Today I Learned
AI 공부 오늘은 머신러닝!
머신러닝
Fit
데이터를 잘 설명할 수 있는 능력
-
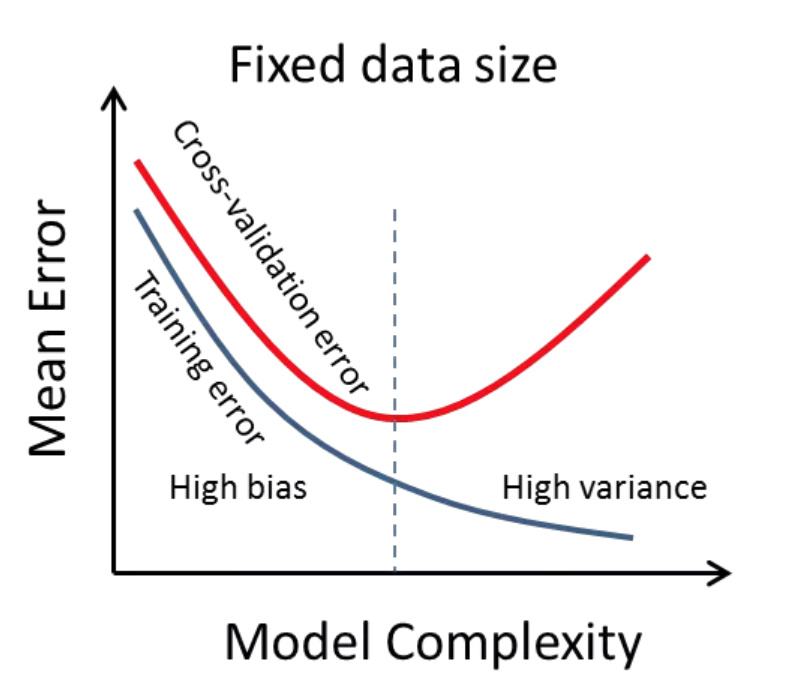
Underfitting : 데이터를 잘 설명하지 못함
-
Underfitting 방지 방법
- 더 많은 데이터로 더 오래 훈련
- 더 많은 피쳐
- variance가 더 높은 모델 선택
-
Overfitting : 데이터를 과하게 설명함. 확보한 데이터 셋과 전체 데이터 셋이 같으면 overfitting이 best이지만 거의 모든 경우 그렇지 않다.
-
일반적으로 확보한 데이터 셋은 전체의 일부분 샘플일 뿐이다. 따라서 확보한 모든 데이터 셋을 overfitting하면 오히려 전체 데이터 셋에 맞지 않을 가능성이 높다.
- overfitting 방지 방법
- 더 많은 데이터로 오래 훈련
- Regularization : 모델의 복잡성을 제어하여 과적합을 방지하는 방법
모델이 노이즈 데이터에 민간하게 반응하지 않게 규제하는 방법
Regularization
-
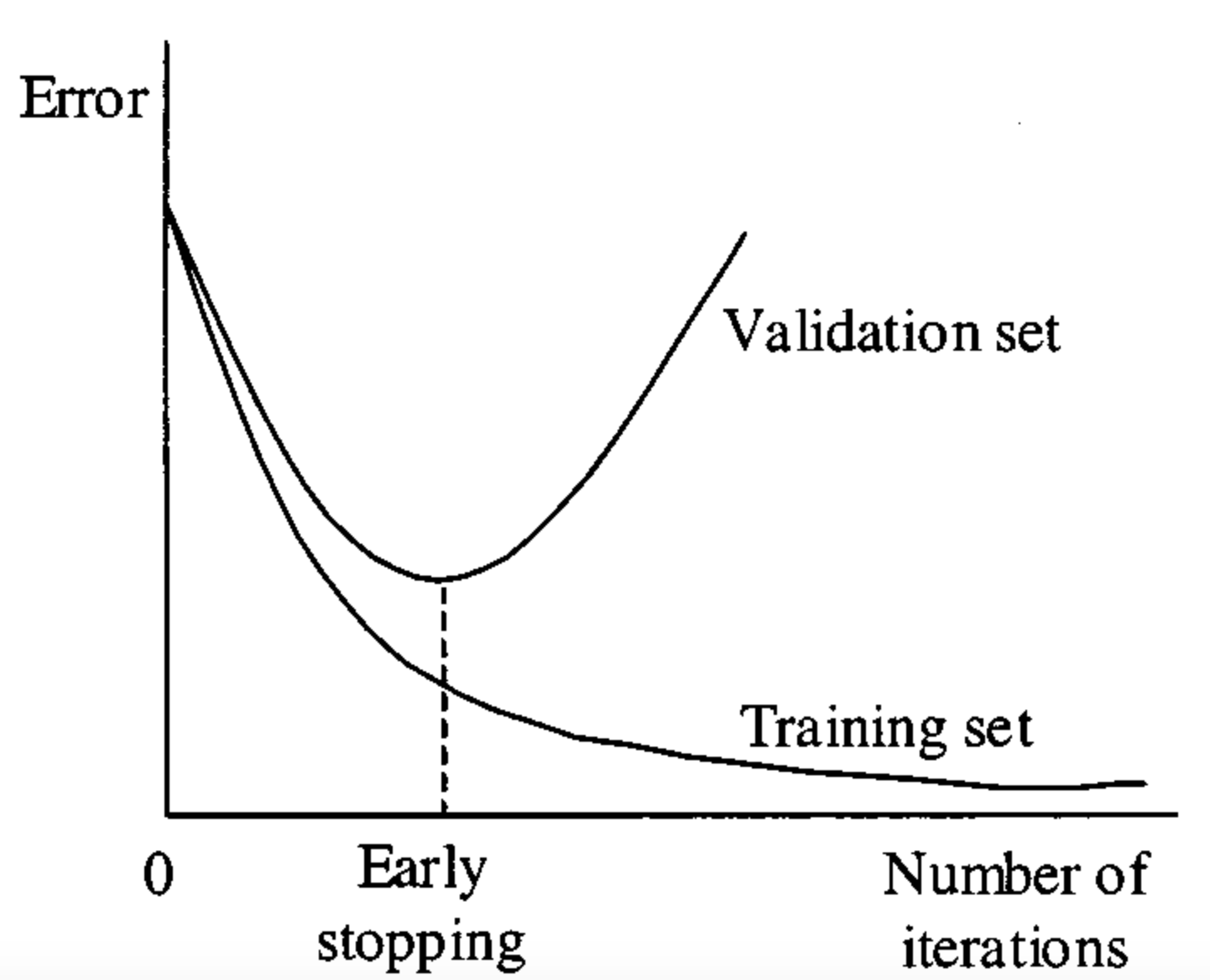
Early Stopping
validation error가 지속적으로 증가하기 전 적정선에서 멈추는 것
-
parameter norm penalty
모델의 가중치나 계수의 크기를 제한하여 모델의 복잡성을 제어하는 방법
L1 Norm Penalty는 가중치의 절댓값 합을 추가하는 방법이고
L2 Norm Penalty는 가중치의 제곱 합을 추가하는 것으로 가중치를 제한하여 모든 가중치가 비슷한 크기를 갖도록 해서 규제한다. -
Data augmentation
데이터 증강. 학습 데이터의 다양성을 높이기 위해 사용되는 기법으로 충분한 양의 데이터가 확보되지 않은 상황에서 기존 데이터를 변형(회전, 이동, 혼합, 크기조절, 노이즈 추가 등)하여 새로운 데이터를 생성함으로써 모델의 일반화 성능을 높이는 방법. 주로 이미지에 사용 -
SMOTE
불균형한 데이터셋에서 소수 클래스의 샘플 수를 늘리기 위한 오버샘플링 기법이다. 불균형한 데이터셋에서 훈련할 경우 소수의 데이터는 제대로 예측하지 못하는 경우가 있기 때문에 이를 보정하기 위해 소수 클래스의 샘플을 생성해 균형을 맞추는 방법이다. -
Dropout
학습 과정 중에 신경망의 일부 뉴런을 무작위로 제거(비활성화)함으로써 모델을 강제로 희소화하는 방법이다. Dropout을 적용하면 신경망이 특정 뉴런에 과도하게 의존하지 않고 여러 뉴런을 사용하여 다양한 특징을 학습할 수 있다.
트리모델에서 적용하면 하나의 모델을 생성할 때 모든 컬럼을 쓰지않고 랜덤하게 컬럼을 샘플링해 구현한다.
Machine Learning Workflow
- raw data에서 필요한 data를 추출한다.
- Data preprocess(데이터 전처리), Feature Engineering, Feature Scaling, Feature Selection을 진행한다.
- 머신러닝 알고리즘으로 modeling한다.
- 성능 평가(evaluation)를 진행해 원하는 결과가 나올때까지 2~4를 진행한다.
- 최종 목표한 성능이 나오면 배포한다.
본 포스트의 학습 내용은 부스트클래스 <AI 엔지니어 기초 다지기 : 부스트캠프 AI Tech 준비과정> 강의 내용을 바탕으로 작성되었습니다.
