(ngf*8) x 4 x 4``
nn.ConvTranspose2d(ngf * 8, ngf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 4),
nn.ReLU(True),
# 위의 계층을 통과한 데이터의 크기. ``(ngf*4) x 8 x 8``
nn.ConvTranspose2d( ngf * 4, ngf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 2),
nn.ReLU(True),
# 위의 계층을 통과한 데이터의 크기. ``(ngf*2) x 16 x 16``
nn.ConvTranspose2d( ngf * 2, ngf, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf),
nn.ReLU(True),
# 위의 계층을 통과한 데이터의 크기. ``(ngf) x 32 x 32``
nn.ConvTranspose2d( ngf, nc, 4, 2, 1, bias=False),
nn.Tanh()
# 위의 계층을 통과한 데이터의 크기. ``(nc) x 64 x 64``
)
def forward(self, input):
return self.main(input)
nz: 입력벡터 z의 길이
ngf: 생성자를 통과하는 특정 데이터의 크기
nc: 출력 이미지의 채널 개수 (코드에서는 RGB 이미지 이므로 nc = 3)
# 생성자를 만듭니다
netG = Generator(ngpu).to(device)
# 필요한 경우 multi-GPU를 설정 해주세요
if (device.type == 'cuda') and (ngpu > 1):
netG = nn.DataParallel(netG, list(range(ngpu)))
# 모든 가중치의 평균을 0( ``mean=0`` ), 분산을 0.02( ``stdev=0.02`` )로 초기화하기 위해
# ``weight_init`` 함수를 적용시킵니다
netG.apply(weights_init)
# 모델의 구조를 출력합니다
print(netG)생성자 모델의 인스턴스를 만들어 weights_init 함수를 적용

Discriminator
class Discriminator(nn.Module):
def __init__(self, ngpu):
super(Discriminator, self).__init__()
self.ngpu = ngpu
self.main = nn.Sequential(
# 입력 데이터의 크기는 ``(nc) x 64 x 64`` 입니다
nn.Conv2d(nc, ndf, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
# 위의 계층을 통과한 데이터의 크기. ``(ndf) x 32 x 32``
nn.Conv2d(ndf, ndf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 2),
nn.LeakyReLU(0.2, inplace=True),
# 위의 계층을 통과한 데이터의 크기. ``(ndf*2) x 16 x 16``
nn.Conv2d(ndf * 2, ndf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 4),
nn.LeakyReLU(0.2, inplace=True),
# 위의 계층을 통과한 데이터의 크기. ``(ndf*4) x 8 x 8``
nn.Conv2d(ndf * 4, ndf * 8, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 8),
nn.LeakyReLU(0.2, inplace=True),
# 위의 계층을 통과한 데이터의 크기. ``(ndf*8) x 4 x 4``
nn.Conv2d(ndf * 8, 1, 4, 1, 0, bias=False),
nn.Sigmoid()
)
def forward(self, input):
return self.main(input)Discriminator가 필요한 경우, 더 다양한 layer들을 쌓을 수 있지만, Batch Normalization, LeaklyReLU, strided 합성곱 계층을 사용함
Why? => DCGAN 논문에서 보폭이 있는(Strided) 합성곱 계층을 사용 하는 것이 신경망 내에서 스스로 Pooling 함수를 학습하기 때문에, 직접적으로 Pooling 계층(MaxPool, AvgPooling)을 사용하는 것 보다 좋음
# 구분자를 만듭니다
netD = Discriminator(ngpu).to(device)
# 필요한 경우 multi-GPU를 설정 해주세요
if (device.type == 'cuda') and (ngpu > 1):
netD = nn.DataParallel(netD, list(range(ngpu)))
# 모든 가중치의 평균을 0( ``mean=0`` ), 분산을 0.02( ``stdev=0.02`` )로 초기화하기 위해
# ``weight_init`` 함수를 적용시킵니다
netD.apply(weights_init)
# 모델의 구조를 출력합니다
print(netD)
Loss function과 Optimizer 정의
# ``BCELoss`` 함수의 인스턴스를 초기화합니다
criterion = nn.BCELoss()
# 생성자의 학습상태를 확인할 잠재 공간 벡터를 생성합니다
fixed_noise = torch.randn(64, nz, 1, 1, device=device)
# 학습에 사용되는 참/거짓의 라벨을 정합니다
real_label = 1.
fake_label = 0.
# G와 D에서 사용할 Adam옵티마이저를 생성합니다
optimizerD = optim.Adam(netD.parameters(), lr=lr, betas=(beta1, 0.999))
optimizerG = optim.Adam(netG.parameters(), lr=lr, betas=(beta1, 0.999))Pytorch에서는 손실함수를 Binary Cross Entropy Loss (BCELoss) 사용 손실함수는 위에서 설명한 함수와 비슷
- Discriminator 손실함수
- ( 1 ) y가 1일 경우(real data일 경우), Xn에 실제 데이터를 넣어준다. (y = 1, Xn = D(X))
- ( 2 ) y가 0일 경우(fake data일 경우), Xn에 새로 생성한 데이터를 넣어준다. (y= 0, Xn = D(G(Z)))
- 위 ( 1 ), ( 2 )를 각각 ln에 넣어주면,
( 1 ) -logD(X)
( 2 ) –log(1-D(G(Z)))
이 둘을 더한 –logD(X)–log(1-D(G(Z))) 를 최소화 시켜야함 ↔️ logD(X)+log(1-D(G(Z))) 를 최대화 시키면 됨!!
- Generator 손실 함수
- Original GAN: 생성자는 log(1-D(G(Z)))를 최소화 시키는 방향으로 학습시킴
- But, 충분한 변화 x, 학습초기에 문제가 생겨 이를 해결하기 위해 log(D(G(Z)))를 최대화 하는 방식으로 학습한다.
- log(D(G(Z)))를 최대화하는 것은 D(G(Z)) 값을 최대로 하는 것과 동일한 의미이며, 이는 Discriminator가 생성된 이미지를 "진짜로 판별하도 록 속이는" 것을 의미합니다.
Training
# 학습상태를 체크하기 위해 손실값들을 저장합니다
img_list = []
G_losses = []
D_losses = []
iters = 0
print("Starting Training Loop...")
# 에폭(epoch) 반복
for epoch in range(num_epochs):
# 한 에폭 내에서 배치 반복
for i, data in enumerate(dataloader, 0):
############################
# (1) D 신경망을 업데이트 합니다: log(D(x)) + log(1 - D(G(z)))를 최대화 합니다
###########################
## 진짜 데이터들로 학습을 합니다
netD.zero_grad()
# 배치들의 사이즈나 사용할 디바이스에 맞게 조정합니다
real_cpu = data[0].to(device)
b_size = real_cpu.size(0)
label = torch.full((b_size,), real_label,
dtype=torch.float, device=device)
# 진짜 데이터들로 이루어진 배치를 D에 통과시킵니다
output = netD(real_cpu).view(-1)
# 손실값을 구합니다
errD_real = criterion(output, label)
# 역전파의 과정에서 변화도를 계산합니다
errD_real.backward()
D_x = output.mean().item()
## 가짜 데이터들로 학습을 합니다
# 생성자에 사용할 잠재공간 벡터를 생성합니다
noise = torch.randn(b_size, nz, 1, 1, device=device)
# G를 이용해 가짜 이미지를 생성합니다
fake = netG(noise)
label.fill_(fake_label)
# D를 이용해 데이터의 진위를 판별합니다
output = netD(fake.detach()).view(-1)
# D의 손실값을 계산합니다
errD_fake = criterion(output, label)
# 역전파를 통해 변화도를 계산합니다. 이때 앞서 구한 변화도에 더합니다(accumulate)
errD_fake.backward()
D_G_z1 = output.mean().item()
# 가짜 이미지와 진짜 이미지 모두에서 구한 손실값들을 더합니다
# 이때 errD는 역전파에서 사용되지 않고, 이후 학습 상태를 리포팅(reporting)할 때 사용합니다
errD = errD_real + errD_fake
# D를 업데이트 합니다
optimizerD.step()
############################
# (2) G 신경망을 업데이트 합니다: log(D(G(z)))를 최대화 합니다
###########################
netG.zero_grad()
label.fill_(real_label) # 생성자의 손실값을 구하기 위해 진짜 라벨을 이용할 겁니다
# 우리는 방금 D를 업데이트했기 때문에, D에 다시 가짜 데이터를 통과시킵니다.
# 이때 G는 업데이트되지 않았지만, D가 업데이트 되었기 때문에 앞선 손실값가 다른 값이 나오게 됩니다
output = netD(fake).view(-1)
# G의 손실값을 구합니다
errG = criterion(output, label)
# G의 변화도를 계산합니다
errG.backward()
D_G_z2 = output.mean().item()
# G를 업데이트 합니다
optimizerG.step()
# 훈련 상태를 출력합니다
if i % 50 == 0:
print('[%d/%d][%d/%d]\tLoss_D: %.4f\tLoss_G: %.4f\tD(x): %.4f\tD(G(z)): %.4f / %.4f'
% (epoch, num_epochs, i, len(dataloader),
errD.item(), errG.item(), D_x, D_G_z1, D_G_z2))
# 이후 그래프를 그리기 위해 손실값들을 저장해둡니다
G_losses.append(errG.item())
D_losses.append(errD.item())
# fixed_noise를 통과시킨 G의 출력값을 저장해둡니다
if (iters % 500 == 0) or ((epoch == num_epochs-1) and (i == len(dataloader)-1)):
with torch.no_grad():
fake = netG(fixed_noise).detach().cpu()
img_list.append(vutils.make_grid(fake, padding=2, normalize=True))
iters += 1Part 1) Discriminator의 학습
1) 진짜 데이터들로만 이루어진 배치를 만들어 D에 통 과시킨다.
- 출력값으로 log(D(x))의 손실값을 계산
- backpropagation 고정에서의 변화도를 계산
2) 가짜 데이터들로만 이루어진 배치를 만들어 D에 통 과시킨다.
- 그 출력값으로 log(1-D(G(z)))의 손실값 계산
- backprobagation 변화도 계산
이때, 두 가지 스텝에서 나오는 변화도들을 축적시켜야한다.
- backpropagation 계산했으니, 옵티마이저 사용해서 backpropagation 적용
Part 2) Generator의 학습
D를 이용해 G의 출력값을 판별해주고, 진짜 라벨값을 이용해 G의 손실값을 구한다.
(즉, G로 생성한 데이터를 판별자에 넣어서 판별해서 나온 값을 진짜 라벨값을 이용해서 loss 계산해준다.)구한 손실값으로 변화도를 구하고, 최종적으로는 옵티마이저를 이용해 G의 가중치들을 업데이트 시켜준다.
Result
plt.figure(figsize=(10,5))
plt.title("Generator and Discriminator Loss During Training")
plt.plot(G_losses,label="G")
plt.plot(D_losses,label="D")
plt.xlabel("iterations")
plt.ylabel("Loss")
plt.legend()
plt.show()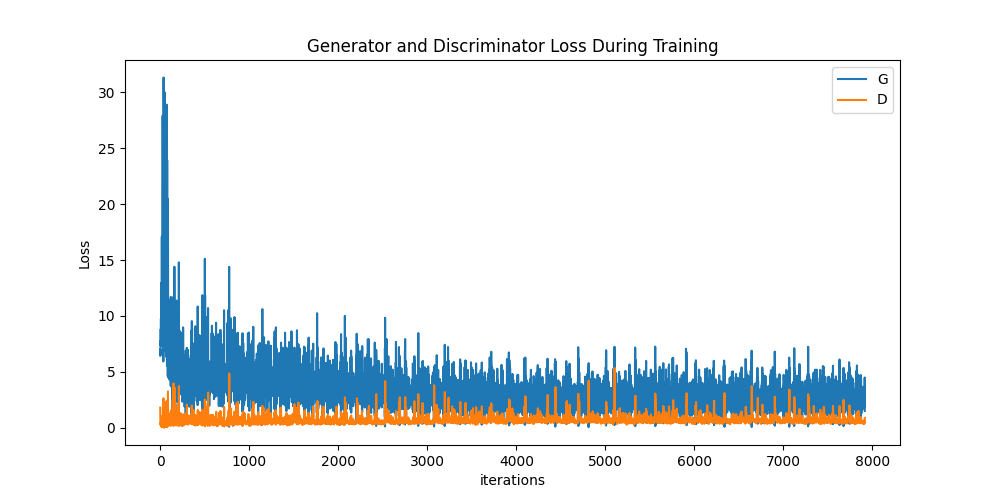
손실값 그래프로 나타내기
fig = plt.figure(figsize=(8,8))
plt.axis("off")
ims = [[plt.imshow(np.transpose(i,(1,2,0)), animated=True)] for i in img_list]
ani = animation.ArtistAnimation(fig, ims, interval=1000, repeat_delay=1000, blit=True)
HTML(ani.to_jshtml())
Real vs. Fake
출처 : PyTorch Tutorials https://pytorch.org/tutorials/beginner/dcgan_faces_tutorial.html
