Today I Learned
AI 공부 계속!
데이터 전처리(Preprocessin)
머신러닝 모델에 데이터를 입력하기 위해 데이터를 처리하는 과정
- EDA, 모델, 목적에 따라 데이터 전처리 방식이 달라진다.
연속형 변수 처리
출처 : @oni
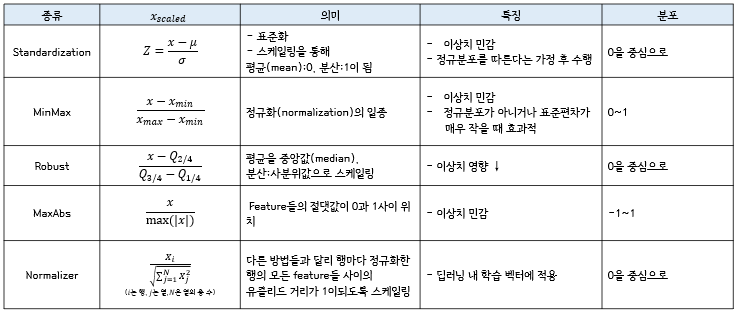
Scaling
데이터 단위 혹은 분포를 변경하는 작업
-
선형회귀, 딥러닝 등의 선형기반 모델은 변수들 간의 스케일을 맞추는 것이 필수적이다.
-
Scale : 단순히 값의 스케일만 바꾼 경우
- Min-Max Scaling : 현재값을 min으로 빼고 (max-min)으로 나눔
- Standard Scaling : 현재값을 평균으로 빼고 표준편차로 나눔
- Robust Scaling : 현재값을 중위값으로 빼고 iqr(75-25)로 나눔. 이상치에 영향을 덜 받음
- Scaling + Distribution : 스케일과 분포 모두 바꾼 경우
- Log transformation
변수가 왼쪽에 많이 치우쳐져 오른 꼬리가 길게 있을 때 로그(자연로그나 상용로그)를 씌우면 정규분포와 비슷하게 된다. - Quantile transformation
데이터의 값을 순서대로 정렬한 후 각 값에 해당하는 백분위수를 계산하고, 이를 특정한 분포(ex.정규 분포)에 해당하는 백분위수와 매핑하여 값을 변환하는 방법
-
Binning : 연속형 변수를 범주형 변수로 바꾸는 방법
데이터를 단순화해주고 overfitting(과적합)을 방지해준다. -
overfitting(과적합) : 모델이 훈련 데이터에 과도하게 학습되어서 훈련 데이터에 대해서는 높은 성능을 보이지만, 새로운 데이터에 대해서는 성능이 저하되는 것
범주형 변수 처리
범주형 변수는 일종의 카테고리(ex.식물의 종, 차종)를 가진 변수로 연속형 보다 더 주의가 필요하다.
Encoding
범주형 변수는 보통 문자열로 되어있어 머신러닝 모델의 입력 데이터로 사용할 수 없어 수치화 시켜주는
Encoding작업이 필요하다.
-
One Hot Encoding
변수를 1과 0의 이진형으로 나누는 가장 일반적인 방법. 값이 존재할 때는 1 아니면 0.
단순하기 때문에 변수의 종이 많으면 컬럼이 많아져서 적용하기 힘들다. -
Label Encoding
각 카테고리에 숫자를 할당하는 방법(ex. 개 1, 고양이 2, 새 3, ...). 하나의 컬럼으로 모든 범주를 표현할 수 있다. 숫자의 크기에 대한 의미를 부여하기 때문에 카테고리 간의 순서가 있는 경우에만 사용해야하며, 아니면 모델이 의미를 잘 못 학습할 수 있다. -
Frequency Encoding
각 카테고리의 등장 빈도로 카테고리를 인코딩한다. 빈도가 높은 카테고리는 높은 값을 갖는다. -
Target Encoding
각 카테고리의 평균 타깃 값으로 카테고리를 인코딩한다. 목표 변수와의 관계를 나타내는 특성을 인코딩에 포함시키기 때문에 예측 모델에서 유용하다. 하지만 미래의 새로 등장한 종은 인코딩이 불가하고, 서로 다른 범주인데 같은 값을 가질 수 있는 단점이 있다. overfitting의 문제도 생길 수 있다.
- 1,2번은 인코딩한 값이 의미가 없지만 3,4번은 의미를 가진다.
- Embedding
범주형 변수를 고차원의 실수형 벡터 공간으로 매핑하는 기술
ex. Word2Vec
본 포스트의 학습 내용은 부스트클래스 <AI 엔지니어 기초 다지기 : 부스트캠프 AI Tech 준비과정> 강의 내용을 바탕으로 작성되었습니다.
