자세한 내용은 논문을 참고하세요.
Latent Retrieval for Weakly Supervised Open Domain Question Answering : https://arxiv.org/abs/1906.00300
Background
1. Information Retrieval (IR) System

- 사용자가 질문을 입력하였을 때, 질문과 연관된 문서를 return해주는 task
2. Question Answering

- 사용자가 질문과 질문의 정답이 포함되어 있는 문서를 함께 입력하였을 때, 문서 내에서 정확한 정답을 찾아서 return해주는 task
3. Open Domain Question Answering

- QA task와 달리, 사용자가 질문만 입력을 하면, 거대한 코퍼스(ex. wikipedia)에서 정답이 있는 문서를 찾아 문서 내에서 정확한 정답을 return해주는 task
- 두 가지 구성 요소(Retriever, Reader)로 이루어져있음.
- Document Retriever : 주어진 질문과 가장 연관성 있는 문서를 코퍼스 내에서 찾아주는 역할
- Document Reader : Retriever에서 찾은 연관성 있는 문서 내에서 질문에 해당하는 정답을 찾아주는 역할
4. DRQA
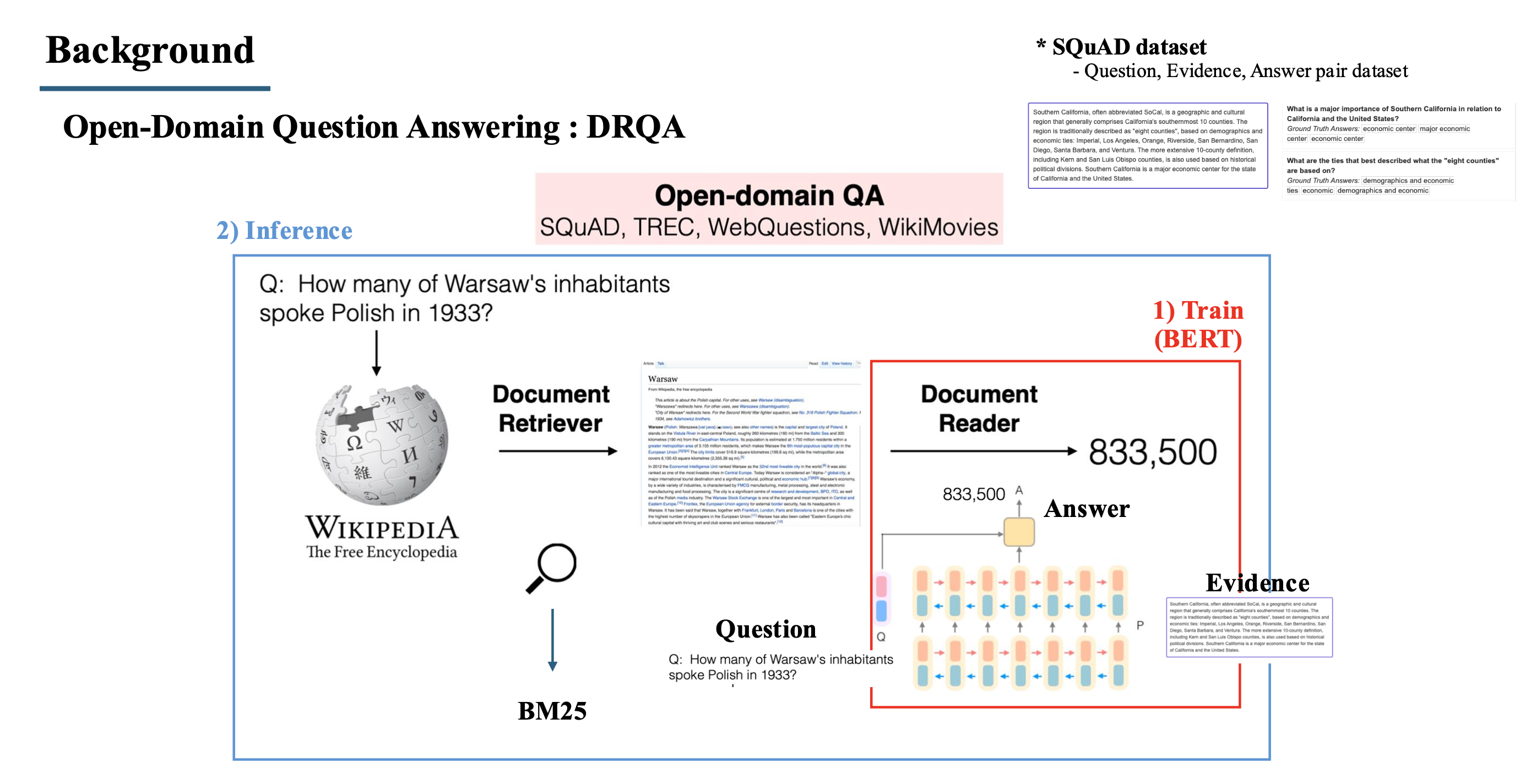
- ORQA의 사전 연구로, 처음으로 거대한 코퍼스(wikipedia)에서 문서를 찾을 수 있도록 한 논문.
- 학습을 할 때, 사용되는 dataset은 question, evidence(document), answer pair로 된 data를 사용함.
- 학습은 Reader만 학습을 진행하고, Question과 evidence를 입력으로 받아 answer를 찾아주는 Question answering task로 supervised learning을 진행.
- Inference 단계에서는 질문을 받으면 wikipedia에서 BM25 알고리즘을 통해 관련된 문서를 찾고, 찾은 문서와 질문을 학습한 reader의 input으로 넣어 정답을 도출하는 방식.
- BM25 알고리즘은 TF-IDF 방식을 기반으로 한 word matching 방식이며, 문장의 길이 등을 고려한 전통적인 IR 방식.
Introduction

- 사전연구인 DrQA에서 문제점을 크게 2가지 생각하였음.
1. Strong supervision
- 진행하는 task가 question, answer만 있어도 되는 ODQA task임에도 불구하고, 학습을 할 때 사전 연구에서는 question, answer, evidence pair로 이루어진 데이터로 학습을 진행함.
- 실제 ODQA 환경에 적합하도록 evidence data가 필요하지 않은 일반적인 접근법으로 학습하고자 진행함
2. Reliance on IR system
- wikipedia라는 거대한 코퍼스(1300만 개의 문서) 공간에서 검색을 하는 것을 줄이고자 BM25와 같은 전통적인 알고리즘 방식에 의존을 하게 됨.
- 하지만 QA task는 IR task와 달리 단순 연관된 문서를 찾는 것이 아닌 정답이 있는 문서를 찾아야 하고, 이는 단순 단어 비교(word matching) 알고리즘 이상으로 언어적 이해능력이 필요한 task임
→ 따라서 저자들은 전통적인 IR system에 의존하지 않고, retriever를 함께 end-to-end로 학습을 진행. 사용되는 dataset또한 question, evidence, answer pair가 아닌 question, answer pair data로만 진행
Method
1. Open Retrieval Question Answering (ORQA)
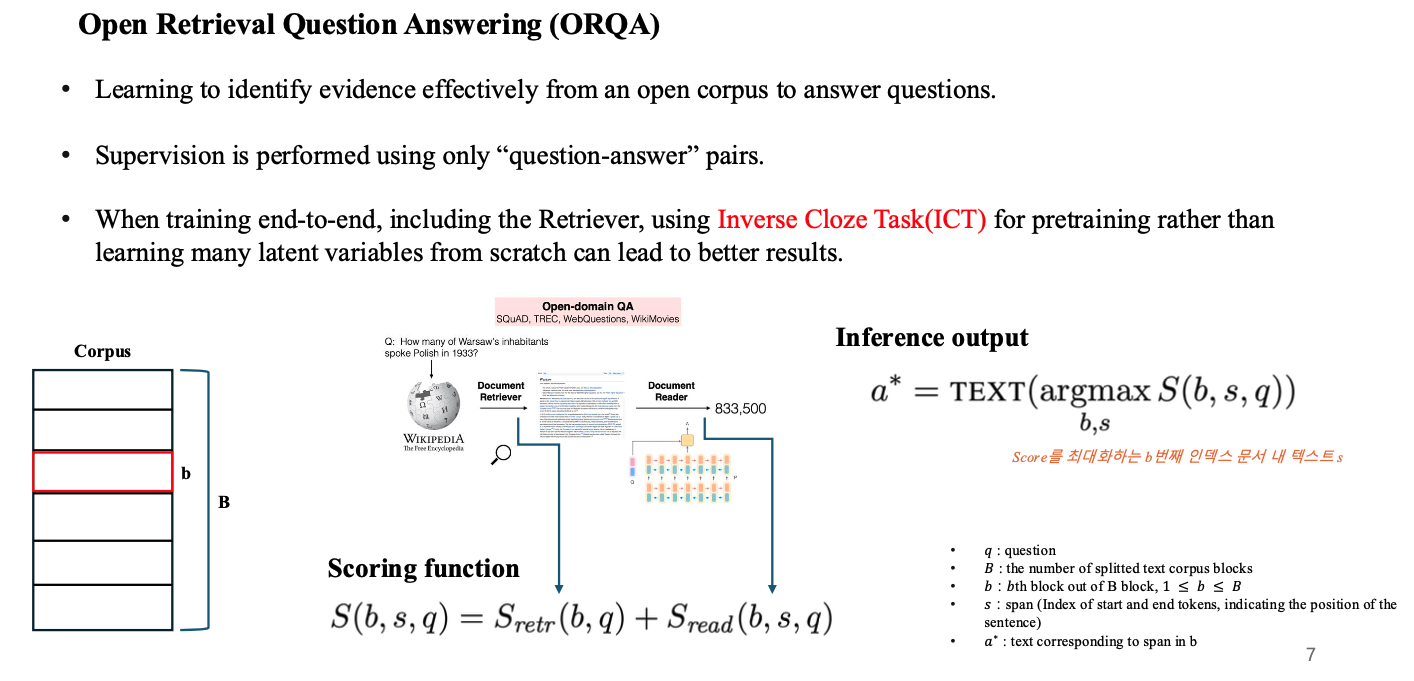
- 앞서 설명한 것처럼, ORQA의 목적은 question-answer pair data만을 사용하여 end-to-end 방식으로 retriever를 포함하여 학습을 진행하고, retriever가 관련된 문서를 효과적으로 찾는 것을 목표로 함.
- end-to-end로 retriever를 학습을 진행하려고 하니, supervised 방식으로 학습을 하려면 question-evidence 쌍으로 된 데이터가 있어야 학습이 가능함. 하지만 본 논문은 question-answer만 존재.
- 따라서 본 논문에서는 Inverse Cloze task(ICT) 라는 pre-training 방식을 제안하여 retriever를 사전학습함.
- 사전학습을 통해 scratch로 학습을 하는 것보다 더욱 latent variable을 잘 학습할 수 있으며, wikipedia 대량의 정보를 미리 담아둘 수 있음.
- 논문 소개에 들어가기 앞서 ORQA 모델을 나타내는 수식을 살펴보면, 해당 모델은 라는 score로 정의됨.
- 위 score는 2개의 term으로 나뉘는데, 와 로 나뉘게 됨.
- 는 질문과 wikipedia의 block(evidence)이 input으로 들어가 나오는 질문과 문서 사이의 연관성을 나타낸 점수.
- 는 retriever에서 전달받은 block(b)과 질문, 정답 후보(span)를 Input으로 받아 output인지 아닌지 판단하는 점수.
- 최종 output은 위 score인 가 가장 높은 부분의 span을 TEXT로 바꿔주는 함수를 거쳐 output을 return함.
2. Overview

- 제안하는 모델(ORQA)의 전체 figure
- 왼쪽의 파란색 박스가 관련된 문서를 찾아주는 retriever
- 우측의 주황색 박스가 관련된 문서 내에서 정답을 찾아주는 reader
3. Retriever Component
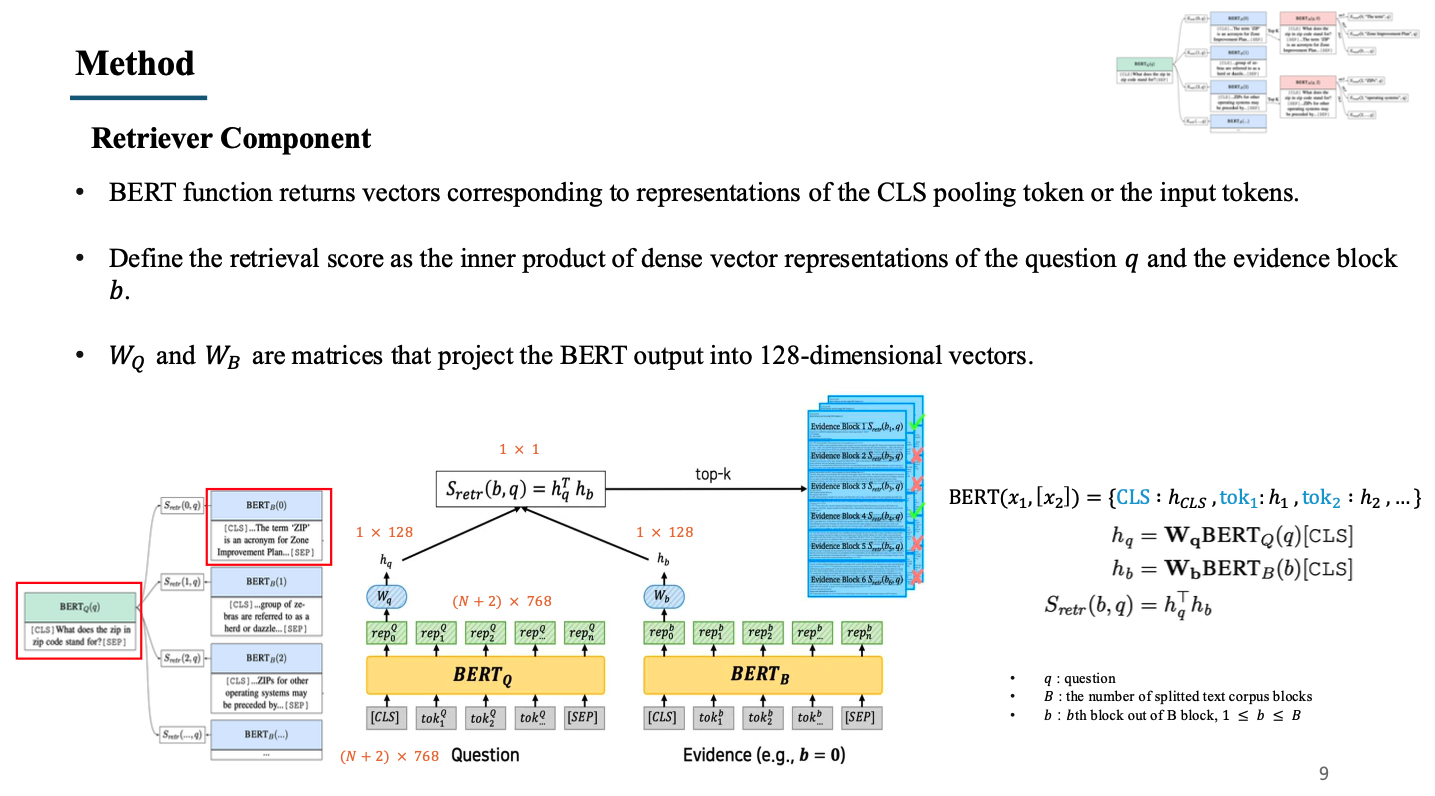
- Retriever는 question과 block을 input으로 받음. 예시로 좌측 그림의 빨간색 박스를 예시로 들겠음.
- question은 CLS 토큰과 SEP 토큰을 붙인 뒤 token embedding을 진행(가운데 그림의 회색 박스들)
- embedding된 question token은 에 들어가서 output으로 각 토큰들의 representation vector를 받음(가운데 그림의 초록 박스)
- output 중 CLS 토큰에 해당하는 representation token만을 사용하며, 해당 토큰에 weight matrix를 곱하여 dimension을 128로 낮춤.
- 마찬가지로 wikipedia 내의 block들도 token embedding을 진행한 뒤 에 넣어 representation vector를 추출하고, 이 중 CLS 토큰에 해당하는 representation token에 대해 를 사용하여 dimension을 128로 맞춤.
- 앞서 구한 와 를 내적 연산하여 similarity를 계산함. 이 과정을 wikipedia 내의 모든 block들에 대해 계산하여 가장 높은 top-k개의 문서를 reader로 전달.
- 위와 같은 과정에서 1300만개의 wikipedia block을 모두 계산하는 것은 pre-training으로 미리 만들어둔 table을 이용하며, 이에 관한 내용은 다음 ICT 파트에서 설명.
4. Inverse Cloze task (ICT)

- Retriever에서 1300만 개의 문서를 모두 검색하는 것은 시간/공간적으로도 힘든 일이다. 또한 현재 주어진 data는 질문, 1300만 개의 문서, 답변만이 존재하여 retriever를 supervised 방식으로 학습시키는 것은 불가능하다.
- 논문의 저자들을 ICT를 이용하여 QA를 위한 retriever를 학습하는 것을 목표로 하며, 현재 존재하는 1300만 개의 문서 데이터만을 이용하여 unsupervised learning으로 retriever를 학습시킨다.
- 이를 통해 기존의 BM25와 같은 word matching 알고리즘과는 달리 문맥을 이해하는 능력을 키우고자 한다.
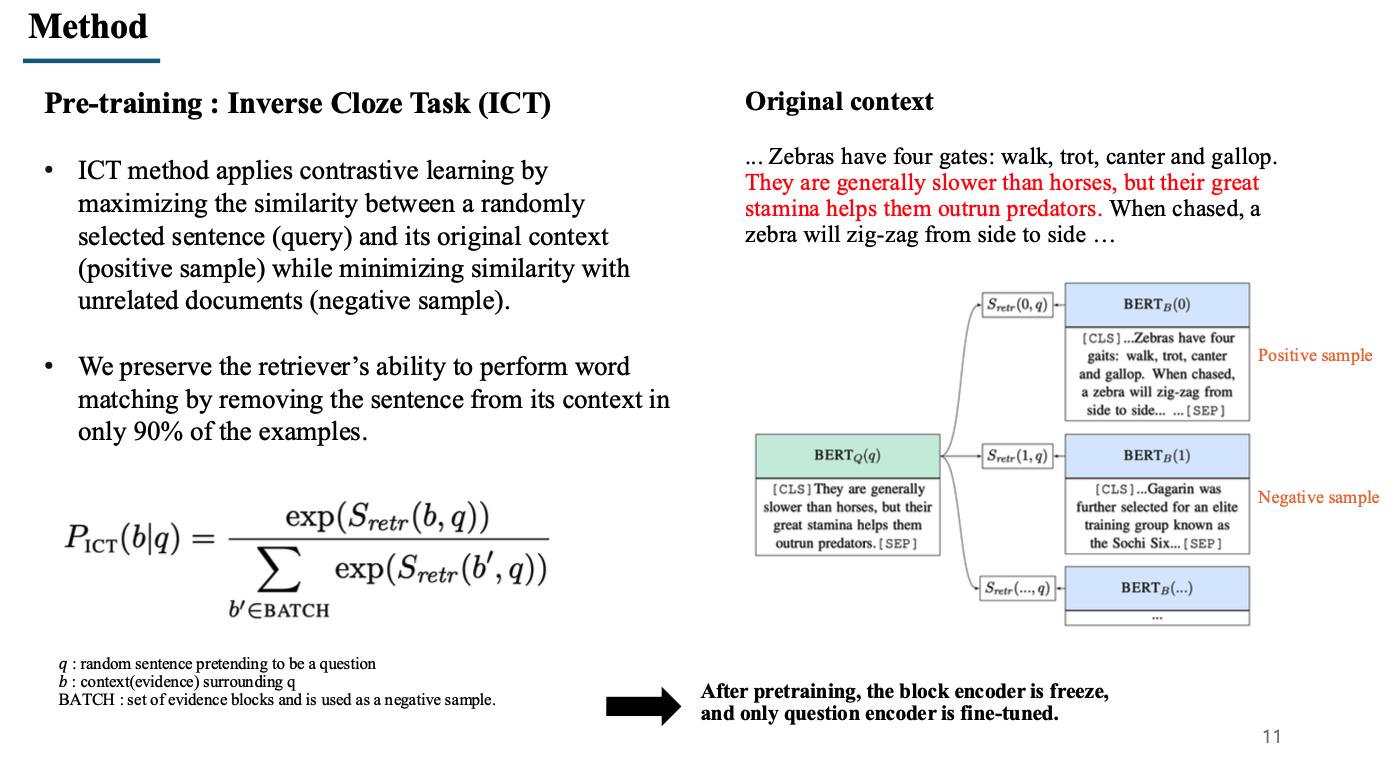
Cloze task : BERT 모델을 학습시킬 때 사용하는 Mask prediction과 같은 task로, sentence에서 mask를 씌우고, mask를 씌우지 않은 주변 문맥을 통해 mask를 predict하는 task.
- Inverse Cloze task는 Cloze task를 반대로 한 것으로, mask를 이용하여 주변 문장을 예측하도록 하는 pre-training 기법이다.
- 여러 개의 문장으로 이루어진 문서에서 가운데 문장(빨간색 문장)에 mask를 씌우고, 이를 question이라고 생각한다.
- mask를 씌운 문장을 제외한 나머지 부분(검정 문장)을 document bert에 넣고, 배치 내의 다른 문서들을 함께 비교한다.
- 이와 같은 학습을 통해, question(mask sentence)과 mask를 제외한 나머지 document 부분의 유사도가 높아지는 방향으로 학습을 진행한다. 즉, 가운데 문장을 이용하여 주변 문장을 예측하여 유사도가 가장 높도록 학습한다.
- 이는 contrastive learning의 관점으로 생각하여, batch 내의 다른 document는 negative sample로 거리(유사도)가 멀어지게 학습하고, question을 추출한 document는 positive sample로 거리(유사도)가 가까워지게 학습을 진행한다.
- 저자들은 위와 같은 방식으로 문맥을 학습하는 것이 중요하지만, 단순한 word matching 기법 또한 정답이 있는 문서, 또는 연관된 문서를 찾는 것에 있어 중요한 방법이라고 생각하여 90%의 데이터만 위와 같은 방식으로 학습하고, 10%의 데이터는 question을 포함한 Original context를 그대로 Document bert에 넣어 해당 문장이 있는지 없는지를 판단할 수 있도록 하였다.
- 수식의 경우, score(similarity)를 softmax 형태로 정규화를 한 형태이며, 해당 배치 내에서 positive sample에 해당하는 score를 나타낸 수식이다. 이 확률에 negative log likelihood 방식을 적용하여 retriever만을 pre-training한다.
- pre-training이 끝난 뒤, document BERT는 freeze를 하며, question BERT만 추후 fine-tuning 단계에서 학습한다.
- pre-training이 끝나면, 1300만 개의 문서를 모두 document BERT에 넣어 CLS token을 추출한다. 그리고 위 token들을 모두 table로 저장하여 fine-tuning 단계에서는 매 iteration마다 1300만 개의 문서를 반복적으로 넣는게 아닌 CLS token을 저장해둔 table을 불러와서 weight matrix를 계산하도록 한다.
- freeze를 함으로써 fine-tuning 시에 많은 메모리를 필요로 하지 않게 된다.
5. Reader Component
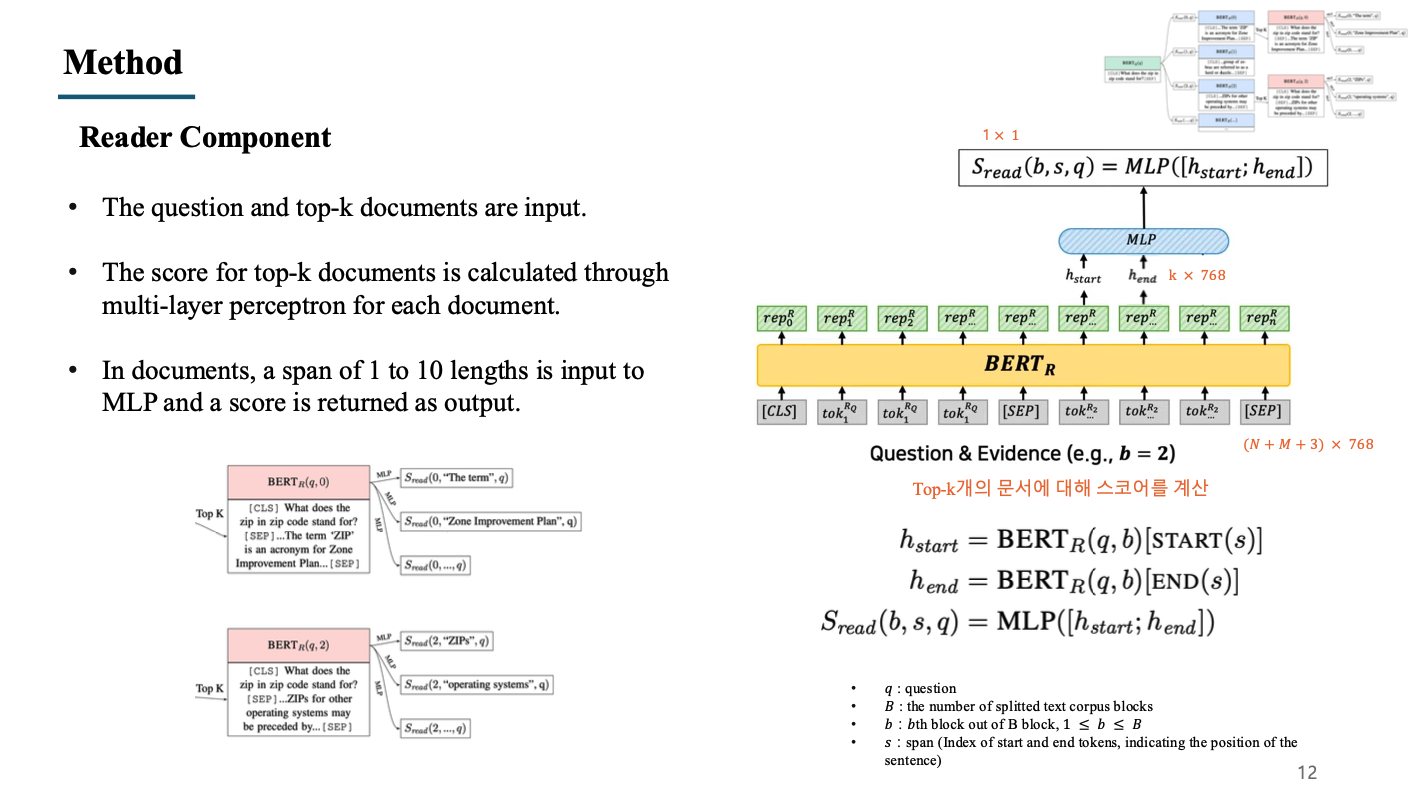
- Reader에는 앞서 설명한 retriever에서 전달받는 top-k개의 문서와 질문이 input으로 들어감.
- 에는 SEP token으로 구분된 question과 documnet가 함께 concat하여 들어가게 되며, concat된 문장들이 token embedding을 거쳐 우측 그림의 회색 박스들이 됨.
- embedding된 token들은 BERT 모델을 거쳐 representation vector가 되며, 이후 사용되는 것은 document에 해당하는 representation vector임.
- document에 해당하는 representation vector들에 대해서 token의 개수가 1~10인 모든 경우의 수를 만들고, 해당 벡터들을 MLP의 input으로 하여 score가 나오도록 함. (1~10인 이유는 dataset을 만들 때 answer의 길이가 maximum 10이기 때문)
- 답변으로 가능한 모든 span들의 score를 계산하였으면 최종적으로 score가 가장 높은 span을 최종 output으로 도출해주게 됨.
6. Training
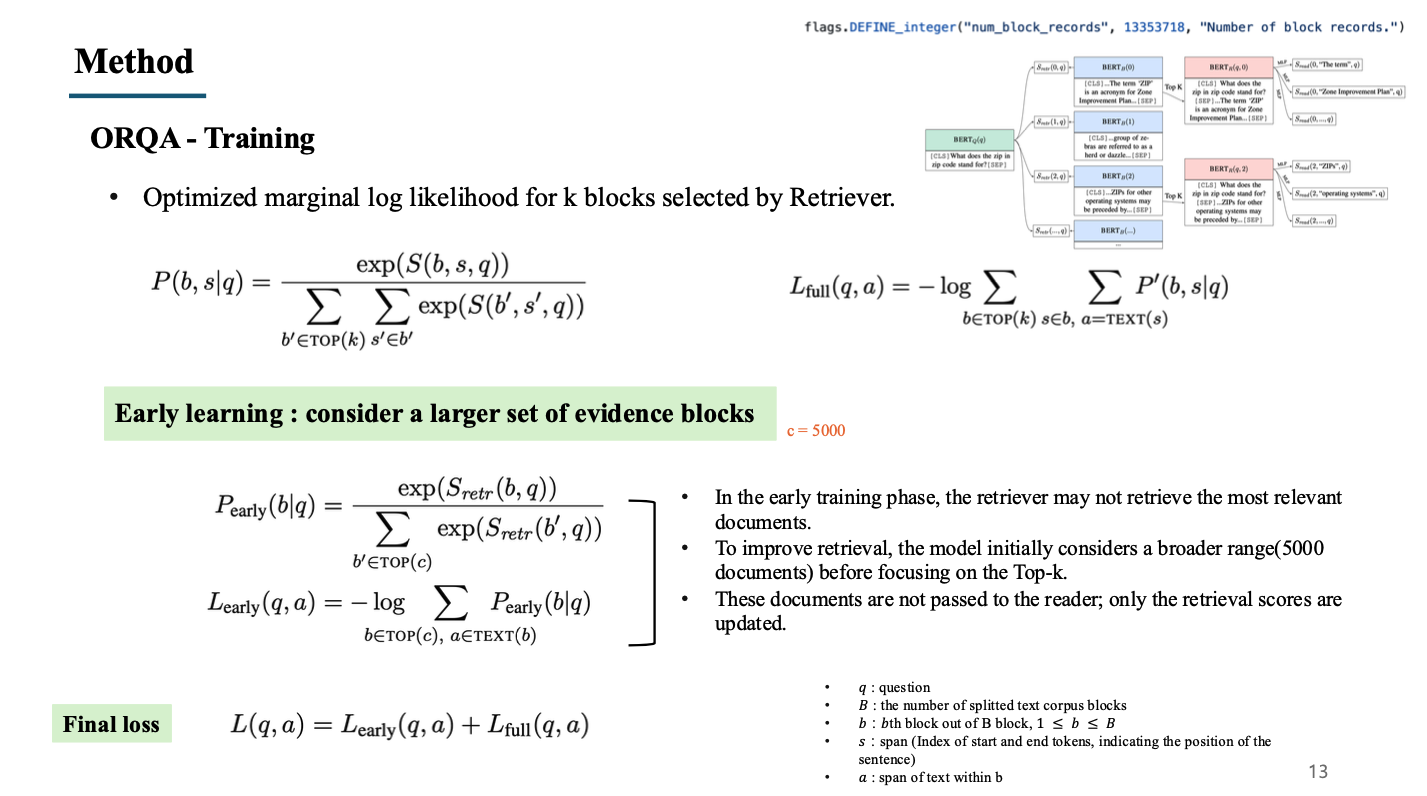
- Training(fine-tuning) 단계에서는 retriever에서 계산한 top-k개 문서들에 대한 score()와 reader에서 계산한 span 후보 모두에 대한 score()를 합한 score()를 계산하여, softmax 형태로 정규화한 확률을 계산함.
- 계산된 확률에 대해 negative log likelihood 방식으로 loss를 만들어 를 사용함.
- 이 때 에 해당하는 확률은 정답 span에 대한 확률이고, 이러한 정답은 top-k(5)개의 문서에 대해 정답 span이 있어야함. 하지만 실제로 top-k개의 문서가 정답을 포함하고 있을 확률은 매우 낮음.
- 저자들은 이러한 retriever가 학습 초반에 연관된 문서를 찾는 능력이 좋지 않을 것이라고 생각하여 early learning 기법을 통해 retriever를 더욱 빨리 학습시킬 수 있는 loss term을 추가함.
- top-C(5000)개의 질문과 연관된 문서를 선정하고, 해당하는 5000개의 문서들의 similarity score를 합산하여 loss term으로 추가함으로써, 관련된 문서를 더욱 잘 찾을 수 있도록 함.
- 5000개의 문서는 reader로 전달되지 않고 오직 retriever score만을 업데이트하기 위해 사용됨.
만일 최종 score를 계산할 때 정답 span이 없는 경우는 어떻게 되는가?
- = 0 이 될 것이고 = 0이 될 것임. 즉, negative log likelihood를 통해 loss로 변환되면 - 이기 때문에 매우 큰 loss값이 나오게 될 것이므로 학습하는 것에 있어서 문제 X
Dataset

- 사용된 dataset은 5가지이며, TriviaQA, SQuAD와 같은 데이터셋은 기존에 evidence도 pair로 존재하지만 evidence는 사용하지 않고 question과 answer pair로만 사용함.
- evidece(document) corpus는 2018년 12월 20일 wikipedia를 기준으로 만들어졌음.
- wikipedia의 내용을 문장 단위를 보존하는 선에서 최대 288개의 wordpice를 기준으로 block(document)를 생성하였고, 총 1300만 개의 block을 생성함.
Result
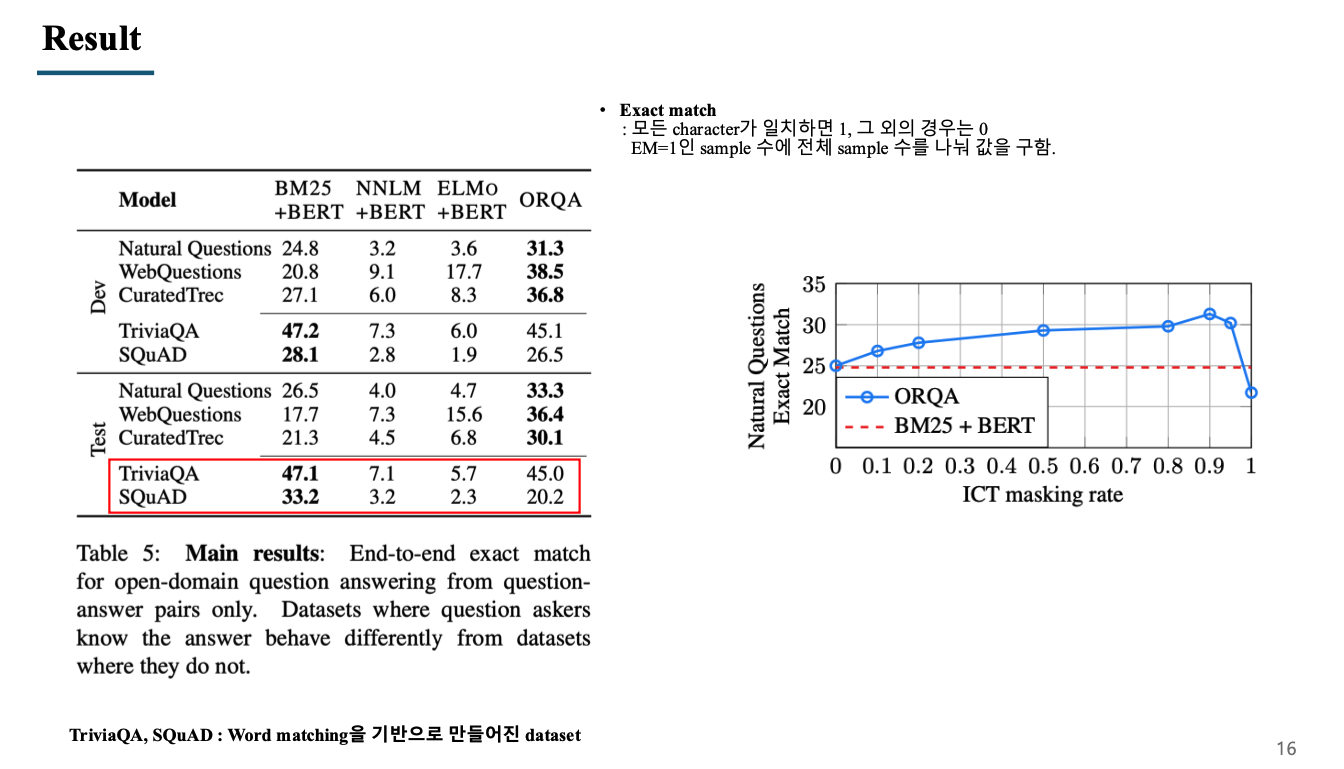
Exact match : 모든 character가 일치하면 EM = 1, 그 외의 경우는 EM = 0 EM=1인 sample 수에 전체 sample 수를 나눠 값을 구함.
-
BM25, NNLM, ELMO는 retriever의 method이며, 전체적으로 ORQA(BERT-pretraining)가 성능이 높은 것을 확인 가능함.
-
하지만 TriviaQA, SQuAD data는 BM25가 성능이 좋은 것을 볼 수 있는데, 이 이유는 이 두 개의 데이터를 구축할 때 reading comprehension을 기반으로 질문에서 답을 추론할 수 있도록 유사한 단어가 이미 질문에 포함되어 있도록 구축을 하였음. 즉, word matching으로 관련된 문서와 정답을 찾을 수 있도록 질문이 주어졌기 때문에 BM25와 같은 알고리즘의 성능이 높은 것을 확인할 수 있음.
-
우측의 그래프는 masking rate를 조절하며 성능을 확인한 그래프로, 90%의 데이터를 masking하였을 때가 가장 성능이 좋았음.
-
전체 데이터를 masking하였을 때(rate = 1) 오히려 masking을 하지 않은 것보다 성능이 떨어지는 것을 확인할 수 있음.
-
이를 해석하였을 때, 문맥을 파악하는 능력이 중요하지만, 단어를 매칭하는 것을 고려하지 않으면 오히려 추론을 잘못할 수 있다는 것으로 볼 수 있음.
