
Defining the Dataset
torch.utils.data.Dataset class 상속
__len__( : 데이터셋의 샘플 개수) 와
__getitem__( : 데이터셋에서 하나의 샘플을 가져온 후 각 mask 의 bounding box의 좌표 및 정보들의 dictionar) 메소드를 구현해 주어야 한다.
__getitem__ 메소드가 다음을 반환 해야한다:
- 이미지 : PIL(Python Image Library) 이미지의 크기 (H, W)
- 대상: 다음의 필드를 포함하는 사전 타입
boxes (FloatTensor[N, 4]): N개의 Bounding box의 좌표, target 위치를 특정하기 위해 사용labels (Int64Tensor[N]): Bounding box마다의 라벨 정보, 0=배경image_id (Int64Tensor[1]): 각 이미지 고유값 (구분자)area (Tensor[N]): Bounding box 면적iscrowd (UInt8Tensor[N]): true면 평가에서 제외(다른 객체와 겹쳐있거나 밀집된 경우)(optional) masks (UInt8Tensor[N, H, W])(optional) keypoints (FloatTensor[N, K, 3])
labels 에 대한 참고사항. 이 모델은 클래스 0 을 배경으로 취급합니다. 만약 준비한 데이터셋에 배경의 클래스가 없다면, labels 에도 0 이 없어야 합니다. 예를 들어, 고양이 와 강아지 의 오직 2개의 클래스만 분류한다고 가정하면, (0 이 아닌) 1 이 고양이 를, 2 가 강아지 를 나타내도록 정의해야 합니다. 따라서, 이 예시에서, 어떤 이미지에 두 개의 클래스를 모두 있다면, labels 텐서는 [1,2] 와 같은 식이 되어야 합니다.
추가로, 학습 중에 가로 세로 비율 그룹화를 사용하려는 경우(각 배치에 유사한 가로 세로 비율이 있는 영상만 포함되도록), 이미지의 넓이, 높이를 리턴할 수 있도록 get_height_and_width 메소드를 구현하기를 추천합니다. 이 메소드가 구현되지 않은 경우에는 모든 데이터셋은 __getitem__ 를 통해 메모리에 이미지가 로드되며 사용자 정의 메소드를 제공하는 것보다 느릴 수 있습니다.
PennFudan를 위한 사용자 정의 데이터셋 작성하기
다운로드 후 압축 파일을 해제하면 다음의 폴더 구조를 볼 수 있습니다:
PennFudanPed/
PedMasks/
FudanPed00001_mask.png
FudanPed00002_mask.png
FudanPed00003_mask.png
FudanPed00004_mask.png
...
PNGImages/
FudanPed00001.png
FudanPed00002.png
FudanPed00003.png
FudanPed00004.png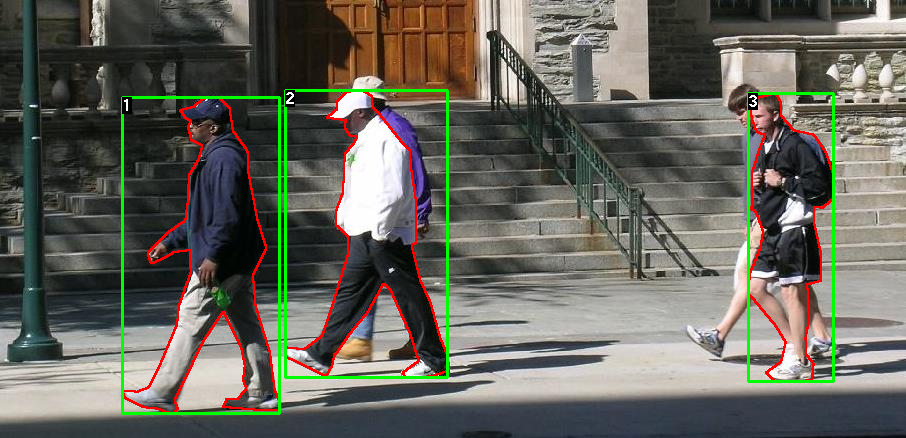

한 쌍의 영상과 분할 마스크의 한 가지 예:
각 이미지에는 해당하는 분할 마스크가 있으며, 여기서 각각의 색상은 다른 인스턴스에 해당합니다.
import os
import numpy as np
import torch
from PIL import Image
class PennFudanDataset(torch.utils.data.Dataset):
def __init__(self, root, transforms):
self.root = root
self.transforms = transforms
# 모든 이미지 파일들을 읽고, 정렬하여
# 이미지와 분할 마스크 정렬을 확인합니다
self.imgs = list(sorted(os.listdir(os.path.join(root, "PNGImages"))))
self.masks = list(sorted(os.listdir(os.path.join(root, "PedMasks"))))
def __getitem__(self, idx):
# 이미지와 마스크를 읽어옵니다
img_path = os.path.join(self.root, "PNGImages", self.imgs[idx])
mask_path = os.path.join(self.root, "PedMasks", self.masks[idx])
img = Image.open(img_path).convert("RGB")
# 분할 마스크는 RGB로 변환하지 않음을 유의하세요
# 왜냐하면 각 색상은 다른 인스턴스에 해당하며, 0은 배경에 해당합니다
mask = Image.open(mask_path)
# numpy 배열을 PIL 이미지로 변환합니다
mask = np.array(mask)
# 인스턴스들은 다른 색들로 인코딩 되어 있습니다.
obj_ids = np.unique(mask)
# 첫번째 id 는 배경이라 제거합니다
obj_ids = obj_ids[1:]
# 컬러 인코딩된 마스크를 바이너리 마스크 세트로 나눕니다
masks = mask == obj_ids[:, None, None]
# 각 마스크의 바운딩 박스 좌표를 얻습니다
num_objs = len(obj_ids)
boxes = []
for i in range(num_objs):
pos = np.where(masks[i])
xmin = np.min(pos[1])
xmax = np.max(pos[1])
ymin = np.min(pos[0])
ymax = np.max(pos[0])
boxes.append([xmin, ymin, xmax, ymax])
# 모든 것을 torch.Tensor 타입으로 변환합니다
boxes = torch.as_tensor(boxes, dtype=torch.float32)
# 객체 종류는 한 종류만 존재합니다(역자주: 예제에서는 사람만이 대상입니다)
labels = torch.ones((num_objs,), dtype=torch.int64)
masks = torch.as_tensor(masks, dtype=torch.uint8)
image_id = torch.tensor([idx])
area = (boxes[:, 3] - boxes[:, 1]) * (boxes[:, 2] - boxes[:, 0])
# 모든 인스턴스는 군중(crowd) 상태가 아님을 가정합니다
iscrowd = torch.zeros((num_objs,), dtype=torch.int64)
target = {}
target["boxes"] = boxes
target["labels"] = labels
target["masks"] = masks
target["image_id"] = image_id
target["area"] = area
target["iscrowd"] = iscrowd
if self.transforms is not None:
img, target = self.transforms(img, target)
return img, target
def __len__(self):
return len(self.imgs)데이터셋에 해당하는
torch.utils.data.Dataset클래스
Defining model
Faster R-CNN 에 기반한 Mask R-CNN 모델을 사용
R-CNN(Regions with Convolutional Neural Networks features)
: 설정한 Region을 CNN의 feature로 사용하여 Object Detection을 수행하는 신경망
Mask R-CNN
: Faster R-CNN이 검출한 객체 각각의 박스에 Mask를 씌우는 모델Faster R-CNN + object mask detection
= Object Detection + Instance Segmentation
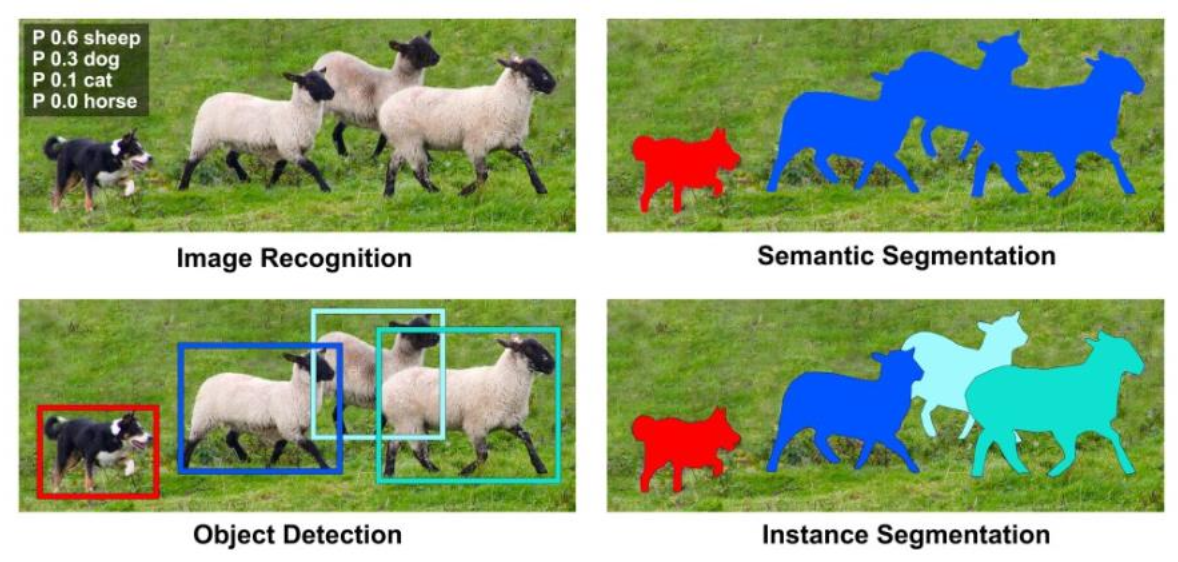
Faster R-CNN
RoI Pooling Layer ( 원하는 region의 feature를 max pooling 하기 위한 layer )
간단하고 효율적으로 객체 영역 처리 가능
데이터 손실이 발생할 수 있음
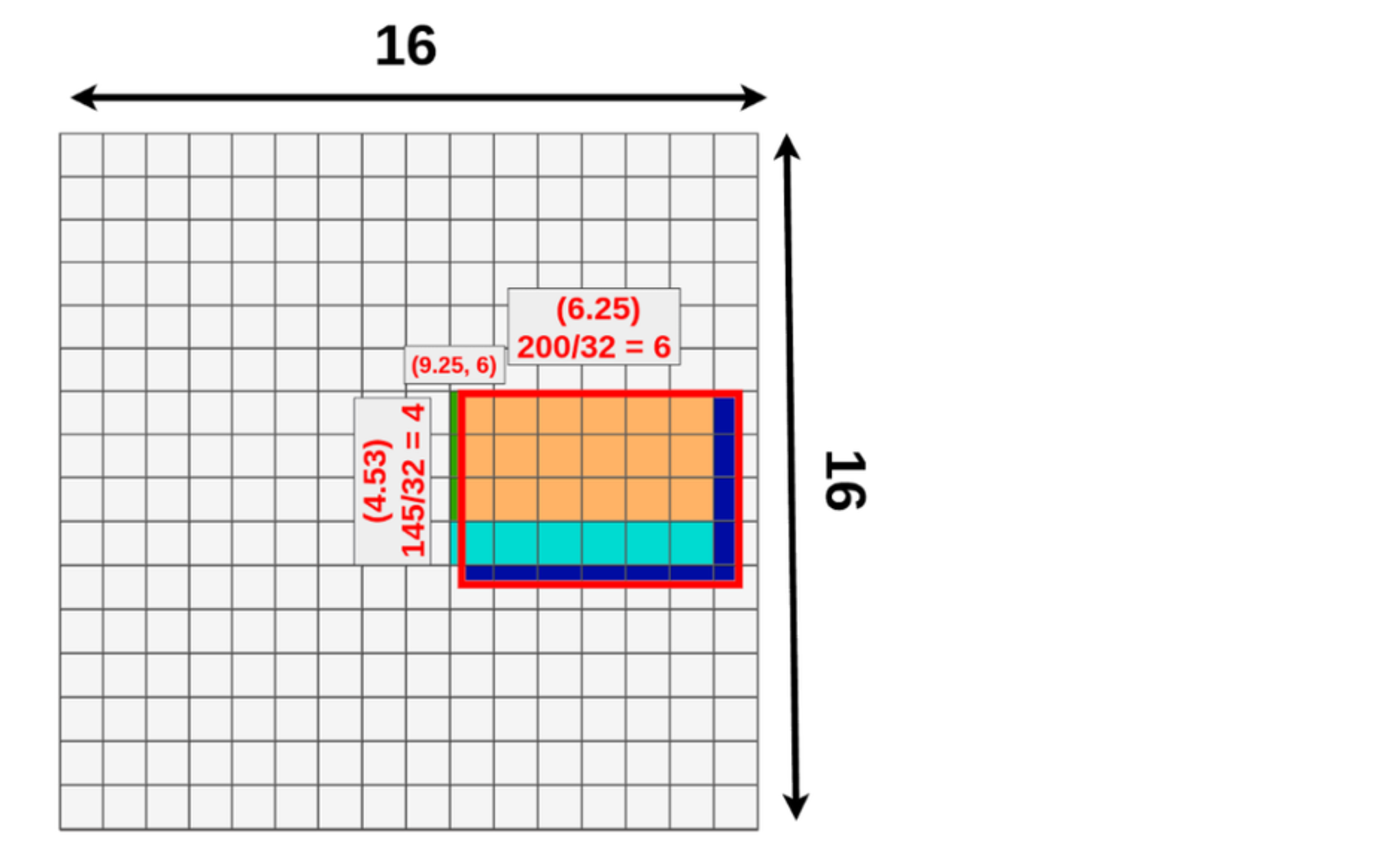
Mask R-CNN
RoI Align
데이터 손실을 최소화하고 정확한 위치 정보 제공
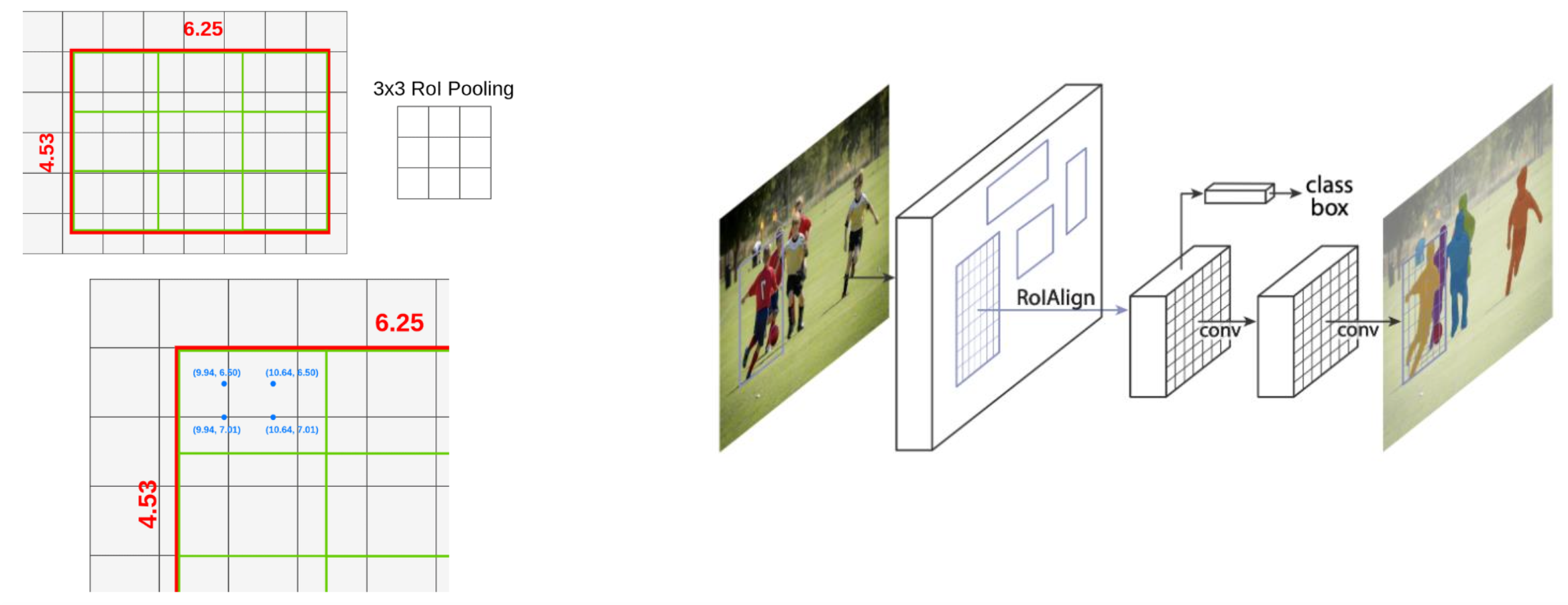
1 - 미리 학습된 모델로부터 미세 조정
COCO에 대해 미리 학습된 모델에서 시작하여 특정 클래스를 위해 미세 조정을 원한다고 가정
import torchvision
from torchvision.models.detection.faster_rcnn import FastRCNNPredictor
# COCO로 미리 학습된 모델 읽기
model = torchvision.models.detection.fasterrcnn_resnet50_fpn(weights="DEFAULT")
# 분류기를 새로운 것으로 교체하는데, num_classes는 사용자가 정의합니다
num_classes = 2 # 1 클래스(사람) + 배경
# 분류기에서 사용할 입력 특징의 차원 정보를 얻습니다
in_features = model.roi_heads.box_predictor.cls_score.in_features
# 미리 학습된 모델의 머리 부분을 새로운 것으로 교체합니다
model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)2 - 다른 백본을 추가하도록 모델을 수정하기
import torchvision
from torchvision.models.detection import FasterRCNN
from torchvision.models.detection.rpn import AnchorGenerator
# 분류 목적으로 미리 학습된 모델을 로드하고 특징들만을 리턴하도록 합니다
backbone = torchvision.models.mobilenet_v2(weights="DEFAULT").features
# Faster RCNN은 백본의 출력 채널 수를 알아야 합니다.
# mobilenetV2의 경우 1280이므로 여기에 추가해야 합니다.
backbone.out_channels = 1280
# RPN(Region Proposal Network)이 5개의 서로 다른 크기와 3개의 다른 측면 비율(Aspect ratio)을 가진
# 5 x 3개의 앵커를 공간 위치마다 생성하도록 합니다.
# 각 특징 맵이 잠재적으로 다른 사이즈와 측면 비율을 가질 수 있기 때문에 Tuple[Tuple[int]] 타입을 가지도록 합니다.
anchor_generator = AnchorGenerator(sizes=((32, 64, 128, 256, 512),),
aspect_ratios=((0.5, 1.0, 2.0),))
# 관심 영역의 자르기 및 재할당 후 자르기 크기를 수행하는 데 사용할 피쳐 맵을 정의합니다.
# 만약 백본이 텐서를 리턴할때, featmap_names 는 [0] 이 될 것이라고 예상합니다.
# 일반적으로 백본은 OrderedDict[Tensor] 타입을 리턴해야 합니다.
# 그리고 특징맵에서 사용할 featmap_names 값을 정할 수 있습니다.
roi_pooler = torchvision.ops.MultiScaleRoIAlign(featmap_names=['0'],
output_size=7,
sampling_ratio=2)
# 조각들을 Faster RCNN 모델로 합칩니다.
model = FasterRCNN(backbone,
num_classes=2,
rpn_anchor_generator=anchor_generator,
box_roi_pool=roi_pooler)PennFudan 데이터셋을 위한 인스턴스 분할 모델
우리의 경우, 데이터 세트가 매우 작기 때문에, 우리는 1번 접근법을 따를 것이라는 점을 고려하여 미리 학습된 모델에서 미세 조정하는 방식으로 진행
여기서 인스턴스 분할 마스크도 계산하기를 원하기 때문에 Mask R-CNN를 사용
import torchvision
from torchvision.models.detection.faster_rcnn import FastRCNNPredictor
from torchvision.models.detection.mask_rcnn import MaskRCNNPredictor
def get_model_instance_segmentation(num_classes):
# COCO 에서 미리 학습된 인스턴스 분할 모델을 읽어옵니다
model = torchvision.models.detection.maskrcnn_resnet50_fpn(weights="DEFAULT")
# 분류를 위한 입력 특징 차원을 얻습니다
in_features = model.roi_heads.box_predictor.cls_score.in_features
# 미리 학습된 헤더를 새로운 것으로 바꿉니다
model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)
# 마스크 분류기를 위한 입력 특징들의 차원을 얻습니다
in_features_mask = model.roi_heads.mask_predictor.conv5_mask.in_channels
hidden_layer = 256
# 마스크 예측기를 새로운 것으로 바꿉니다
model.roi_heads.mask_predictor = MaskRCNNPredictor(in_features_mask,
hidden_layer,
num_classes)
return model모델을 사용자 정의 데이터셋에서 학습하고 평가할 준비가 된다
모든 것을 하나로 합치기
references/detection/ 폴더 내에 검출 모델들의 학습과 평과를 쉽게 하기 위한 도움 함수들이 있다. 여기서 references/detection/engine.py, references/detection/utils.py, references/detection/transforms.py 를 사용 할 것이다. references/detection 아래의 모든 파일과 폴더들을 사용자의 폴더로 복사한 뒤 사용.
import transforms as T
def get_transform(train):
transforms = []
transforms.append(T.PILToTensor())
transforms.append(T.ConvertImageDtype(torch.float))
if train:
# (역자주: 학습시 50% 확률로 학습 영상을 좌우 반전 변환합니다)
transforms.append(T.RandomHorizontalFlip(0.5))
return T.Compose(transforms)데이터 증강 / 변환을 위한 도움 함수
forward() 메소드 테스트하기 (optional)
데이터셋을 반복하기 전에, 샘플 데이터로 학습과 추론 시 모델이 예상대로 동작하는지 살펴보는 것이 좋다.
model = torchvision.models.detection.fasterrcnn_resnet50_fpn(weights="DEFAULT")
dataset = PennFudanDataset('PennFudanPed', get_transform(train=True))
data_loader = torch.utils.data.DataLoader(
dataset, batch_size=2, shuffle=True, num_workers=4,
collate_fn=utils.collate_fn)
# 학습 시
images,targets = next(iter(data_loader))
images = list(image for image in images)
targets = [{k: v for k, v in t.items()} for t in targets]
output = model(images,targets) # Returns losses and detections
# 추론 시
model.eval()
x = [torch.rand(3, 300, 400), torch.rand(3, 500, 400)]
predictions = model(x) # Returns predictionsfrom engine import train_one_epoch, evaluate
import utils
def main():
# 학습을 GPU로 진행하되 GPU가 가용하지 않으면 CPU로 합니다
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
# 우리 데이터셋은 두 개의 클래스만 가집니다 - 배경과 사람
num_classes = 2
# 데이터셋과 정의된 변환들을 사용합니다
dataset = PennFudanDataset('PennFudanPed', get_transform(train=True))
dataset_test = PennFudanDataset('PennFudanPed', get_transform(train=False))
# 데이터셋을 학습용과 테스트용으로 나눕니다(역자주: 여기서는 전체의 50개를 테스트에, 나머지를 학습에 사용합니다)
indices = torch.randperm(len(dataset)).tolist()
dataset = torch.utils.data.Subset(dataset, indices[:-50])
dataset_test = torch.utils.data.Subset(dataset_test, indices[-50:])
# 데이터 로더를 학습용과 검증용으로 정의합니다
data_loader = torch.utils.data.DataLoader(
dataset, batch_size=2, shuffle=True, num_workers=4,
collate_fn=utils.collate_fn)
data_loader_test = torch.utils.data.DataLoader(
dataset_test, batch_size=1, shuffle=False, num_workers=4,
collate_fn=utils.collate_fn)
# 도움 함수를 이용해 모델을 가져옵니다
model = get_model_instance_segmentation(num_classes)
# 모델을 GPU나 CPU로 옮깁니다
model.to(device)
# 옵티마이저(Optimizer)를 만듭니다
params = [p for p in model.parameters() if p.requires_grad]
optimizer = torch.optim.SGD(params, lr=0.005,
momentum=0.9, weight_decay=0.0005)
# 학습률 스케쥴러를 만듭니다
lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer,
step_size=3,
gamma=0.1)
# 10 에포크만큼 학습해봅시다
num_epochs = 10
for epoch in range(num_epochs):
# 1 에포크동안 학습하고, 10회 마다 출력합니다
train_one_epoch(model, optimizer, data_loader, device, epoch, print_freq=10)
# 학습률을 업데이트 합니다
lr_scheduler.step()
# 테스트 데이터셋에서 평가를 합니다
evaluate(model, data_loader_test, device=device)
print("That's it!")학습(train)과 검증(validation)을 수행하도록 메인 함수를 작성
Epoch: [0] [ 0/60] eta: 0:01:18 lr: 0.000090 loss: 2.5213 (2.5213) loss_classifier: 0.8025 (0.8025) loss_box_reg: 0.2634 (0.2634) loss_mask: 1.4265 (1.4265) loss_objectness: 0.0190 (0.0190) loss_rpn_box_reg: 0.0099 (0.0099) time: 1.3121 data: 0.3024 max mem: 3485
Epoch: [0] [10/60] eta: 0:00:20 lr: 0.000936 loss: 1.3007 (1.5313) loss_classifier: 0.3979 (0.4719) loss_box_reg: 0.2454 (0.2272) loss_mask: 0.6089 (0.7953) loss_objectness: 0.0197 (0.0228) loss_rpn_box_reg: 0.0121 (0.0141) time: 0.4198 data: 0.0298 max mem: 5081
Epoch: [0] [20/60] eta: 0:00:15 lr: 0.001783 loss: 0.7567 (1.1056) loss_classifier: 0.2221 (0.3319) loss_box_reg: 0.2002 (0.2106) loss_mask: 0.2904 (0.5332) loss_objectness: 0.0146 (0.0176) loss_rpn_box_reg: 0.0094 (0.0123) time: 0.3293 data: 0.0035 max mem: 5081
Epoch: [0] [30/60] eta: 0:00:11 lr: 0.002629 loss: 0.4705 (0.8935) loss_classifier: 0.0991 (0.2517) loss_box_reg: 0.1578 (0.1957) loss_mask: 0.1970 (0.4204) loss_objectness: 0.0061 (0.0140) loss_rpn_box_reg: 0.0075 (0.0118) time: 0.3403 data: 0.0044 max mem: 5081
Epoch: [0] [40/60] eta: 0:00:07 lr: 0.003476 loss: 0.3901 (0.7568) loss_classifier: 0.0648 (0.2022) loss_box_reg: 0.1207 (0.1736) loss_mask: 0.1705 (0.3585) loss_objectness: 0.0018 (0.0113) loss_rpn_box_reg: 0.0075 (0.0112) time: 0.3407 data: 0.0044 max mem: 5081
Epoch: [0] [50/60] eta: 0:00:03 lr: 0.004323 loss: 0.3237 (0.6703) loss_classifier: 0.0474 (0.1731) loss_box_reg: 0.1109 (0.1561) loss_mask: 0.1658 (0.3201) loss_objectness: 0.0015 (0.0093) loss_rpn_box_reg: 0.0093 (0.0116) time: 0.3379 data: 0.0043 max mem: 5081
Epoch: [0] [59/60] eta: 0:00:00 lr: 0.005000 loss: 0.2540 (0.6082) loss_classifier: 0.0309 (0.1526) loss_box_reg: 0.0463 (0.1405) loss_mask: 0.1568 (0.2945) loss_objectness: 0.0012 (0.0083) loss_rpn_box_reg: 0.0093 (0.0123) time: 0.3489 data: 0.0042 max mem: 5081
Epoch: [0] Total time: 0:00:21 (0.3570 s / it)
creating index...
index created!
Test: [ 0/50] eta: 0:00:19 model_time: 0.2152 (0.2152) evaluator_time: 0.0133 (0.0133) time: 0.4000 data: 0.1701 max mem: 5081
Test: [49/50] eta: 0:00:00 model_time: 0.0628 (0.0687) evaluator_time: 0.0039 (0.0064) time: 0.0735 data: 0.0022 max mem: 5081
Test: Total time: 0:00:04 (0.0828 s / it)
Averaged stats: model_time: 0.0628 (0.0687) evaluator_time: 0.0039 (0.0064)
Accumulating evaluation results...
DONE (t=0.01s).
Accumulating evaluation results...
DONE (t=0.01s).
IoU metric: bbox
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.606
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.984
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.780
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.313
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.582
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.612
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.270
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.672
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.672
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.650
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.755
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.664
IoU metric: segm
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.704
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.979
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.871
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.325
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.488
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.727
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.316
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.748
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.749
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.650
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.673
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.758첫번째 Epoch 출력값
그래서 1 에포크(epoch) 학습을 거쳐 60.6의 COCO 스타일 mAP와 70.4의 마스크 mAP를 얻었다.
IoU metric: bbox
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.799
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.969
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.935
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.349
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.592
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.831
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.324
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.844
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.844
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.400
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.777
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.870
IoU metric: segm
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.761
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.969
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.919
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.341
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.464
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.788
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.303
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.799
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.799
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.400
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.769
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.81810 에포크 학습 후, 다음과 같은 수치를 얻었다.



데이터 셋에 이미지 하나를 가져와서 확인
학습된 모델이 이미지에서 9개의 사람 인스턴스를 예측했고, 그 중 두어개를 확인
요약
이 튜토리얼에서는 사용자 정의 데이터셋에서 인스턴스 분할 모델을 위한 자체 학습 파이프라인을 생성하는 방법을 배웠다.
이를 위해 영상과 정답 및 분할 마스크를 반환하는 torch.utils.data.Dataset 클래스를 작성했다. 또한 이 새로운 데이터 셋에 대한 전송 학습(Transfer learning)을 수행하기 위해 COCO train2017에 대해 미리 학습된 Mask R-CNN 모델을 활용 했다.
다중머신 / 다중GPU 에서의 학습을 포함하는 더 복잡한 예제를 알고 싶다면 torchvision 저장소에 있는 references/detection/train.py 를 확인해보길 권한다.
출처 : PyTorch Tutorials https://pytorch.org/tutorials/intermediate/torchvision_tutorial.html
