자세한 내용은 논문을 참고하세요.
MetaFormer Is Actually What You need for Vision : https://arxiv.org/abs/2111.11418
Introduction
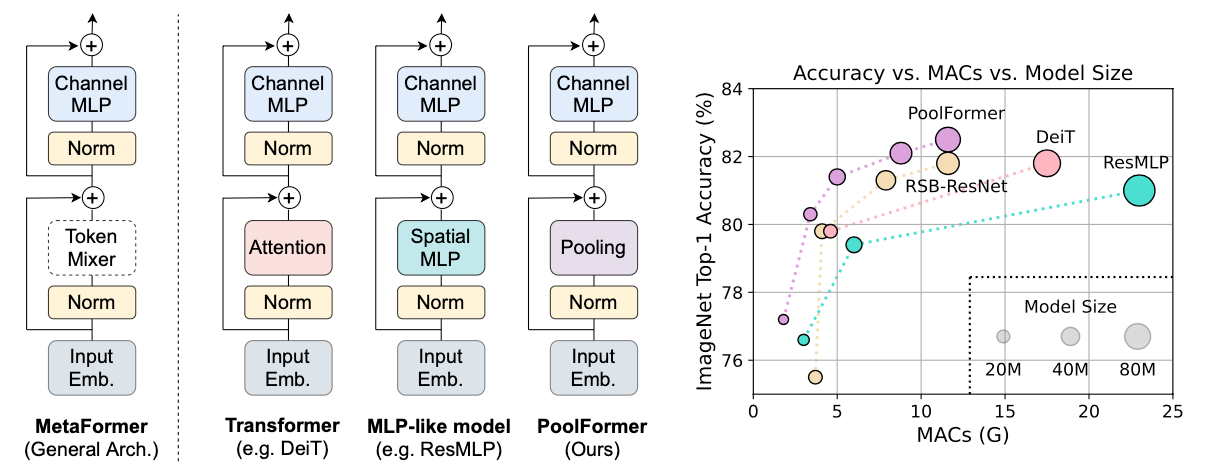
Vision Transformer(ViT)가 computer vision 분야에서 좋은 성능을 보인 후, 이를 기반으로 한 많은 모델들이 vision 분야에서 좋은 성능을 보인다. Transformer 모델은 크게 두 가지의 구성 요소로 구분할 수 있는데, 첫 번째로 각 token간의 information을 mixing 하는 부분인 Attention module 부분이다. 본 논문에서는 이러한 token간의 information을 minxing하는 부분을 Token Mixer라고 지칭한다. 두 번째로, MLP와 residual connection을 진행하는 remaining module이다. Attention은 특정한 Token mixer 중 하나로, Transformer의 구조를 token mixer의 종류보다 더욱 중요시 생각해야한다. 이러한 특정하지 않은 Token Mixer와 함께 이 구조를 MetaFormer라고 언급한다.
즉, Transformer는 MetaFormer의 Token Mixer가 Attention module로 사용된 모델인 것이다. 이러한 가정에서 최근 연구들은 Attention module 대신 MLP를 위 Token Mixer 부분에 대입하였고, Attention module을 대입한 것과 비교하여 경쟁력있는 성능이 나온다. 또한 Attention 대신 Fourier Transform을 대입하여도 약 97%의 성능이 나온다.
본 논문은 이러한 가정을 확인하기 위해 Token Mixer 부분에 단순한 Pooling 과정을 대입하고, 다른 모델들과 성능을 비교해보았다. 위 그래프를 확인하면, 본 논문에서 제안한 가정에 따라 PoolFormer의 성능이 기존 MLP, Transformer보다 성능이 좋은 것을 확인할 수 있다. 물론, Token Mixer의 종류가 중요하지 않은 것은 아니다. 다만 성능의 초점이 General한 Architecture인 MetaFormer 형태가 성능 향상의 요인이 된다는 것이다.
Method
1. MetaFormer
MetaFormer는 구체적으로 Token Mixer가 정해지지 않은 하나의 general architecture로, Transformer의 구성요소와 동일하다.
Input 는 ViT의 patch embedding처럼 embedding 처리를 한다.이 때, embedding token의 sequence length는 이고, embedding dimension은 이다.
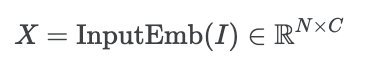
이렇게 embedding 된 token은 반복되는 MetaFormer block에 들어가게 되며, 각 block은 두 개의 residual sub-block으로 나뉜다.
두 개의 sub-block 중 첫 번째 block은 token mixer이다. 이 블록에서는 information을 mixing하는 단계로, 아래의 수식과 같이 표현할 수 있다.
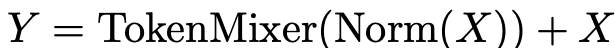
위 수식에서 은 Layer normalization 또는 Batch normalization과 같은 normalization을 의미하며, 는 token들의 정보를 mixing하는 module을 의미한다. 이는 Transformer와 같이 attention이 될 수도 있고, 특별한 MLP model이 올 수 있다.
두 번재 sub-block은 기존에 존재하던 non-linear activation를 가진 2-layer MLP 구조이다.
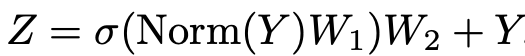
와 는 learnable parameter이다. 는 GELU, RELU와 같은 non-linear activation fuction이다. 이 구조는 기존 Transformer의 encoder에서 attention을 제외한 나머지 부분과 동일하다.
2. Instantiations of MetaFormer.
MetaFormer는 token mixer 부분을 구현하여 다양한 모델을 바로 얻을 수 있는 general architecture를 의미한다. 예시로 Token mixer가 attention이라면 Transformer가 되고, spatial MLP로 한다면 MLP-like 모델이 된다.
3. PoolFormer
현재 진행되고 있는 다양한 연구들은 attention에 초점을 맞춰 다양한 attention-vased token mixer components를 개발하였다. 이와 반대로, 본 연구는 general architecture에 초점을 맞추어 연구를 진행하였다. MetaFormer가 general architecture임을 증명하기 위하여, token mixer 부분에 아주 간단한 operator인 pooling을 대입하였다. 이 operator는 learnable parameter가 없이 token feature를 averagely aggregate한다.
이 연구는 vision task를 목적으로 하기 때문에, input은 channel-first data format을 가진다. 즉, input data는 이다.
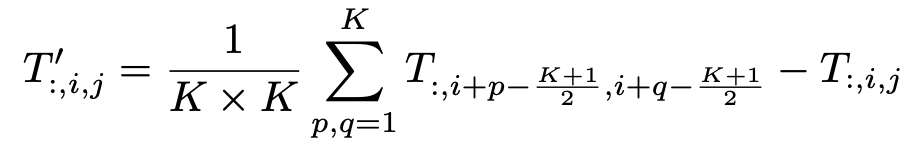
위 수식에서 는 pooling size이다. MetaFormer block은 이미 residual connection을 가지고 있기 때문에, 입력 자체의 뺄셈이 위 수식에 추가가 된다. 본 연구에서 사용한 pooling 방식은 average pooling이다. 전체 그림과 비교해보면 알 수 있지만, 해당 수식에서 한 번 더 빼주는 자신의 픽셀 값과 residual connection으로 더해지는 값은 동일하지 않다. residual connection으로 더해지는 값은 Normalize가 되지 않은 값이기 때문에, 더해줄 때 자기 자신 pixel에 대해서 조금 더 가중되는 효과를 준다고 생각한다.
잘 알려진 바와 같이, self-attention, spatial MLP는 mix하는 token의 수에 비례하는 계산 복잡도를 가진다. 그리고 MLP의 경우에는 더욱 긴 sequence를 처리하면 훨씬 많은 parameter를 필요로 한다. 이와 반대로, pooling은 learnable parameter를 필요로 하지 않기 때분에 sequence length에 선형적인 계산 복잡도만 필요로 한다. 따라서 이는 기존의 CNN이나 Transformer와 같은 모델보다 이점을 가지게 된다.
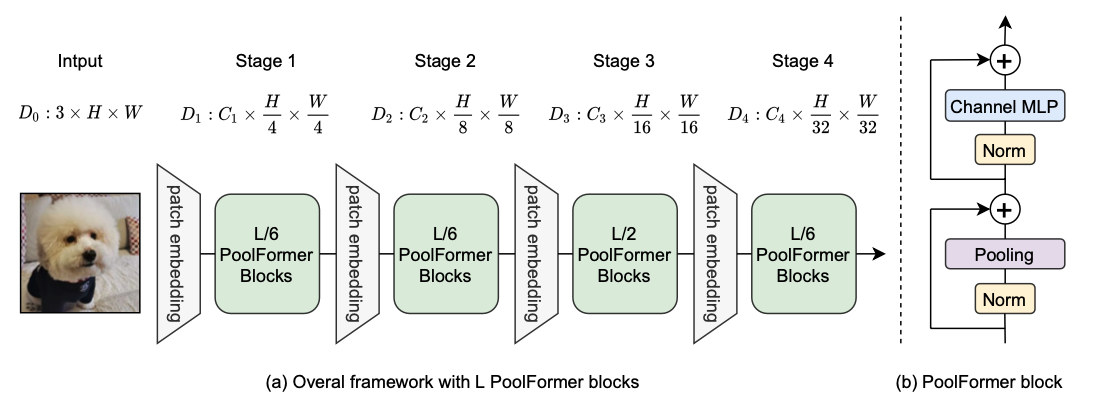
위 그림은 PoolFormer의 전반적인 framework를 보여준다. PoolFormer는 총 4단계로 구성되어 있으며 각각 개의 token으로 구성되어 있다. 는 input image의 높이와 너비이고, embedding size는 2개의 그룹이 존재한다.
1) 4단계의 각 embedding dimension이 64, 128, 320, 512인 small-sized model
2) 4단계의 각 embedding dimension이 96, 192, 384, 768인 medium-sized model
총 개의 PoolFormer block이 있다고 가정하면 단계 1, 2, 3, 4에는 각각 개의 PoolFormer block을 포함한다. MLP expansion ratio는 4로 설정된다. 위의 단순 모델 스케일링 규칙에 따라 PoolFormer의 5가지 모델 크기를 얻었으며 해당 hyperparameter는 아래 표와 같다.
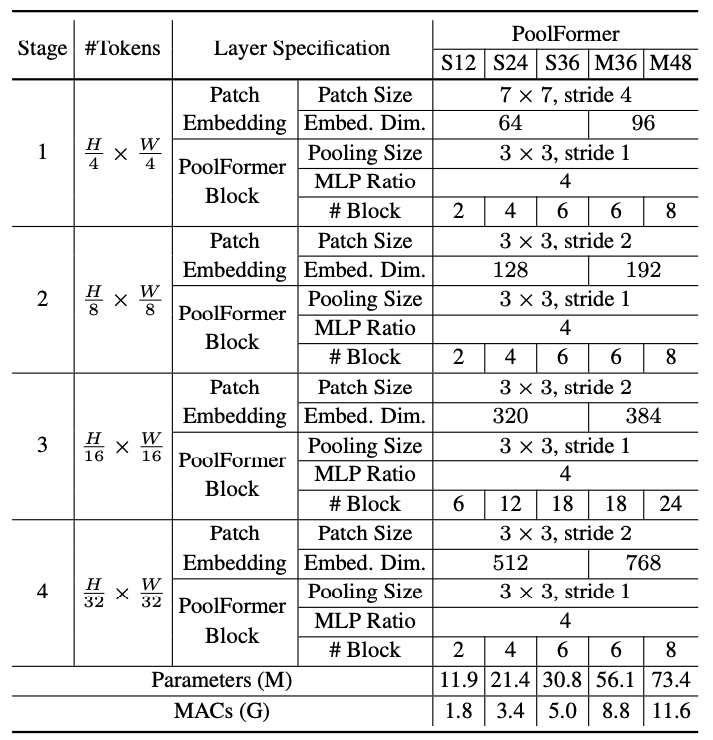
전체적으로는 Swin Transformer와 유사한 구조를 가지고 있다. 각 layer의 Token size가 동일하며, 각 layer의 block 비율이 1:1:3:1 비율로 동일하다. 하지만 초기 input image에서 patch embedding을 해줄 때 transformer의 경우 non-overlapping 방식으로 진행했다면, poolformer에서는 overlap하게 convolution 연산을 진행한다. 혼동되면 안 되는 것으로는 Swin Transformer의 patch merging과 본 논문 figure에 표기되어 있는 patch embedding은 동일한 것이 아니라는 것이다. Swin Transformer에서는 인접한 patch를 기준으로 merging을 진행하여 attention에 도움이 되도록 하는 것이라면, poolformer의 patch embedding은 단순히 downsampling과 동일하다고 보면 된다.
Result
1. Classification
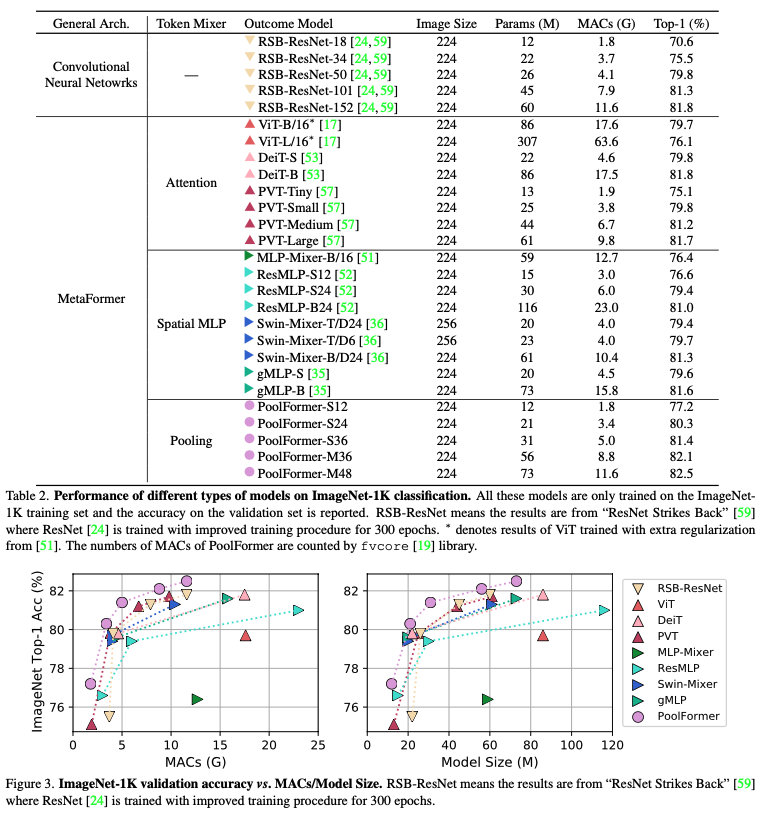
본 논문에서는 ImageNet-1k 데이터로 실험을 진행하였다. parameter도 없는 단순 계산인 pooling으로 ViT의 성능을 뛰어넘으며 이 외의 MLP, CNN 구조의 모델보다 성능이 좋은 것을 입증하였다.
2. Object detection and instance segmentation
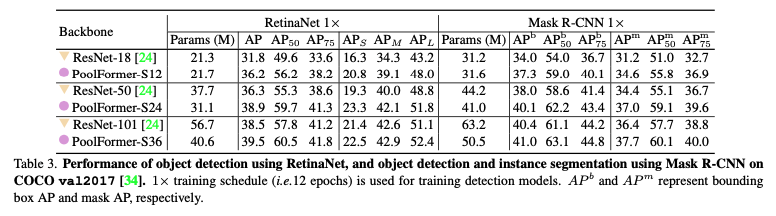
본 논문에서 COCO 데이터로 실험을 진행하였다. object detection에서는 RetinaNet을 backbone 모델로, instance segmentation에서는 Mask R-CNN 모델을 backbone으로 사용하였고, ResNet-18/50/101 모델과 비교실험을 진행하였으며, 대부분의 경우 성능이 좋았다.
3. Sementic Segmentation
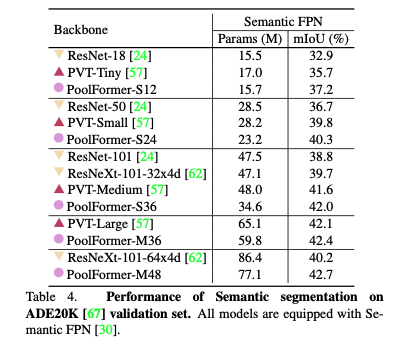
본 논문에서는 ADE20K data로 실험을 진행하였다. parameter 수는 poolformer가 작은 것에 비해 mIOU는 유사한 size의 모델들에 비해 성능이 조금씩 더 좋은 것을 확인할 수 있다.
Ablation Studies
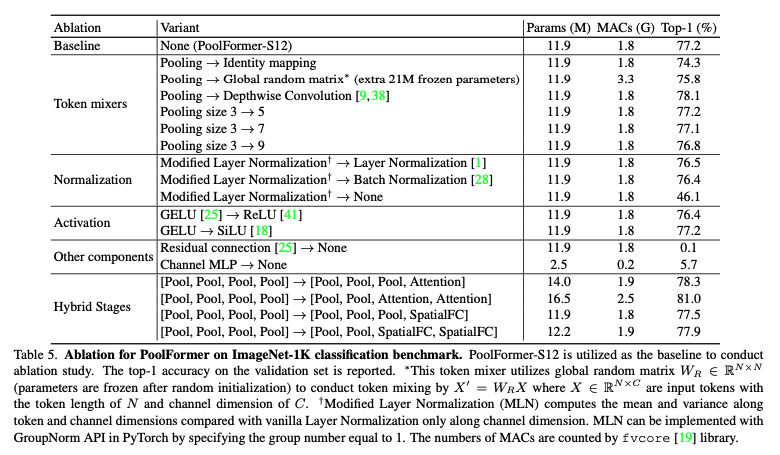
이 논문을 읽으며 물론 metaformer라는 architecture적으로 transformer의 성능을 이끌어낼 수 있다라는 점이 흥미로운 점은 맞지만, 나는 ablation study가 많은 것을 내포하고 있다고 생각한다.
먼저, token mixer 부분에 Identity mapping을 넣었을 때의 결과도 74.3으로 낮지 않은 수준의 성능을 보인다. 이는 metaformer라는 구조 자체가 기본적으로 성능이 잘 나온다라고 해석하는 것 보다 모델에서 lower boundary 역할을 충실히 해준다고 본인은 생각한다.
또한 Hybrid Stages에서 마지막 1~2 layer에 attention을 넣은 실험을 하였을 때 성능이 올라갔다는 것이다. 이 논문의 후속 논문으로 리뷰할 논문에서도 언급할 예정이지만, 마지막 부분에 attention을 넣었을 때 성능이 잘 나오는 것이, 초기 low level에서부터 attention으로 연관성을 계산하는 것보다 convolution, pooling으로 low level의 계산을 한 뒤 global하게 attention을 하는 것이 성능이 좋다라고 본인은 해석하였다.
