Transformer example
Query, Key, Value
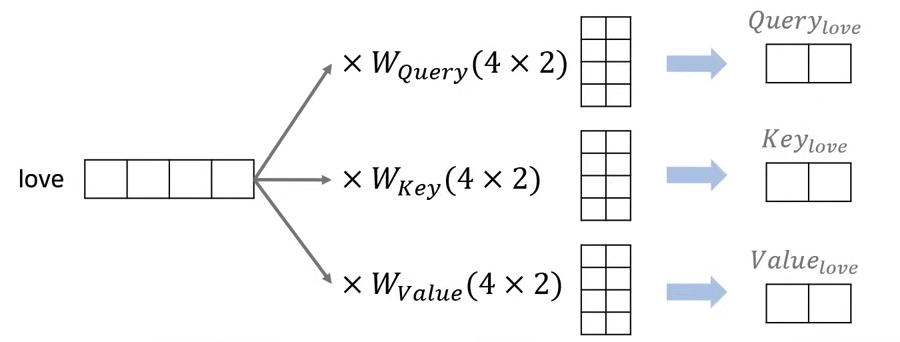
- example sentence : I love you
- attention을 위해 Query, Key, Value 값을 생성
- 각 단어의 Embedding을 이용하여 생성할 수 있다.
- embedding dimension()
- Query, Key, Value dimension()
- 예시의 경우, embedding dimension = 4, h = 2라고 가정을 하고 진행한다. 즉, Q, K, V는 4/2 = 2의 dimension을 가져야한다.
- Q, K, V가 2의 dimension을 가지기 위하여 Weight matrix가 사용된다. 이후 embedding vector와 Weight matrix의 행렬곱을 통해 2 dimension matrix의 Q, K, V를 생성하게 된다.
- 원본 논문의 경우 embedding dimension = 512로 설정하였고, 만일 h = 8인 경우 Q, K, V는 각각 512/8 = 64의 차원을 가지게 된다.
Scaled Dot-Product Attention
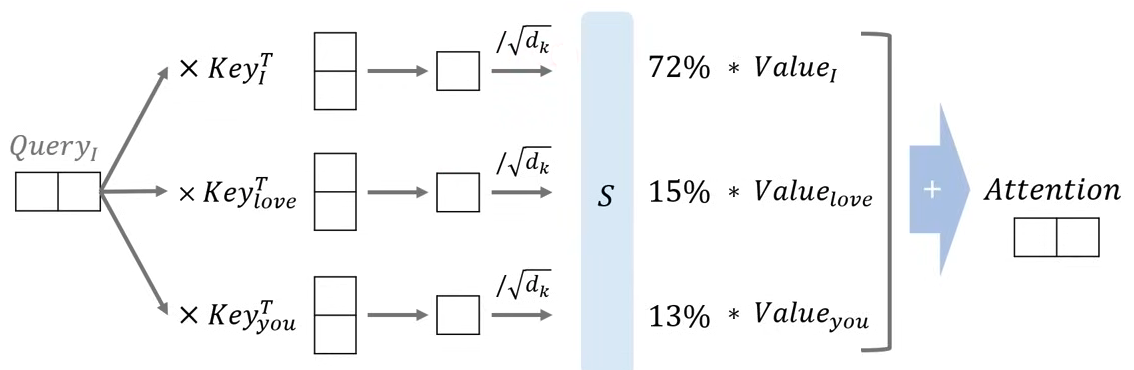
- 문장에서 index의 단어(I) Query 행렬과 문장의 모든 단어(I, love, you) Key의 행렬곱 연산을 통해 하나의 attention energy 값을 구한다.
- 구해진 attention energy 값을 scaling factor로 나눠준 뒤 softmax를 통해 가중치 값(확률 값)으로 변환한다.
- 각 가중치 값(확률 값)에 모든 단어의 Value를 각각 곱한 뒤 더해서 Attention value를 구한다.
Attention - Matrix
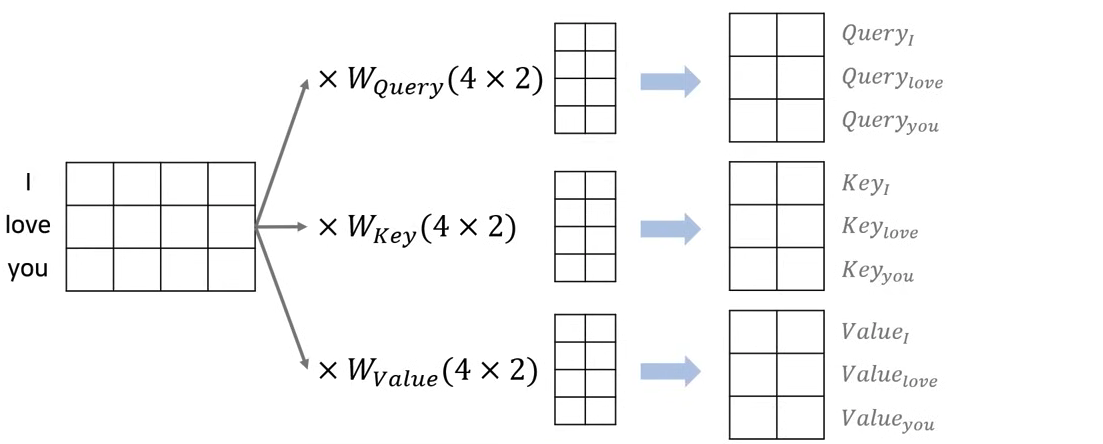
- 실제 문장이 I love you로 들어왔을 때 전체 문장에 대한 matrix로 계산한다.
- 동일하게 embedding dimension = 4, h = 2로 지정했을 때, Q, K, V의 weight matrix는 행렬곱 연산을 위해 4X2 matrix가 될 것이다.
- 행렬곱을 진행하면 3X2 Q, K, V matrix가 계산된다.
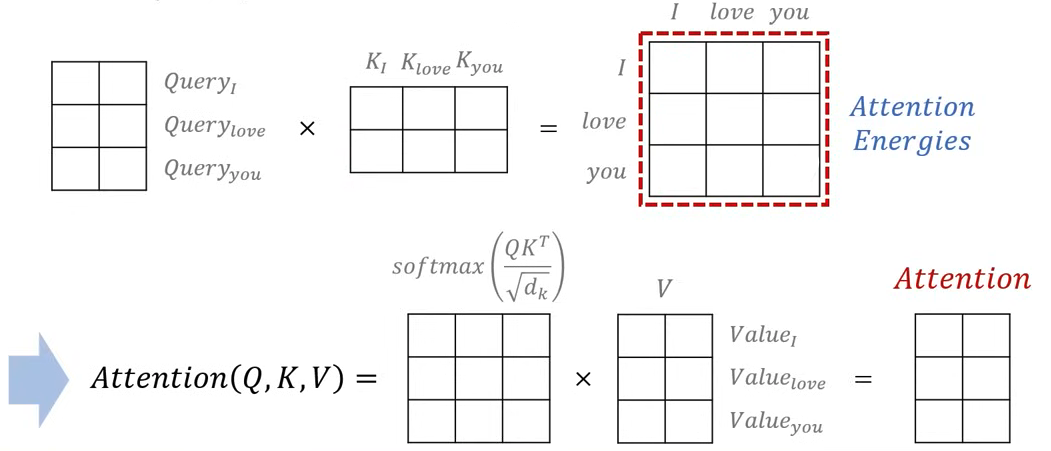
- 이 후, Query matrix와 Key matrix의 transpose를 행렬곱을 진행하여 Attention Energy matrix를 계산한다.
- Attention Energy matrix의 shape(행, 열 수)은 문장의 단어의 개수와 동일한 크기를 가지게 된다. 각 단어가 서로 얼마나 연관이 있는지를 나타낸다.
- 이를 scaling factor를 통해 값을 조정해주고, softmax를 취하여 가중치 값으로 변환한 뒤 Value matrix와 행렬곱을 진행하여 Attention value를 계산한다.
- Attention value matrix는 Q, K, V와 동일한 차원의 matrix를 가지게 된다.
Mask matrix

- Mask matrix를 이용하여 특정 단어를 무시할 수 있다.
- Attention energy matrix와 같은 차원의 mask matrix를 생성하여 element wise로 곱하여 처리한다.
- mask value로 -inf 값을 넣어 softmax 함수의 출력이 0에 가까워지도록 하여 단어를 무시한다.
Multi-Head Attention
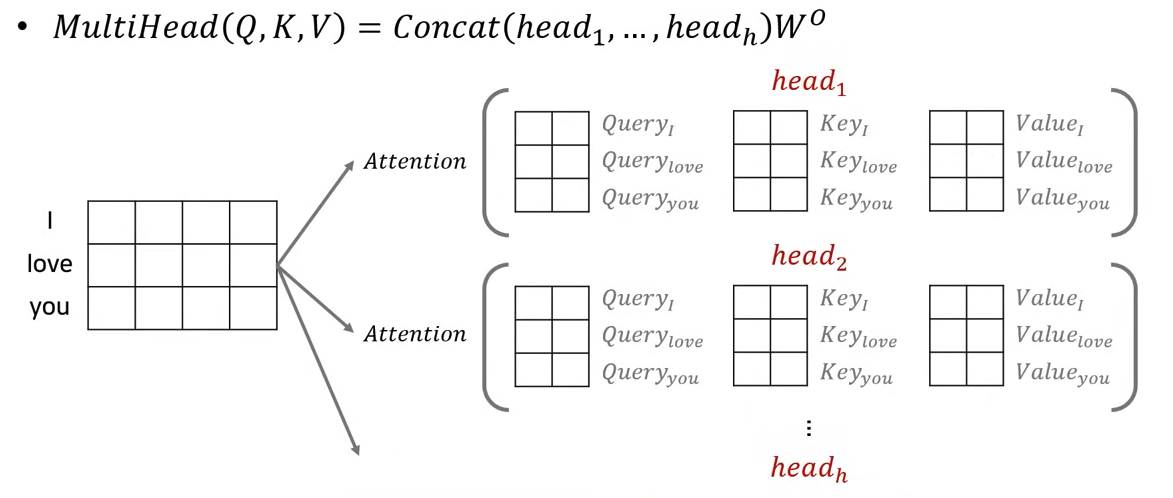
- head의 수(h)만큼 위의 과정들을 진행하여 각 head별 출력 결과를 뽑는다. 진행하던 예시의 경우 h = 2이므로, 각 head별로 3X2 attention matrix가 2개 만들어진다.
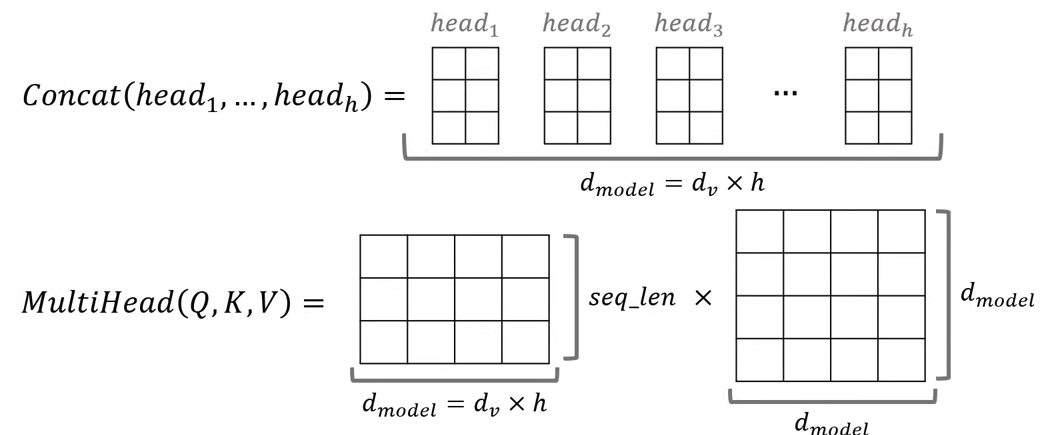
- 계산된 h개의 matrix를 concat하여 다시 input dimension과 동일하게 3X4 matrix를 만들게 된다.
- 즉, Multi-Head Attention을 수행한 뒤에도 차원(dimension)이 동일하게 유지된다.
Positional Encoding
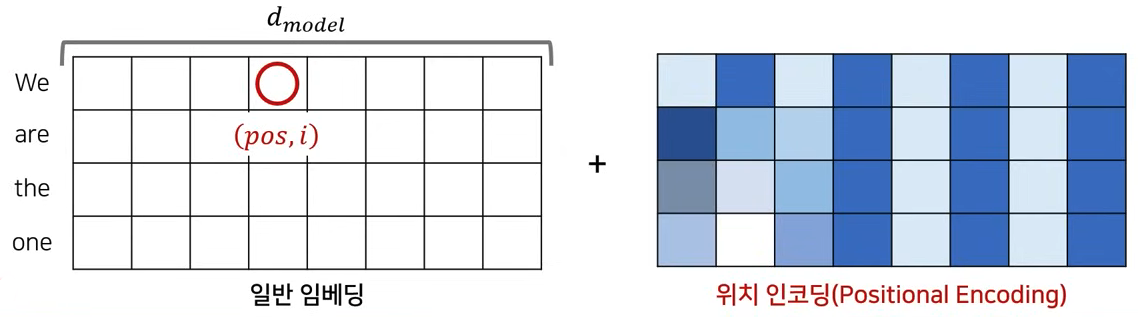
- example : We are the one
- embedding dimension : 8이라고 가정
- pos, i 값은 embedding vector의 위치와 동일하다.
- 값을 element wise sum을 진행하고, 이를 input으로 사용한다.

한양대학교 인공지능학과 대학원생 조권휘입니다.