이전 논문의 후속 연구 논문으로, 논문을 읽으며 제 생각도 포함되어 있으니 참고하시면서 읽어주세요!
자세한 내용은 아래 논문을 참고해주세요!
출처 : https://arxiv.org/abs/2210.13452
Introduction
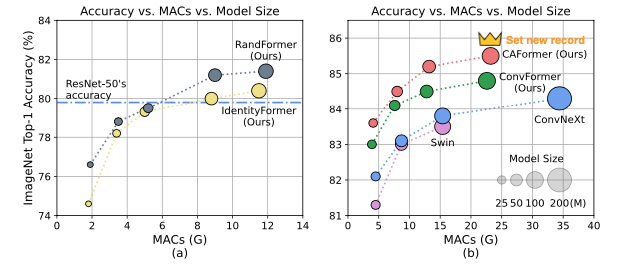
본 논문에서는 Metaformer의 token mixer 부분에 identity / random mixer / convolution / convolution + attention 을 실험하였고, 위 결과를 통해 3가지로 결과를 요약할 수 있다.
- MetaFormer는 안정적으로 성능의 lower boundary 역할을 한다.
- IdentityFormer처럼 연산 조차도 없는 model이 약 74~80의 성능을 보이기 때문이다.
- MetaFormer는 arbitrary token mixer에서도 성능이 잘 나온다.
- random initialize된 RandFormer를 token mixer로 사용하여도 성능이 어느정도 잘 나온다.
- 큰 노력 없이도 MetaFormer의 틀로 SOTA의 성능이 나온다.
- CAFormer의 경우 ImageNet-1K에 대해서 SOTA의 성능을 보여주었다.
Method
1. Recap the concept of MetaFormer

Input I가 들어왔을 때, Embedding을 진행한 것을 X라고 한다. 이후 X에 대해 normalize를 하고 지정하는 Token Mixer를 적용한 뒤 residual connection을 더해준다. 마지막으로 이를 normalize를 해준 뒤 Channel mlp를 거치고 다시 residual connection을 더해주는 형태를 MetaFormer라고 한다.
2. Overall frameworks of Model
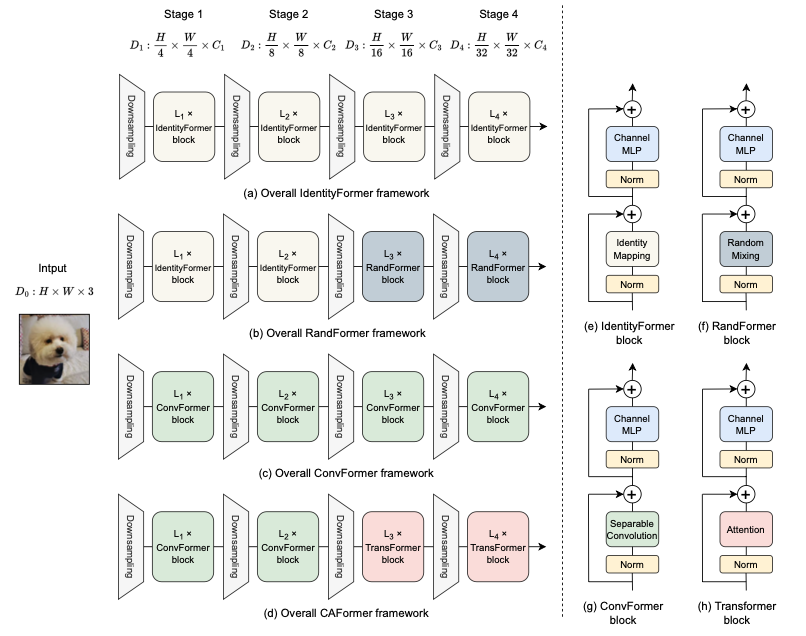
- 본 논문에서는 4가지의 모델을 실험 및 제안하였고, 최종적으로는 ConvFormer, CAFormer를 제안한다.
3. IdentityFormer / RandFormer
1) IdentityFormer

- TokenMixer 부분에 Identity Mapping을 넣은 model이다. 별개의 다른 연산이 되는 것이 아닌 block의 input으로 X를 넣었을 때 그대로 X가 나오도록 하는 연산을 진행한다.
2) RandFormer
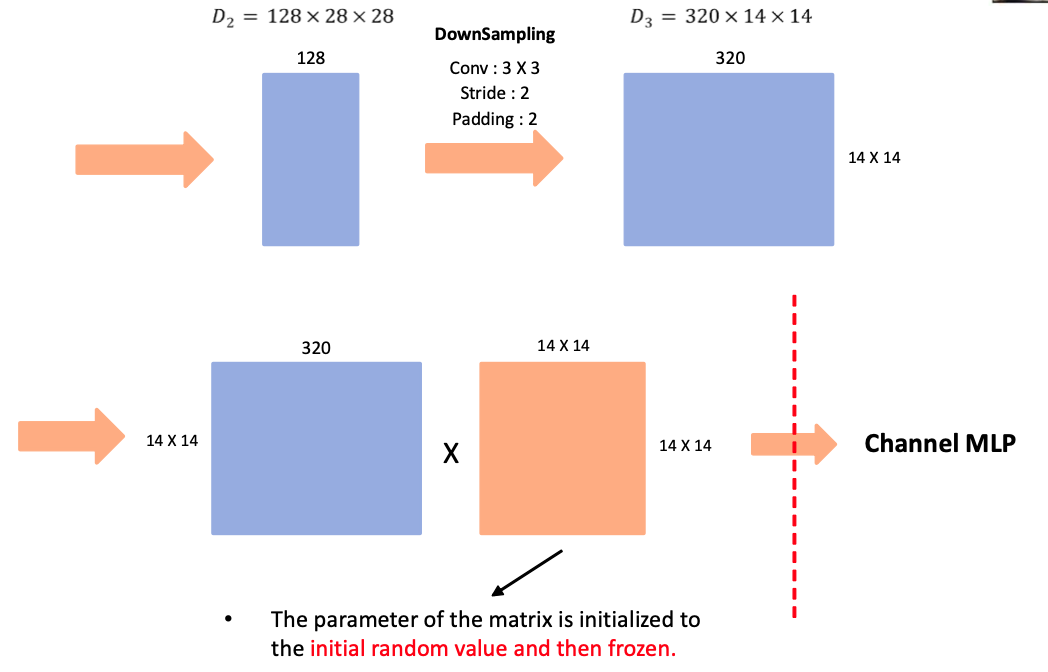
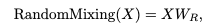
그림의 경우 발표 준비를 하며 예시로 그린 그림입니다. 참고하면 좋을 것 같아 첨부합니다.
- Token Mixer 부분에 Random Mixing을 적용한 model이다. random value로 초기화 한 matrix를 곱해주는 연산이다. 이 때 random value로 초기화한 parameter는 freeze를 하여 이 후 사용될 때는 값이 고정된 채로 사용이 된다.
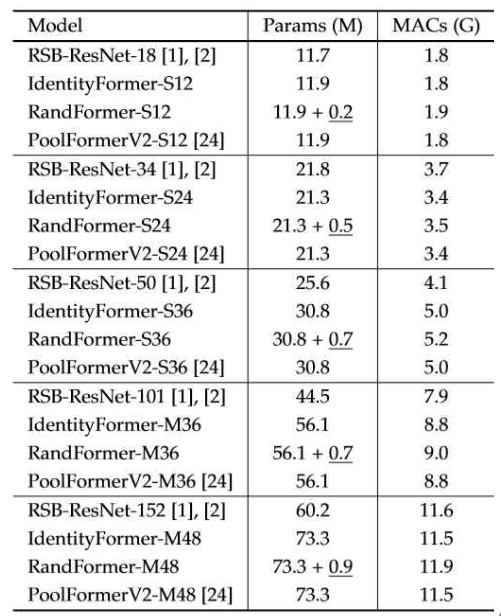
위 표에서 밑줄 친 부분은 RandFormer에서 random value로 초기화되고 freeze된 parameter 부분을 나타낸다. IdentityFormer와 밑줄 친 부분만큼 parameter가 차이나는 것을 확인할 수 있다.
4. ConvFormer & CAFormer
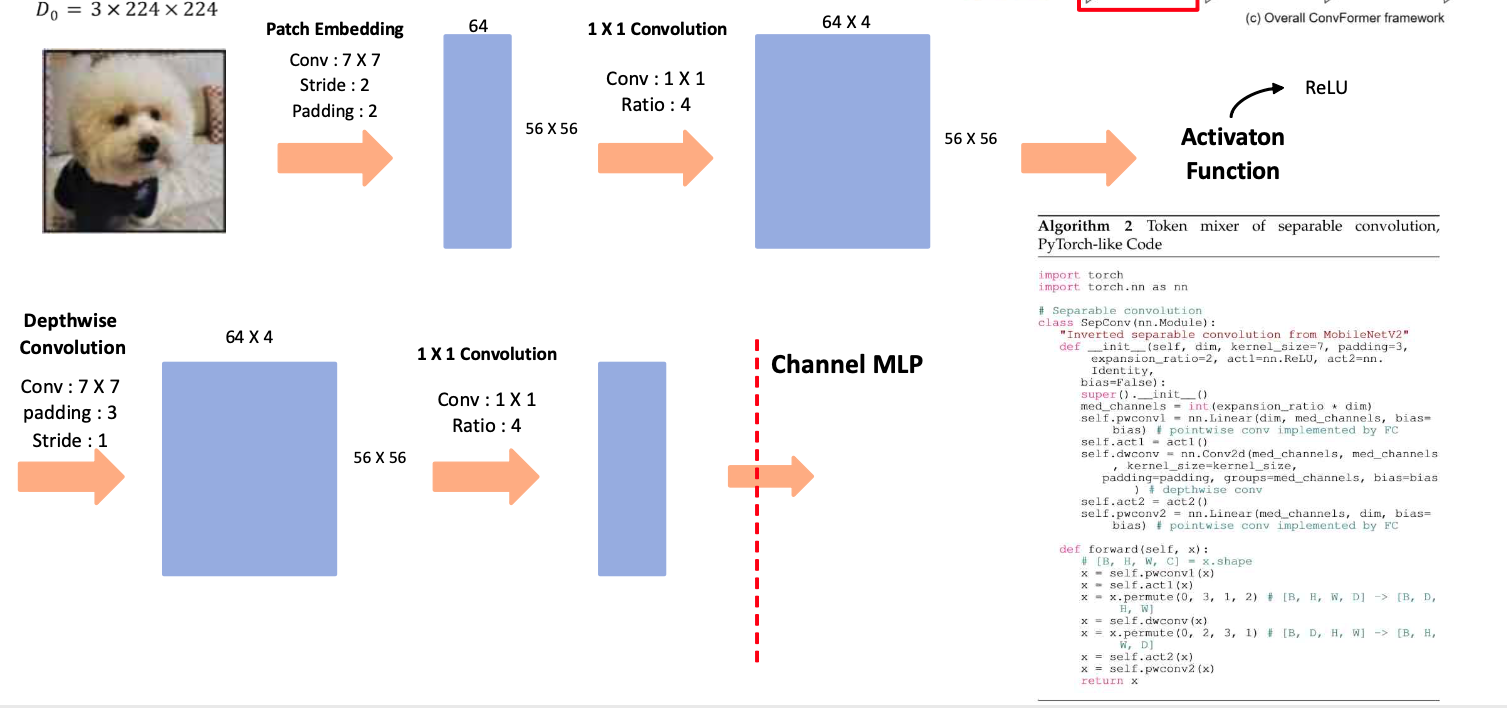
Attention의 경우 기존 ViT와 동일하기 때문에 추가적으로 설명하지 않는다. ConvFormer의 경우 모든 layer에서 Token Mixer를 Convolution연산을 진행하고, 위의 사진에서 코드, 그림과 같이 진행된다.(물론 각 layer마다 size는 다르다.) CAFormer의 경우 앞의 두 layer에서 Token Mixer를 Convolution 연산으로, 뒤의 두 layer는 Attention 연산으로 진행한다.
5. StarReLU
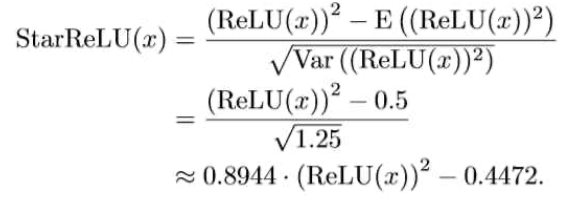
본 논문에서 저자들은 Channel MLP에서 사용되는 activation function을 정의한다. 기존 ViT에서는 GELU function을 사용하는데, GELU의 경우 FLOPs가 14로 기존 방식들에서 사용하던 ReLU, Squared ReLU보다 연산이 훨씬 많이 된다고 한다. 따라서 저자들은 Squared ReLU에서 output의 distribution을 바꾸지 않게 하기 위해 Squarred ReLU의 평균, 분산을 이용하여 StarReLU라는 것을 정의한다. 위 식에서 앞, 뒤의 상수는 learneable parameter로 정의하고 사용을 하도록 한다.
Result
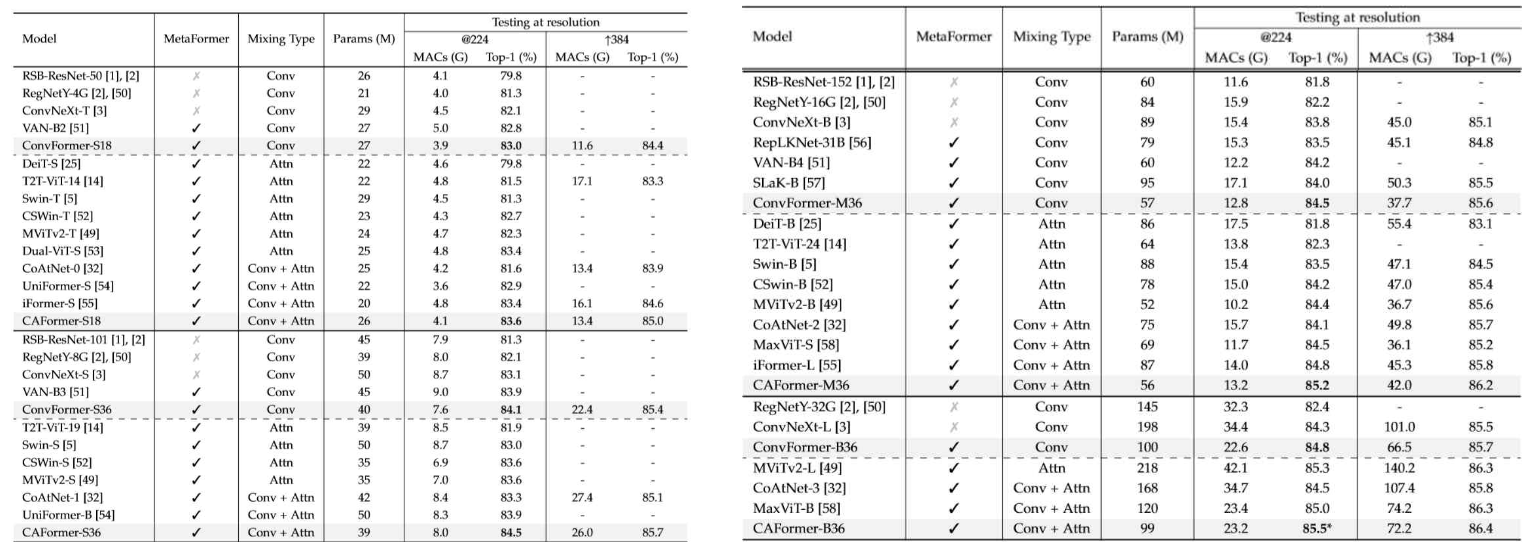
image classificataion에서 대부분의 모델보다 성능이 좋은 것을 확인할 수 있다. 본 논문을 읽으며 든 생각은, metaformer의 좋은 것을 강조하는 것도 있지만, CAFormer의 경우 낮은 레벨에서는 convolution을 통해 feature를 뽑아내고, 뽑아낸 low level의 feature끼리 attention을 진행한 것이 조금 더 핵심 포인트라고 생각된다.
