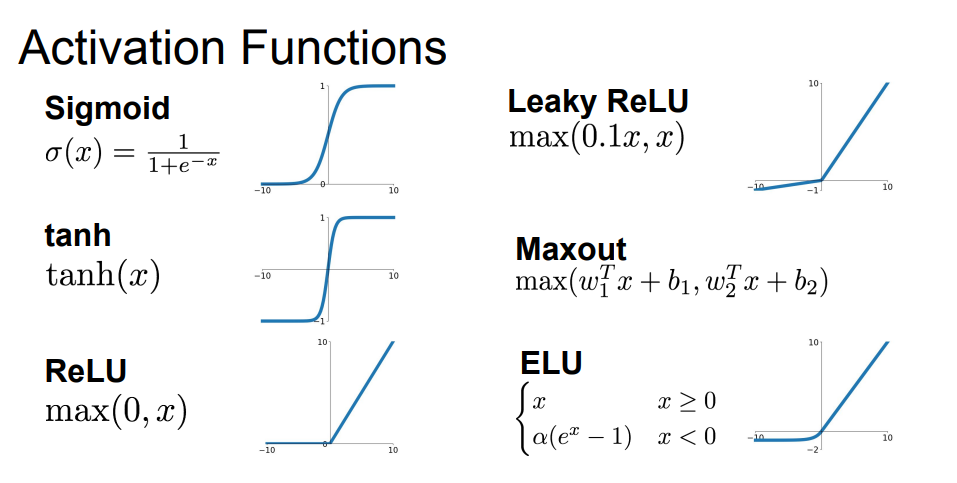
Activation Function(활성화 함수)
입력층(input layer)에서 전달된 정보(값)를 가중치와 곱해지고, 비선형 함수인 활성화 함수를 거쳐 크거나 작다는 정보가 전달(0 또는 1) 되어 해당 데이터의 활성화 여부를 결정해줍니다. 정보가 활성화 되는지 혹은 정보가 활성화 된다면, 어떻게 활성화 되어 출력값을 생성해내는지를 결정하는 활성화 함수에는 여러가지가 있습니다. 각 활성화 함수의 문제점과 이를 어떻게 개선했는지에 대해 알아보겠습니다.

Sigmoid(시그모이드)
- 핵심
- 시그모이드 함수는 값이 들어왔을 때, 0~1 사이의 값을 출력하며, 중앙값이 0.5입니다.
- 이상치가 들어온다 할지라도, 시그모이드 함수는 0과 1에 수렴하므로, 이상치 문제도 해결하면서, 연속된 값을 전달할 수 있습니다.
- 시그모이드 함수를 활성화 함수로 사용하면, 0과 1에 가까운 값을 통해 이진 분류를 할 수 있습니다.
- 장점
- 분류는 0과 1로 나뉘며, 출력값이 어느 값에 가까운지를 통해 어느 분류에 속하는지 쉽게 알 수 있습니다.
- 단점
- 기울기 소실(Gradient Vanishing) 문제
- 시그모이드 함수의 도함수(미분결과)는 f(x)(1-f(x))인데, 도함수에 들어가는 함수의 값이 0이나 1에 가까울수록 당연히 출력되는 값이 0에 가까워지게 됩니다.
- 이로 인해 수렴되는 뉴런의 기울기 값이 0이 되고, 역전파 시 0이 곱해져서 기울기가 소멸(kill)되는 현상이 발생해버립니다. 즉, 역전파가 진행될수록 아래 층(Layer)에 아무런 신호가 전달되지 않는 것입니다.
- 이를 기울기 소실이라 하며, 렐루 함수가 등장하기 전까지인 1986년부터 2006년까지 해결되지 않은 문제였습니다.
- 학습 속도 저하 문제
- 시그모이드 함수의 출력값은 모두 양수이기 때문에 경사하강법을 진행할 때, 그 기울기가 모두 양수거나 음수가 됩니다. 이는 기울기 업데이트가 지그재그로 변동하는 결과를 가지고 오고, 학습 효율성을 감소시켜 학습에 더 많은 시간이 들어가게 됩니다.
- 요약
- 시그모이드 함수는 출력값이 너무 작아 제대로 학습이 안되는데다가 시간이 많이 걸립니다.
- 출력층에서만 사용하고 입력층이나 은닉층에서는사용하지 않는 것이 좋습니다.
- 만약, 입력층에서 쓰고자 한다면, 이의 발전형인 하이퍼볼릭 탄젠트 함수를 사용하는 것을 추천합니다.
Hyperbolic Tangent, tanh(하이퍼볼릭 탄젠트)
- 핵심
- 하이퍼볼릭 탄젠트 함수는 시그모이드 함수를 일부 보완했습니다.
- 두 함수의 가장 큰 차이는 출력값의 범위로, 하이퍼볼릭 탄젠트 함수는 -1~1 사이의 값을 출력하며, 중앙값도 0입니다.
- 장점
- 중앙값이 0이기 때문에, 경사하강법 사용 시 시그모이드 함수에서 발생하는 편향 이동이 발생하지 않습니다.
- 즉, 기울기가 양수 음수 모두 나올 수 있기 때문에 시그모이드 함수보다 학습 효율성이 뛰어납니다.
- 또한, 시그모이드 함수보다 범위가 넓기 때문에 출력값의 변화폭이 더 크고, 그로 인해 기울기 소실 현상이 더 적은 편입니다.
- 단점
- 시그모이드 함수보다 범위가 넓다 뿐이지 하이퍼볼릭 탄젠트 역시 그 구간이 그리 크지는 않은 편이므로, x가 -5보다 작고 5보다 큰 경우, 기울기가 0으로 작아져 소실되는 기울기 소실 현상 문제는 여전히 존재합니다.
- 요약
- 시그모이드 함수의 단점을 많이 보완한 활성화 함수이긴 하지만, 여전히 기울기 소실 문제가 발생할 가능성이 있습니다.
Rectified Linear Unit, ReLU(렐루)
- 핵심
- 렐루 함수는 우리말로, 정류된 선형 함수라고 하는데, 간단하게 말해서 "+/-"가 반복되는 신호에서 "-"흐름을 차단한다는 의미입니다.
- 말 그대로, 양수면 자기 자신을 반환하고, 음수면 0을 반환합니다.
- 장점
- 기울기 소실(Gradient Vanishing) 문제가 발생하지 않습니다.
- 렐루 함수는 양수는 그대로, 음수는 0으로 반환하는데, 그러다 보니 특정 양수 값에 수렴하지 않습니다.
- 즉, 출력값의 범위가 넓고, 양수인 경우 자기 자신을 그대로 반환하기 때문에, 기울기 소실 문제가 발생하지 않습니다.
- 기존 활성화 함수에 비해 속도가 빠릅니다.
- 동시에 렐루 함수의 공식은 음수면 0, 양수면 자기 자신을 반환하는 아주 단순한 공식이다 보니, 경사 하강 시 다른 활성화 함수에 비해 학습 속도가 매우 빠릅니다.
- ReLU는 편미분(기울기) 시 1로 일정하므로, 가중치 업데이트 속도가 매우 빠릅니다.
- 단점
- 렐루 함수의 그래프를 보면, 음수 값이 들어오는 경우 모두 0으로 반환하는 문제가 있다보니, 입력값이 음수인 경우 기울기도 모조리 0으로 나오게 됩니다.
- 입력값이 음수인 경우에 한정되긴 하지만, 기울기가 0이 되어 가중치 업데이트가 안되는 현상이 발생할 수 있습니다.
- 즉, 가중치가 업데이트 되는 과정에서 가중치 합이 음수가 되는 순간 ReLU는 0을 반환하기 때문에 해당 뉴런은 그 이후로 0만 반환하는 아무것도 변하지 않는 현상이 발생할 수 있습니다.
- 이러한 죽은 뉴런(Dead Neuron)을 초래하는 현상을 죽어가는 렐루(Dying ReLU) 현상이라고 합니다.
- 또한 렐루 함수는 기울기 소실 문제 방지를 위해 사용하는 활성화 함수이기 때문에 은닉층에서만 사용하는 것을 추천합니다.
- ReLU의 출력값은 0 또는 양수이며, ReLU의 기울기도 0 또는 1이므로, 둘 다 양수입니다. 이로 인해 시그모이드 함수처럼 가중치 업데이트 시 지그재로 최적의 가중치를 찾아가는 현상이 발생합니다.
- 또, ReLU의 미분은 0 초과 시 1, 0은 0으로 끊긴다는 문제가 있습니다. 즉, ReLU는 0에서 미분이 불가능합니다(이에 대해 활성화 함수로는 미분 불가능하다 할지라도, 출력값 문제는 아니고, 0에 걸릴 확률이 적으니, 이를 무시하고 사용합니다.).
- 요약
- 기본적으로 은닉층에서는 렐루 함수를 사용하지만, 때에 따라 렐루 함수의 단점이 두드러지는 경우도 존재하므로, 렐루 함수의 한계점을 보완하기 위한 렐루 함수의 형제 함수들이 있습니다.
Leaky ReLU, LReLU(리키 렐루)
- 핵심
- 렐루 함수의 한계점은 음수 값들이 모두 0이 된다는 것이었습니다.
- 이를 해결하기 위해, 음수를 일부 반영해주는 함수인 리키 렐루가 등장하게 되었습니다.
- 렐루 함수는 음수를 0으로 해주었다면, 리키 렐루는 음수를 0.01배 한다는 특징이 있습니다.
- 장점 및 단점
- 리키 렐루는 음수에 아주 미미한 값(0.01)을 곱하여, Dying ReLU를 막고자 하였습니다.
- 그러나, 음수에서 선형성이 생기게 되고, 그로 인해 복잡한 분류에서 사용할 수 없다는 한계가 생겼습니다.
- 도리어 일부 사례에서 Sigmoid 함수나 Tanh 함수보다도 성능이 떨어질 때도 있습니다.
- 요약
- 만약, 음수가 아주 중요한 상황이라면 제한적으로 사용하는 것을 추천합니다.
Exponential Linear Unit, ELU(E렐루)
- 핵심
- E렐루는 2015년에 나온 비교적 최근 방법으로, 각져 있는 ReLU를 exp를 사용해, 부드럽게(Smooth) 만든 것입니다.

- 위 코드에서 (x>0)은 x가 0보다 큰 값만 True로 하여 1로 나머지 값은 0으로 만듭니다.
- (x<=0)은 0 이하인 값만 True로 하여 1로 하고 나머지 값은 0으로 만듭니다.
- 0보다 큰 경우 x가 곱해지고, 0 이하는 exp(x)-1이 곱해집니다.
- 각 반대되는 영역은 0이므로, 두 array를 합치면, 의도한 양수는 본래의 값, 나머지 값은 exp(x)-1이 곱해져서 더해집니다.
- 장점 및 단점
- Masking을 이용한 Numpy 연산은 코드를 단순하게 하고, 연산 시간을 크게 줄입니다.
- ELU는 ReLU와 유사하게 생겼으면서도, exp를 이용해 그래프를 부드럽게 만들고, 그로 인해 미분 시, 0에서 끊어지는 ReLU와 달리 ELU는 미분해도 부드럽게 이어집니다.
- ELU는 ReLU의 대표적인 대안 방법 중 하나입니다.
- ELU는 ReLU와 달리 음의 출력을 생성할 수 있습니다.
- ELU는 음에서도 비선형적이기 때문에 복잡한 분류에서 사용할 수 있습니다.
- α는 일반적으로 1로 설정하며, 이 경우 x=0에서 급격하기 변하지 않고, 모든 구간에서 매끄럽게 변하므로, 경사 하강법에서 수렴 속도가 빠릅니다.
- 요약
- 렐루 함수에 비해 성능이 크게 증가한다는 이슈가 없으며, 되려 exp의 존재로 연산량이 늘어났기에 학습 속도가 렐루 함수에 비해 느려서 잘 사용하지 않습니다.
Maxout(맥스아웃)
- 핵심
- 맥스아웃은 활성 함수를 구간 선형 함수로 가정하고, 각 뉴런에 최적화된 활성 함수를 학습을 통해 찾아냅니다.
- ReLU와 리키 렐루의 일반화된 형태라고 볼 수 있으며 성능이 뛰어납니다.
- 장점 및 단점
- ReLU의 장점을 모두 가지며, ReLU의 단점인 Dying ReLU 문제 또한 해결합니다.
- 하지만 계산해야 하는 양이 많고 복잡하다는 단점이 있습니다.
결론
강의에서는 ReLU > LReLU or ELU > tanh 순으로 사용할 것을 이야기하였으며, 가능한 sigmoid는 사용하지 말라고 하였습니다.
나는 킹고수다!!